hadoop之hdfs及其工作原理
hadoop之hdfs及其工作原理
(一)hdfs产生的背景
随着数据量的不断增大和增长速度的不断加快,一台机器上已经容纳不下,因此就需要放到更多的机器中,但这样做不方便维护和管理,因此需要一种文件系统进行统一管理;另一方面,数据量之大,势必会对处理器性能提出了更大的要求,单个处理器性能的提升成本极高且已到达技术瓶颈(目前来看),因此纵向扩展的这条道路已经闭塞,只能考虑横向扩展,添加更多的机器。就在这种背景下,HDFS应运而生,它是一种分布式文件系统,它由多台主机的进程系统完成某个应用,当然每台主机各司其职(这个会在下文中进行介绍)。
(二)hdfs的优缺点
优点:
(1)适合大数据的处理
数据规模:能够处理能够处理GB、TB甚至PB级别的数据
文件规模:能够处理百万规模以上的文件数量
(2)低成本
hdfs可搭建在普通廉价机器中,成本较低,追随世界潮流,实现去IOE(IBM的小型机、Oracle的数据库服务器、EMC的共享存储设备 )。
(3)高容错性
廉价机器所带来的负面情况便是就是机器的故障率较高,hdfs通过增加副本的形式来提高容错性,某一副本丢失可根据其他副本自动恢复。
缺点:
(1)不适合低延时的数据访问,比如毫秒级的数据访问它是做不到的。
(2)不适合对大量小文件进行存储
存储大量的小文件,namenode中会存储每个文件的元数据信息(约150k),占用大量空间,毕竟namenode是有限的。
小文件的存储的寻址时间远大于它的读取时间,违背了hdfs的设计原则。
(3)不支持并发写入和随机修改
一个文件不支持多个线程同时写,仅支持文件的追加(append),不支文件的随机修改。
(三)hdfs的架构
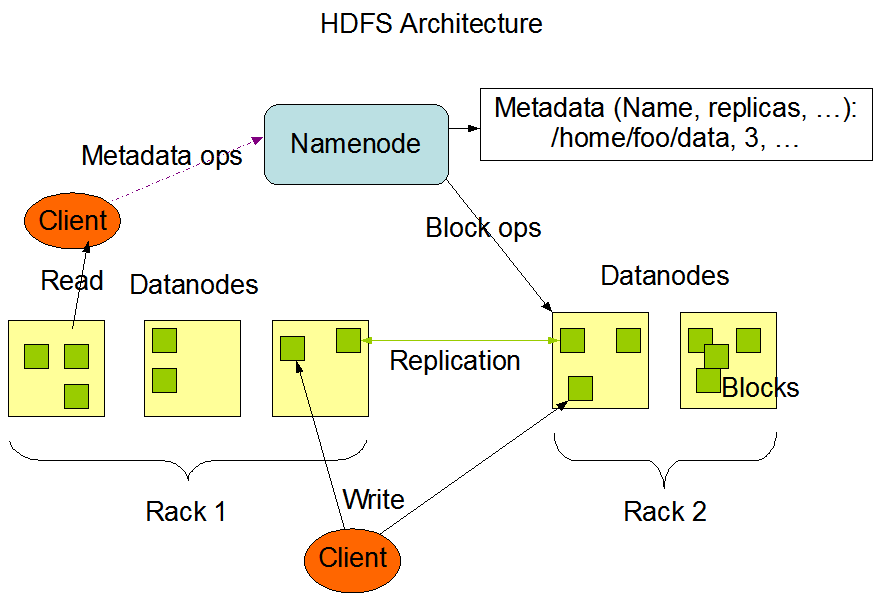
hdfs的架构主要由四部分组成:
(1)hdfs Client
客户端可通过一些命令来访问hdfs,可访问namenode获得文件的元数据信息,与datanode交互对文件进行读取。
客户端负责文件的切分,在文件上传时,它将文件切分成block进行存储
(2)namenode
namenode就是master,它用于存储文件的元数据信息,包括文件的类型、大小、路径、权限等。它是一个管理者,管理数据块的映射信息。
namenode用于处理客户端的读写请求。
(3)datanode
datanode就是slaves,namenode处理请求,下达命令,datanode执行实际的操作。
datanode中以block为单位存储了真实的数据。
(4)seconderaynamenode
secondarynamenode并未在上述架构中展示出来,它是namonode的辅助节点。在namenode挂掉的情况下,它并不能立即代替namenode提供服务,仅能够辅助namenode的恢复
