scala(一)方法&函数
写在前面
众所周知,scala一向宣称自己是面向函数的编程,(java表示不服,我是面向bean的编程!)那什么是函数?
在接触java的时候,有时候用函数来称呼某个method(实在找不出词了),有时候用方法来称呼某个method,虽然method的中文翻译就是“方法”,但对于java来说,方法和函数是等价的,或者说没有函数这个概念。
而对于scala,这两者似乎有一个较为明确的边界。
你会发现满世界的函数,而你却在写方法
Scala 方法&函数
方法
Scala的方法和java可以看成是一样的,只是多了点语法糖。
比如无参方法在申明时可以不加括号,甚至在调用过程也不用加括号
def f = 1+1
println(f)
比如方法可以添加泛型规则,这在java中只能在类申明
def f[T](t: T) = {t}
还有其它很多细节语法,遇到才深入吧
一般而言只要知道函数的结构就行(但是我想说,spark的代码就没有一个函数长成这样的啊..),请忽略下图的“函数”字样,其实就是方法
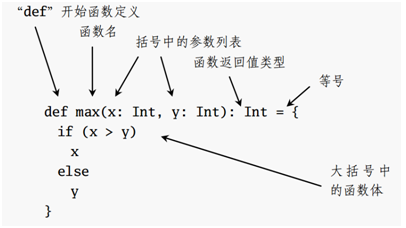
方法应用
def method(): Unit ={
//本地方法
def print(str:String): Unit ={
println(str)
}
print("hello")
}
方法的语法还是跟java差不多的,只是有些可以省略而已。
比较重要的就是本地方法,即方法中嵌套方法
函数
Scala的函数是基于Function家族,0-22,一共23个Function Trait可以被使用,数字代表了Funtcion的入参个数
函数语法
下面这四个函数的意义是一样的
// println(fun1)
// println(fun2)
// println(fun3)
// println(fun4)
// 都为<function2>
val fun1 = new Function2[Int,Int,Int]() {
override def apply(v1: Int, v2: Int): Int = {
v1+v2
}
} val fun2 = new ((Int, Int) => Int)() {
override def apply(v1: Int, v2: Int): Int = {
v1+v2
}
} val fun3 = (v1:Int,v2:Int) => v1+v2 // _可以把method转换成function
val fun4 = fun4Method _
def fun4Method(v1:Int,v2:Int): Int = {
v1+v2
}
一般我们都采用第三种fun3定义方式,也是最难懂的一个定义方式。具体结构参考下图

那函数有什么用呢?
Java里只有方法都能适应一切需求,那scala又提出函数的概念肯定有意义。
1.函数可以直接赋值给变量,可以让函数很方便的传递
2.闭包(closure),可以把灵活操作代码块,从而引申出其他灵活的语法
函数应用
在spark中,有很多方法入参中使用函数的场景,比如如下函数
defrunJob[T,U](fun: Iterator[T] => U ,resHandler: (Int, U) => Unit): Unit ={
//忽略里面的逻辑
}
其中的fun和resHandler都是函数
Fun是入参为Iterator[T],返回值为U的函数,一个入参的函数其实就是Function1的实例
resHandler是入参为Int和 U无返回值的函数,二个入参的函数其实就是Function2
模拟spark中常见的一段代码语法,拿一个普通scala类型的例子来说
//模拟spark的runJob方法
def runJob[T,U](fun: Iterator[T] => U ,resHandler: (Int, U) => Unit): Unit ={
val listBuffer = new ListBuffer[T]
listBuffer.append("h".asInstanceOf[T])
listBuffer.append("e".asInstanceOf[T])
listBuffer.append("l".asInstanceOf[T])
listBuffer.append("l".asInstanceOf[T])
listBuffer.append("o".asInstanceOf[T])
//这里调用函数其实用到了伴生对象的概念,fun(xxx)就是fun.apply(xxx)
val res = fun(listBuffer.iterator)
//spark中,这里是每个partition的数据都存入arr,这里做模拟就一个partition了:)
resHandler(0,res)
} //模拟调用runJob的方法
def main(args: Array[String]): Unit = {
val arr = new Array[String](1)
//fun函数的实际逻辑
val fun = (it:Iterator[String]) => {
val sb = new StringBuilder()
while (it.hasNext)
sb.append(it.next())
sb.toString()
} //resHandler函数的实际逻辑
val resHandler = (i:Int,res:String) => arr(i) = res
runJob[String,String](fun ,resHandler)
println(arr.mkString(""))
}
其实就是传递函数的逻辑,和java的匿名类差不多(只有一个方法的匿名类),只是多了点语法糖
这么做的好处也是不言而喻的
1.可以构造出更抽象的方法,使得代码结构更简洁
2.spark的思想就是lazy,而函数传递也是一个lazy的过程,只有在实际触发才会执行
偏函数
英文为PartialFunction,不知道这么翻译对不对,貌似都这么叫。
PartialFunction其实是Funtion1的子类
参考源码
trait PartialFunction[-A, +B] extends (A => B)
A => B就是标准的函数结构
那PartialFunction有什么作用呢?
