Tensorflow实现学习率衰减
Tensorflow实现各种学习率衰减
觉得有用的话,欢迎一起讨论相互学习~




学习率衰减(learning rate decay)
- 加快学习算法的一个办法就是随时间慢慢减少学习率,我们将之称为学习率衰减(learning rate decay)
概括
- 假设你要使用mini-batch梯度下降法,mini-batch数量不大,大概64或者128个样本,但是在迭代过程中会有噪音,下降朝向这里的最小值,但是不会精确的收敛,所以你的算法最后在附近摆动.,并不会真正的收敛.因为你使用的是固定的 \(\alpha\),在不同的mini-batch中有杂音,致使其不能精确的收敛.

- 但如果能慢慢减少学习率 \(\alpha\) 的话,在初期的时候,你的学习率还比较大,能够学习的很快,但是随着 \(\alpha\) 变小,你的步伐也会变慢变小.所以最后的曲线在最小值附近的一小块区域里摆动.所以慢慢减少 \(\alpha\) 的本质在于在学习初期,你能承受较大的步伐, 但当开始收敛的时候,小一些的学习率能让你的步伐小一些.

细节
- 一个epoch表示要遍历一次数据,即就算有多个mini-batch,但是一定要遍历所有数据一次,才叫做一个epoch.
- 学习率 \(\alpha ,其中 \alpha_{0}表示初始学习率, decay-rate是一个新引入的超参数\) :
\]

其他学习率是衰减公式
指数衰减
\]
\]
\]
Tensorflow实现学习率衰减
自适应学习率衰减
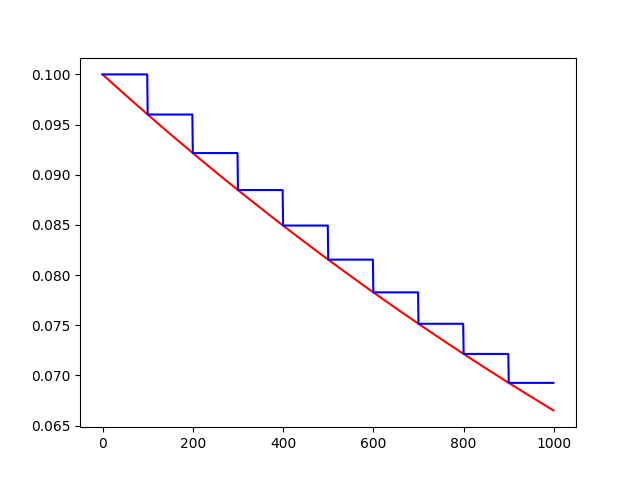
tf.train.exponential_decay(learning_rate, global_step, decay_steps, decay_rate, staircase=False, name=None)
退化学习率,衰减学习率,将指数衰减应用于学习速率。
计算公式:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
# 初始的学习速率是0.1,总的迭代次数是1000次,如果staircase=True,那就表明每decay_steps次计算学习速率变化,更新原始学习速率,
# 如果是False,那就是每一步都更新学习速率。红色表示False,蓝色表示True。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
learning_rate = 0.1 # 初始学习速率时0.1
decay_rate = 0.96 # 衰减率
global_steps = 1000 # 总的迭代次数
decay_steps = 100 # 衰减次数
global_ = tf.Variable(tf.constant(0))
c = tf.train.exponential_decay(learning_rate, global_, decay_steps, decay_rate, staircase=True)
d = tf.train.exponential_decay(learning_rate, global_, decay_steps, decay_rate, staircase=False)
T_C = []
F_D = []
with tf.Session() as sess:
for i in range(global_steps):
T_c = sess.run(c, feed_dict={global_: i})
T_C.append(T_c)
F_d = sess.run(d, feed_dict={global_: i})
F_D.append(F_d)
plt.figure(1)
plt.plot(range(global_steps), F_D, 'r-')# "-"表示折线图,r表示红色,b表示蓝色
plt.plot(range(global_steps), T_C, 'b-')
# 关于函数的值的计算0.96^(3/1000)=0.998
plt.show()
反时限学习率衰减
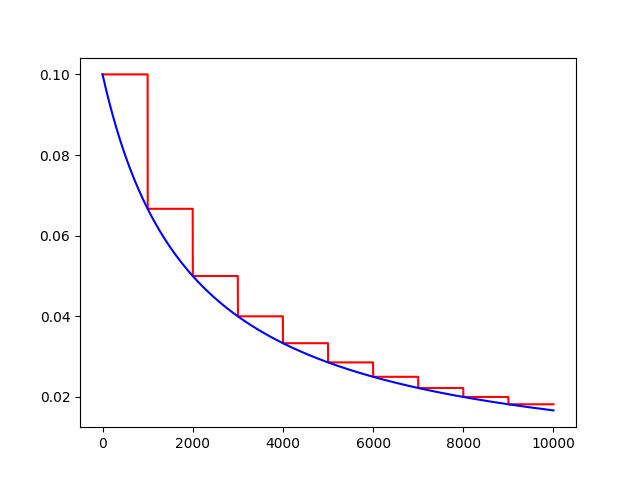
inverse_time_decay(learning_rate, global_step, decay_steps, decay_rate,staircase=False,name=None)
将反时限衰减应用到初始学习率。
计算公式:
decayed_learning_rate = learning_rate / (1 + decay_rate * t)
import tensorflow as tf
import matplotlib.pyplot as plt
global_ = tf.Variable(tf.constant(0), trainable=False)
globalstep = 10000 # 全局下降步数
learning_rate = 0.1 # 初始学习率
decaystep = 1000 # 实现衰减的频率
decay_rate = 0.5 # 衰减率
t = tf.train.inverse_time_decay(learning_rate, global_, decaystep, decay_rate, staircase=True)
f = tf.train.inverse_time_decay(learning_rate, global_, decaystep, decay_rate, staircase=False)
T = []
F = []
with tf.Session() as sess:
for i in range(globalstep):
t_ = sess.run(t, feed_dict={global_: i})
T.append(t_)
f_ = sess.run(f, feed_dict={global_: i})
F.append(f_)
plt.figure(1)
plt.plot(range(globalstep), T, 'r-')
plt.plot(range(globalstep), F, 'b-')
plt.show()
学习率自然指数衰减
def natural_exp_decay(learning_rate, global_step, decay_steps, decay_rate, staircase=False, name=None)
将自然指数衰减应用于初始学习速率。
计算公式:
decayed_learning_rate = learning_rate * exp(-decay_rate * global_step)
import tensorflow as tf
import matplotlib.pyplot as plt
global_ = tf.Variable(tf.constant(0), trainable=False)
globalstep = 10000 # 全局下降步数
learning_rate = 0.1 # 初始学习率
decaystep = 1000 # 实现衰减的频率
decay_rate = 0.5 # 衰减率
t = tf.train.natural_exp_decay(learning_rate, global_, decaystep, decay_rate, staircase=True)
f = tf.train.natural_exp_decay(learning_rate, global_, decaystep, decay_rate, staircase=False)
T = []
F = []
with tf.Session() as sess:
for i in range(globalstep):
t_ = sess.run(t, feed_dict={global_: i})
T.append(t_)
f_ = sess.run(f, feed_dict={global_: i})
F.append(f_)
plt.figure(1)
plt.plot(range(globalstep), T, 'r-')
plt.plot(range(globalstep), F, 'b-')
plt.show()