定期合成Fsimage和Edits文件并推送给namenode(这两个文件将在后续进行介绍)。
(四)hdfs文件块(block)的大小
hdfs是以block为单位进行数据的存储,hadoop2.X中block的默认大小为128M,默认副本数为3,当然这两个值可通过配置文件进行设置(dfs.replicationdfs.blocksize)。
hdfs的block的大小要比磁盘要大,这是为了最小化寻址时间。如果block设置的足够大,定位这个块的时间要远小于数据的传输时间。这样以来,文件的传输时间就取决于磁盘的传输速率。
目前情况下,磁盘的选址时间在10ms左右,为了使磁盘的寻址时间为传输时间的1%,需要把传输时间限制在1s左右,而目前市场的磁盘的传输效率平均为100M/s,因此块的大小设置为100M左右,之所以设置为128M,笔者认为处于两方面考虑,其一,磁盘的传输效率会随着技术的提升而增加,其二,符合计算机领域的美感。
(五)NameNode和SeconderayNamenode的工作机制
NameNode对元数据进行管理,它管理三种元数据:
1)内存元数据(完整的metadata)
2)准完整的元数据镜像文件fsimage
3)用于衔接内存元数据和持久化元数据镜像的编辑日志edits文件
首先我们来看一下实际存在的fsimage文件和edits文件中存储的什么内容?
由于fsimage文件和edits文件时经过序列化的文件,因此无法直接查看,可通过下列命令将文件转换为xml格式进行查看:
hdfs oie/ove -i fsimage/edits -out -p xml
fsimage文件中存储的是文件和文件夹元数据的目录树结构;edits存储的是写操作的步骤(具体结构不在这里展示)。
了解了元数据的存储位置后,下面我们来介绍一下Namenode是如何管理元数据的:
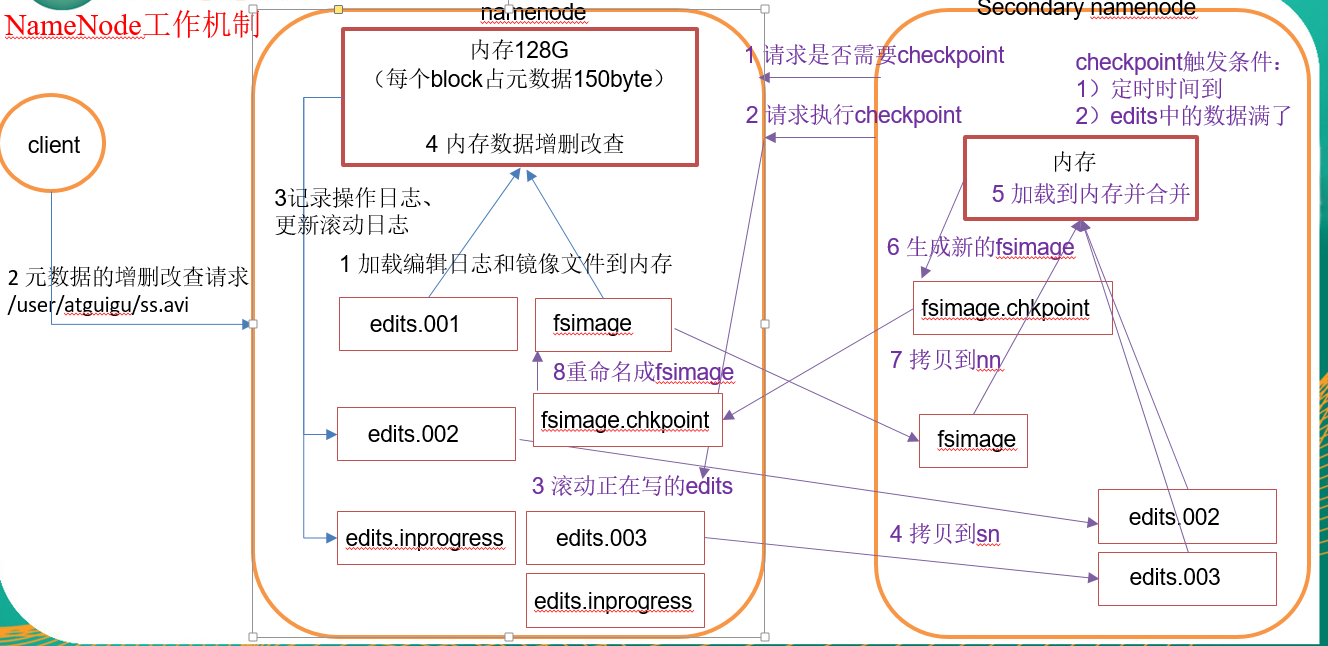
1)Namenode在启动时,首相将最近的fsimage镜像文件加载入内存,然后将edtis_progress文件实例化为新的edtis文件,并将该edits文件加载入内存,这样内存中就拥有了完整的元数据,可供客户端进行相关操作。
2)客户端向Namenode提出更新元数据的请求,Namenode首先更新edtis文件,记录日志,然后对内存中的元数据进行增删改。
我们了解到namenode在每次启动时都滚动了edits文件,那么fsimage文件是如何产生,或者说是什么时候产生的?这就要看一下另外一个节点SecondorayNamenode是如何工作的。
SeconderayNamenode:通过配置文件设置到一定时间或者一定情况就会出发一个叫做检查点(checkpoint)的东西,此时就会对namenode的fsimage和edits进行滚动和合成。默认出发检查点的条件有两个:时间:3600s=1h;文件大小:edits中的数据存满(操作次数1000000)。具体SeconderayNamenode的滚动流程如下:
1)SeconderayNamenode通知Namenode将edits文件进行滚动
2)SeconderayNamenode将namenode中的edits文件和fsimage文件通过http GET发送到自己的文件夹下
3)SeconderayNamenode将edits文件和fsimage文件在内存中进行融合生成新的fsimage.ckp文件
4)SeconderayNamenode将融合后的检查点文件传给namenode (http post)
5)Namenode重命名融合后的检查点文件。
下图可供参考(某机构所盗):
(六)DataNode的工作机制
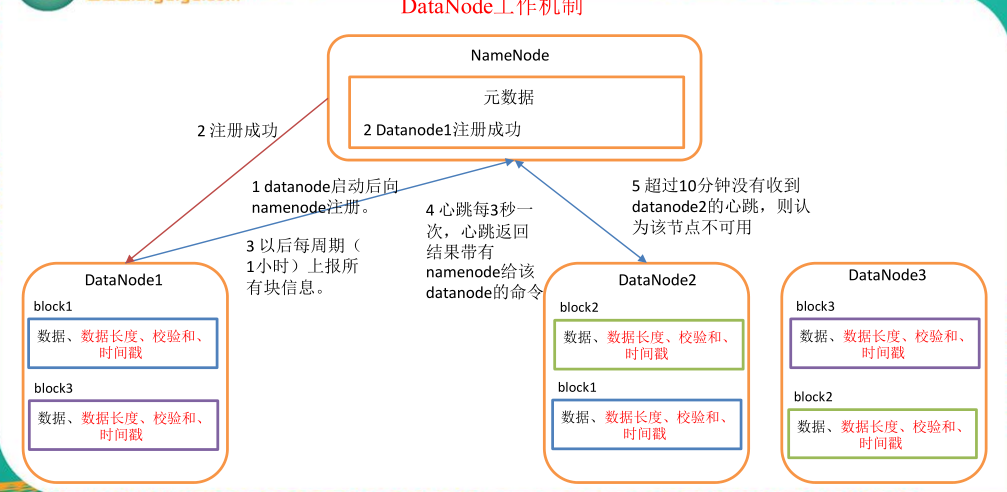
1)一个数据块在 datanode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode 启动后向 namenode 注册,通过后,周期性(1 小时)的向 namenode 上报所有的块信息。
3)心跳是每 3 秒一次,心跳返回结果带有 namenode 给该 datanode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 datanode 的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器
hadoop之hdfs及其工作原理的更多相关文章
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
- 一图看懂hadoop Spark On Yarn工作原理
hadoop Spark On Yarn工作原理
- hadoop中HDFS的NameNode原理
1. hadoop中HDFS的NameNode原理 1.1. 组成 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 1.2. HDFS架构 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- 【Hadoop】HDFS的运行原理
博文已转移,请借一步说话http://www.weixuehao.com/archives/596 简介 HDFS(Hadoop Distributed File System )Hadoop分布式文 ...
随机推荐
- jquery中arrt()和prop()的区别
在jQuery中,attr()函数和prop()函数都用于设置或获取指定的属性,它们的参数和用法也几乎完全相同. 但不得不说的是,这两个函数的用处却并不相同.下面我们来详细介绍这两个函数之间的区别. ...