模式匹配!
PartialFunction最重要的两个方法,一个是实际的操作逻辑,一个是校验,其实就是用来做模式匹配的。
参考资料
《Scala编程》
scala(一)方法&函数的更多相关文章
- 【Scala篇】--Scala中的函数
一.前述 Scala中的函数还是比较重要的,所以本文章把Scala中可能用到的函数列举如下,并做详细说明. 二.具体函数 1.Scala函数的定义 def fun (a: Int , b: Int ) ...
- Scala函数式编程(三) scala集合和函数
前情提要: scala函数式编程(二) scala基础语法介绍 scala函数式编程(二) scala基础语法介绍 前面已经稍微介绍了scala的常用语法以及面向对象的一些简要知识,这次是补充上一章的 ...
- Scala高阶函数与泛型
1. Scala中的函数 在Scala中,函数是“头等公民”,就和数字一样.可以在变量中存放函数,即:将函数作为变量的值(值函数). 2. scala中的匿名函数,即没有函数名称的函数,匿名函数常作为 ...
- scala def方法时等号和括号使用说明笔记
scala定义方法时会指定入参和返回类型(无返回类型时对应Unit,即java和C中的void模式). 1.有入参,有返回类型时,scala具有类型推导功能,以下两种表达方式效果一样.但根据scala ...
- scala编程(八)——函数和闭包
当程序变得庞大时,你需要一些方法把它们分割成更小的,更易管理的片段.为了分割控制流,Scala 提供了所有有经验的程序员都熟悉的方式:把代码分割成函数.实际上,Scala 提供了许多 Java 中没有 ...
- Scala 深入浅出实战经典 第42讲:scala 泛型类,泛型函数,泛型在spark中的广泛应用
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- <经验杂谈>C#中一种最简单、最基本的反射(Reflection):通过反射获取方法函数
说起反射之前和很多用C#/.net的同仁们一样,相比于一般应用层对数据的增删改查总有点觉得深奥到难以理解.其实程序这东西,用过.实践过就很简单,我一直这么认为. 先说下概念:反射 Reflection ...
- Python学习入门基础教程(learning Python)--8.3 字典常用的方法函数介绍
本节的主要讨论内容是有关dict字典的一些常用的方法函数的使用和范例展示. 1. clear清除字典数据 语法结构如下: dict_obj.clear() 示例代码如下: dict1 = {'web' ...
- PHP(方法 函数 循环 和 数组 查找)
循环 和 数组 查找 顺序查找 二分法查找 冒泡排序 方法 函数 定义:一堆代码的集合叫做函数(满足条件下“一堆”) 语法,定义,调用,参数列表(形参,实参),返回值 两种方法: function 方 ...
随机推荐
- 关于ln(link)命令
一. ln分为硬链接和软链接. 二. 硬链接命令为: ln test/a.text hard.text 1. 这样hard.text拥有 test目录下a.text相同的i节点(inode的id号)和 ...
- file结构中的private_data
private_data是Linux下连接VFS文件系统框架和不同文件/文件系统底层实现之间的一个核心数据结构,虽然它只是一个指针,但是一个指针可以解决所有问题. 因 为file是VFS框架的一个基本 ...
- Spring Data Jpa 初探
Spring Data 项目的目的是为了简化构建基于 Spring 框架应用的数据访问计数,包括非关系数据库.Map-Reduce 框架.云数据服务等等;另外也包含对关系数据库的访问支持. 下载网址: ...
- spring data jpa 遇到的问题
org.springframework.core.convert.ConversionFailedException: Failed to convert from type [java.lang.O ...
- linux创建lvm分区
创建LVM分区 shell> fdisk /dev/xvdb #### 选择磁盘 Command (m for help): m #### 帮助 Command action a toggle ...
- npm install命令对package-lock.json文件自动做了一些额外的更新
今天我使用 npm 命令给项目安装file-saver,通过git却发现package-lock.json中除了file-saver组件之外的其他组件的记录也被改了 npm为何会自动做这些更改呢,又如 ...
- 安全篇:弱密码python检测工具
安全篇:弱密码python检测工具 https://github.com/penoxcn/PyWeakPwdAudit
- 使用Django和Python创建Json response
版权声明:本文为博主原创文章,欢迎转载. https://blog.csdn.net/fengyu09/article/details/30785101 使用jquery的.post提交,并期望得到多 ...
- Linux 远程复制
一.将本机文件复制到远程服务器上 #scp /usr/local/kafka_2.11-0.11.0.0/config/server.properties app@172.25.6.11:/haha ...
- 跟我学Makefile(一)
1.首先,把源文件编译生成中间代码文件,Windows下.obj文件,unix下.o文件,即Object File.这个动作叫编译(compile) 把大量的Object File合并执行文件,叫做链 ...