常数分片学习率衰减
piecewise_constant(x, boundaries, values, name=None)
例如前1W轮迭代使用1.0作为学习率,1W轮到1.1W轮使用0.5作为学习率,以后使用0.1作为学习率。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 当global_取不同的值时learning_rate的变化,所以我们把global_
global_ = tf.Variable(tf.constant(0), trainable=False)
boundaries = [10000, 12000]
values = [1.0, 0.5, 0.1]
learning_rate = tf.train.piecewise_constant(global_, boundaries, values)
global_steps = 20000
T_L = []
with tf.Session() as sess:
for i in range(global_steps):
T_l = sess.run(learning_rate, feed_dict={global_: i})
T_L.append(T_l)
plt.figure(1)
plt.plot(range(global_steps), T_L, 'r-')
plt.show()

多项式学习率衰减
特点是确定结束的学习率。
polynomial_decay(learning_rate, global_step, decay_steps,end_learning_rate=0.0001, power=1.0,cycle=False, name=None):
通常观察到,通过仔细选择的变化程度的单调递减的学习率会产生更好的表现模型。此函数将多项式衰减应用于学习率的初始值。
使学习率learning_rate在给定的decay_steps中达到end_learning_rate。它需要一个global_step值来计算衰减的学习速率。你可以传递一个TensorFlow变量,在每个训练步骤中增加global_step = min(global_step, decay_steps)
计算公式:
decayed_learning_rate = (learning_rate - end_learning_rate) *(1 - global_step / decay_steps) ^ (power) + end_learning_rate
如果cycle为True,则使用decay_steps的倍数,第一个大于'global_steps`.ceil表示向上取整.
decay_steps = decay_steps * ceil(global_step / decay_steps)
decayed_learning_rate = (learning_rate - end_learning_rate) *(1 - global_step / decay_steps) ^ (power) + end_learning_rate
Example: decay from 0.1 to 0.01 in 10000 steps using sqrt (i.e. power=0.5):'''
import tensorflow as tf
import matplotlib.pyplot as plt
global_ = tf.Variable(tf.constant(0), trainable=False)
starter_learning_rate = 0.1 # 初始学习率
end_learning_rate = 0.01 # 结束学习率
decay_steps = 1000
globalstep = 10000
f = tf.train.polynomial_decay(starter_learning_rate, global_, decay_steps, end_learning_rate, power=0.5, cycle=False)
t = tf.train.polynomial_decay(starter_learning_rate, global_, decay_steps, end_learning_rate, power=0.5, cycle=True)
F = []
T = []
with tf.Session() as sess:
for i in range(globalstep):
f_ = sess.run(f, feed_dict={global_: i})
F.append(f_)
t_ = sess.run(t, feed_dict={global_: i})
T.append(t_)
plt.figure(1)
plt.plot(range(globalstep), F, 'r-')
plt.plot(range(globalstep), T, 'b-')
plt.show()