- 【HIHOCODER 1589】回文子串的数量(Manacher)
描述 给定一个字符串S,请统计S的所有|S| * (|S| + 1) / 2个子串中(首尾位置不同就算作不同的子串),有多少个是回文字符串? 输入 一个只包含小写字母的字符串S. 对于30%的数据,S ...
- 手撸一套纯粹的CQRS实现
关于CQRS,在实现上有很多差异,这是因为CQRS本身很简单,但是它犹如潘多拉魔盒的钥匙,有了它,读写分离.事件溯源.消息传递.最终一致性等都被引入了框架,从而导致CQRS背负了太多的混淆.本文旨在提 ...
- bzoj3262陌上花开 三维数点 cdq+树状数组
大早上的做了一道三维数点一道五位数点,神清气爽! 先给一维排序,变成一个奇怪的动态的二维数点(相当于有一个扫描面扫过去,导致一系列的加点和询问) 然后cdq分治,再变回静态,考虑前半段对后半段的影响 ...
- powerdesigner约束名唯一出错的解决办法
powerdesigner中自动生成的约束名有时会因为表的前缀一样而不具有唯一性,这样在生成时就会出错,一般的解决办法有以下两种: 1.模型=>Reference中可以看到当前模型中的所有Ref ...
- mysql primary partition分区
尝试把数据库一个表分区 ALTER TABLE user PARTITION BY RANGE(TO_DAYS(`date`)) ( PARTITION p1004 VALUES LESS THAN ...
- 移动端click时间、touch事件、tap事件详解
一.click 和 tap 比较 两者都会在点击时触发,但是在手机WEB端,click会有 200~300 ms,所以请用tap代替click作为点击事件. singleTap和doubleTap 分 ...
- xml报错“cvc-complex-type.2.4.c: The matching wildcard is strict, but no declaration can be found for element”
配置使用dubbo时,xml报错“cvc-complex-type.2.4.c: The matching wildcard is strict, but no declaration can be ...
- df和du显示的磁盘空间使用情况不一致问题
背景介绍: dba同事删除了mysql /datao目录下的文件,通过du –sh查看空间使用700G,df -h查看空间使用1T,没有重启mysql服务. 另一个表现出du与df命令不同之处的例子如 ...
- Conda相关命令的使用
-- Conda basics Conda基础命令 conda info 查看已安装的环境 conda install PACKAGENNAME 安装包 conda update PACKAGENAM ...