SPSS Clementine 数据挖掘入门3
但SQL Server 2005使用Visual Studio 2005作为客户端开发工具,Visual Studio的SSAS项目只能作为模型设计和部署工具而已,根本不能独立实现完整的Crisp-DM流程。尽管MS Excel也可以作为SSAS的客户端实现数据挖掘,不过Excel显然不是为专业数据挖掘人员设计的。
PS:既然说到Visual Studio,我又忍不住要发牢骚。大家都知道Visual Studio Team System是一套非常棒的团队开发工具,它为团队中不同的角色提供不同的开发模板,并且还有一个服务端组件,通过这套工具实现了团队协作、项目管理、版本控制等功能。SQL Server 2005相比2000的变化之一就是将开发客户端整合到了Visual Studio中,但是这种整合做得并不彻底。比如说,使用SSIS开发是往往要一个人完成一个独立的包,比起DataStage基于角色提供了四种客户端,VS很难实现元数据、项目管理、并行开发……;现在对比Clementine也是,Clementine最吸引人的地方就是其提供了强大的客户端。当然,Visual Studio本身是很好的工具,只不过是微软没有好好利用而已,期望未来的SQL Server 2K8和Visual Studio 2K8能进一步改进。

所以我们不由得想到如果能在SPSS Clementine中实现Crisp-DM过程,但是将模型部署到SSAS就好了。
首先OLE DB for DM包括了Model_PMML结构行集,可以使用DMX语句“Create Mining Model <Model Name> From PMML <xml string>”将SPSS Clementine导出的PMML模型加入SSAS。
如果我记得没错的话,SQL Server 2005 最初发表版本中Analysis Services是PMML 2.1标准,而Clementine 11是PMML 3.1的,两者的兼容性不知怎样,我试着将一个PMML文件加入SSAS,结果提示错误。
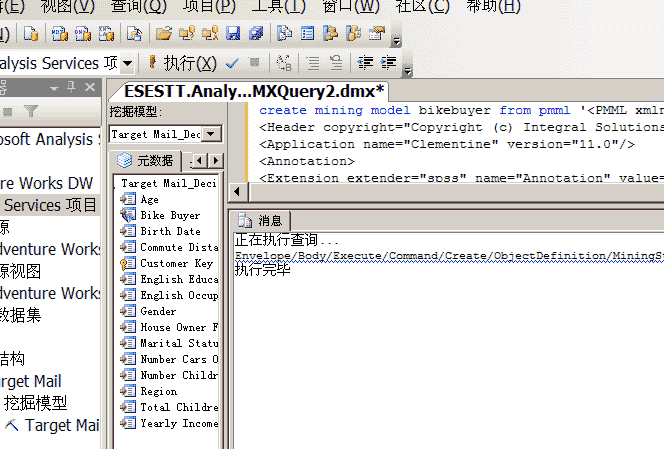
另外,在SPSS Clementine中可以整合SSAS,通过使用SSAS的算法,将模型部署到SSAS。具体的做法是:
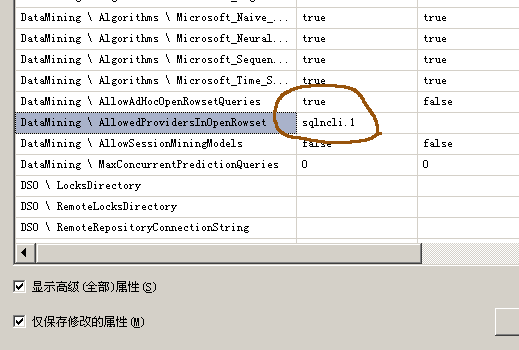
在SSAS实例中修改两个属性值。
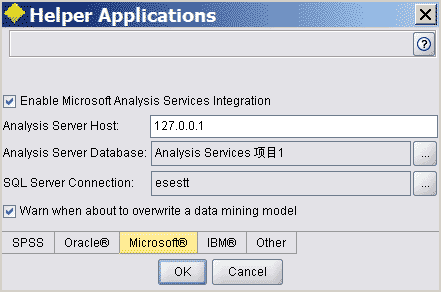
在Clementine菜单栏选Tools -> Helper Applications。

然后启用SSAS整合,需要选择SSAS数据库和SQL Server RMDBS,RMDBS是用来存储临时数据的,如果在Clementine的流中使用了SAS数据源,但SSAS不支持SAS数据文件,那么Clementine需要将数据源存入临时数据表中以便SSAS能够使用。
启用整合后,就可以在工具栏中看到多出了一类Datebase Modeling组件,这些都是SSAS的数据挖掘算法,接下来的就不用说了……