Tensorflow实现学习率衰减的更多相关文章
- TensorFlow之DNN(二):全连接神经网络的加速技巧(Xavier初始化、Adam、Batch Norm、学习率衰减与梯度截断)
在上一篇博客<TensorFlow之DNN(一):构建“裸机版”全连接神经网络>中,我整理了一个用TensorFlow实现的简单全连接神经网络模型,没有运用加速技巧(小批量梯度下降不算哦) ...
- TensorFlow——学习率衰减的使用方法
在TensorFlow的优化器中, 都要设置学习率.学习率是在精度和速度之间找到一个平衡: 学习率太大,训练的速度会有提升,但是结果的精度不够,而且还可能导致不能收敛出现震荡的情况. 学习率太小,精度 ...
- Adam和学习率衰减(learning learning decay)
目录 梯度下降法更新参数 Adam 更新参数 Adam + 学习率衰减 Adam 衰减的学习率 References 本文先介绍一般的梯度下降法是如何更新参数的,然后介绍 Adam 如何更新参数,以及 ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- 吴恩达深度学习笔记(五) —— 优化算法:Mini-Batch GD、Momentum、RMSprop、Adam、学习率衰减
主要内容: 一.Mini-Batch Gradient descent 二.Momentum 四.RMSprop 五.Adam 六.优化算法性能比较 七.学习率衰减 一.Mini-Batch Grad ...
- Dropout和学习率衰减
Dropout 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象.在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上 ...
- ubuntu之路——day8.5 学习率衰减learning rate decay
在mini-batch梯度下降法中,我们曾经说过因为分割了baby batch,所以迭代是有波动而且不能够精确收敛于最小值的 因此如果我们将学习率α逐渐变小,就可以使得在学习率α较大的时候加快模型训练 ...
- [深度学习] pytorch学习笔记(3)(visdom可视化、正则化、动量、学习率衰减、BN)
一.visdom可视化工具 安装:pip install visdom 启动:命令行直接运行visdom 打开WEB:在浏览器使用http://localhost:8097打开visdom界面 二.使 ...
- 权重衰减(weight decay)与学习率衰减(learning rate decay)
本文链接:https://blog.csdn.net/program_developer/article/details/80867468“微信公众号” 1. 权重衰减(weight decay)L2 ...
随机推荐
- Linux 发展史与vm安装linux centos 6.9
操作系统 是一个人与计算机硬件的中介. Linux操作系统 开源代码的.自由传播的类Unix操作系系统软件: 多用户.多任务.多线程.多CPU的操作系统. 服务器端.嵌入式开发.个人pc桌面,服务器领 ...
- MySQL case when 使用
case when 自定义排序时的使用 根据 case when 新的 sort字段排序 case when t2.status = 4 and t2.expire_time>UNIX_TIME ...
- 个人第十一周PSP
11.24 --11.30本周例行报告 1.PSP(personal software process )个人软件过程. 类型 任务 开始时间 结束时间 中断时间 实际用 ...
- DoItYourself!
在杨老师的勉励下,我准备开始“自己”写程序.速度很慢,不过在写的过程中对于用到的几个函数更加熟悉.也尝试多学一点,学透一点.遇到不会的函数,语法不清楚的,还是会百度,不过会自己再敲一遍.重复下去. 下 ...
- our team
今天向大家介绍一下我们的团队,首先我们的团队叫“吉祥三宝”当然我们的三宝不是亲子关系,我们是兄弟关系,对,就是这样 下面来介绍一下我们的团队成团吧: 李奇原: 性格开朗.积极乐观.有责任心,擅长团队协 ...
- ASP.NET MVC5 学习系列之表单和HTML辅助方法
一.表单 (一)Action和Method特性 Action特性用以告知浏览器信息发往何处,因此,Action特性后面需要包含一个Url地址.这里的Url地址可以是相对的,也可以是绝对的.如下Form ...
- hdu 5524
由于是完全二叉树,所以我们可以预先知道整棵树的形状,因此可以判断根节点的两个子节点哪个是满二叉树,哪个不是满二叉树(必然是一边满,一边不满),对于满的子节点,我们可以直接求出它的不同子树的个数,也就是 ...
- 使用Dede破解Delphi软件实战
昨日练习了一把如何破解Delphi软件.下面和大家分享一下破解的过程,对初学者,希望有授之以渔的作用. 首先分析我们的目标软件,不要问我破解的是什么软件.保护知识产权,要从娃娃抓取. 目标软件是一个销 ...
- 在DbGrid中,不按下Ctrl,单击鼠标如何实现多选?谢谢
解决方案 » 有了dbgrid1.options.dgmultiselect:=true;必须按下Ctrl键,才能实现多选, 修改源代码,把以下内容if Select and (ssShift i ...
- Struts创建流程
1.启动服务,加载web.xml 并实例化StrutsPrepareAndExecuteFilter过滤器 2.在实例化StrutsPrepareAndExecuteFilter的时候会执行过滤器中的 ...