可惜的是SSAS企业版中就带有9中算法,另外还有大量第三方的插件,但Clementine 11.0中只提供了7种SSAS挖掘模型。
SPSS Clementine 数据挖掘入门3的更多相关文章
- SPSS Clementine 数据挖掘入门1
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具.在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS.SAS获得了最高ability to e ...
- SPSS Clementine 数据挖掘入门2
下面使用Adventure Works数据库中的Target Mail作例子,通过建立分类树和神经网络模型,决策树用来预测哪些人会响应促销,神经网络用来预测年收入. Target Mail数据在SQL ...
- SPSS Modeler数据挖掘项目实战(数据挖掘、建模技术)
SPSS Modeler是业界极为著名的数据挖掘软件,其前身为SPSS Clementine.SPSS Modeler内置丰富的数据挖掘模型,以其强大的挖掘功能和友好的操作习惯,深受用户的喜爱和好评, ...
- SPSS Modeler数据挖掘:回归分析
SPSS Modeler数据挖掘:回归分析 1 模型定义 回归分析法是最基本的数据分析方法,回归预测就是利用回归分析方法,根据一个或一组自变量的变动情况预测与其相关的某随机变量的未来值. 回归分析是研 ...
- 数据挖掘入门系列教程(二)之分类问题OneR算法
数据挖掘入门系列教程(二)之分类问题OneR算法 数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html 项目地址:G ...
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例) 简介 scikit-learn 估计器 加载数据集 进行fit训练 设置参数 预处理 流水线 结尾 数据挖掘入门系 ...
- 数据挖掘入门系列教程(四)之基于scikit-lean实现决策树
目录 数据挖掘入门系列教程(四)之基于scikit-lean决策树处理Iris 加载数据集 数据特征 训练 随机森林 调参工程师 结尾 数据挖掘入门系列教程(四)之基于scikit-lean决策树处理 ...
- 数据挖掘入门系列教程(四点五)之Apriori算法
目录 数据挖掘入门系列教程(四点五)之Apriori算法 频繁(项集)数据的评判标准 Apriori 算法流程 结尾 数据挖掘入门系列教程(四点五)之Apriori算法 Apriori(先验)算法关联 ...
- 数据挖掘入门系列教程(五)之Apriori算法Python实现
数据挖掘入门系列教程(五)之Apriori算法Python实现 加载数据集 获得训练集 频繁项的生成 生成规则 获得support 获得confidence 获得Lift 进行验证 总结 参考 数据挖 ...
随机推荐
- 面试题12:打印1到最大的n位数(大数问题)
面试题是关于n位整数并且没有限定n的取值范围,或者是输入任意大小的整数,那么这个题目就很可能需要考虑大数问题.字符串是一个简单的.有效的表示大数的方法 这题比较难,用递归表达全排列,数字每一位都可能是 ...
- 浅谈ES5和ES6继承和区别
最近想在重新学下ES6,所以就把自己学到的,记录下加强下自己的理解 首先先简单的聊下ES5和ES6中的继承 1.在es5中的继承: function parent(a,b){ this a = a; ...
- 【LOJ】 #2521. 「FJOI2018」领导集团问题
题解 这道题很显然可以想出来一个\(n^2\)的dp,也就是dp[u][i]表示以u为根的子树最大值是i的点集最大是多少(i是离散化后的值) 就是对于每个儿子处理出后缀最大值然后按位相加更新父亲,我们 ...
- php、mysql编译配置
与apache一起使用: Configure Command => './configure' '--prefix=/home/sujunjie/local/php' '--with-apx ...
- Python基本语法[二]
Python基本语法 1.定义变量: 代码正文: x= y= z=x+y 代码讲解: 2.判断语句: 代码正文: score= : print("你真棒") print(&qu ...
- Redis实战配置(三)
程序配置 我们安装好了Redis的系统服务,此时Redis服务已经运行. 现在我们需要让我们的程序能正确读取到Redis服务地址等一系列的配置信息,首先,需要在Web.config文件中添加如下信息: ...
- jenkins pipelines 简介
1. 简介:A pipeline就是软件和质量保证进程中的一部分中的自动化连续操作.它可以看成是一连串的脚本. 操作组:就是把一系统的操作可以合成一个个的步骤,如果一个步骤失败,那么后续步骤便不会执行 ...
- ZOJ 3957 Knuth-Morris-Pratt Algorithm
暴力. #include<bits/stdc++.h> using namespace std; ]; int main() { int T; scanf("%d",& ...
- Redis学习篇(八)之连接相关
PING 测试客户端和服务器之间的连接是否有效,有效返回PONG ECHO 打印特定的信息, 如: ECHO 'HELLO WORLD' QUIT/EXIT 断开当前客户端与服务器之间的连接,可以重连 ...
- SpringBoot 解决时区问题
SpringBoot 解决时区问题 1.在启动类加上 @PostConstruct void setDefaultTimezone() { TimeZone.setDefault(TimeZone.g ...