Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Split(切片)
1>.MapReduce处理的单位(切片)
想必你在看MapReduce的源码的时候,是不是也在源码中看到了一行注释“//Create the splits for the job”(下图是我跟源码的部分截图),这个切片是MapReduce的最重要的概念,没有之一!因为MapReduce处理的单位就是切片。
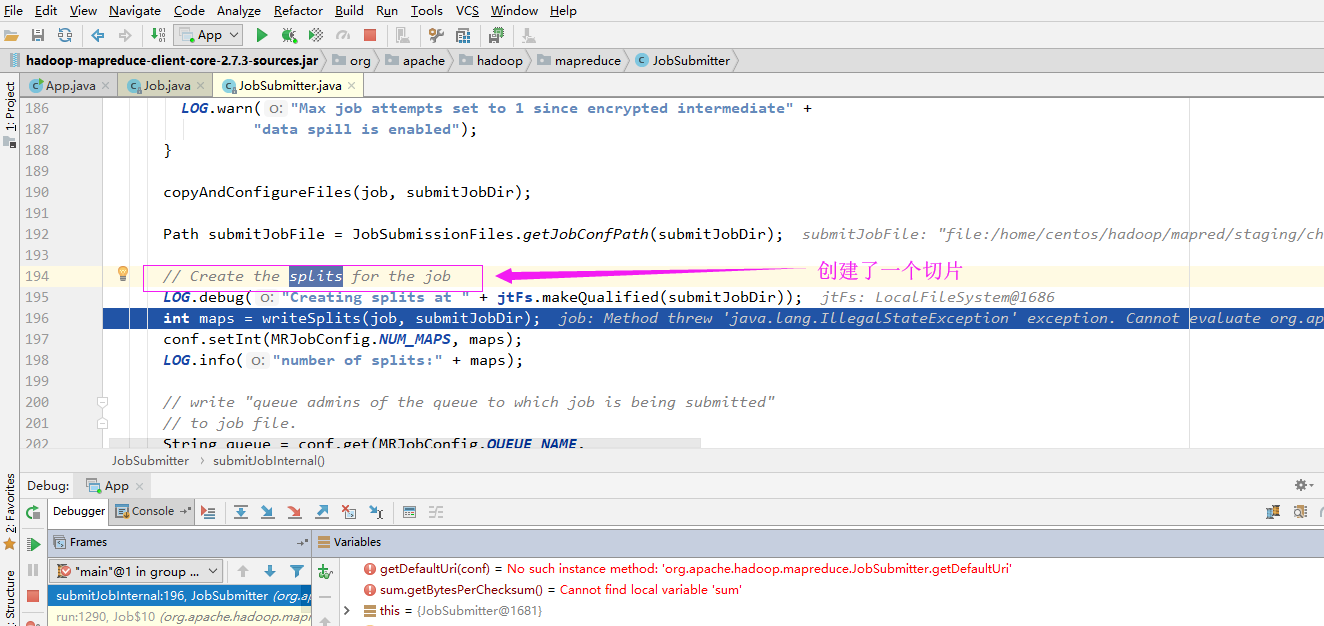
2>.逻辑切割
还记得hdfs存储的默认单位是什么吗?没错,默认版本是块(2.x版本的默认大小是128M),在MapReduce中默认处理的单位就是Split。其实切片本质上来说仍然是块,只不过和hdfs中的块是有所不同的。我们知道hdfs在存储一个大于1G的文件,会将文件按照hdfs默认的大小进行物理切割(将一个文件强行拆开,所有文件都是支持物理切割的!),放在不同的DataNode服务器上,而咱们的MapReduce的Split只是逻辑切割。
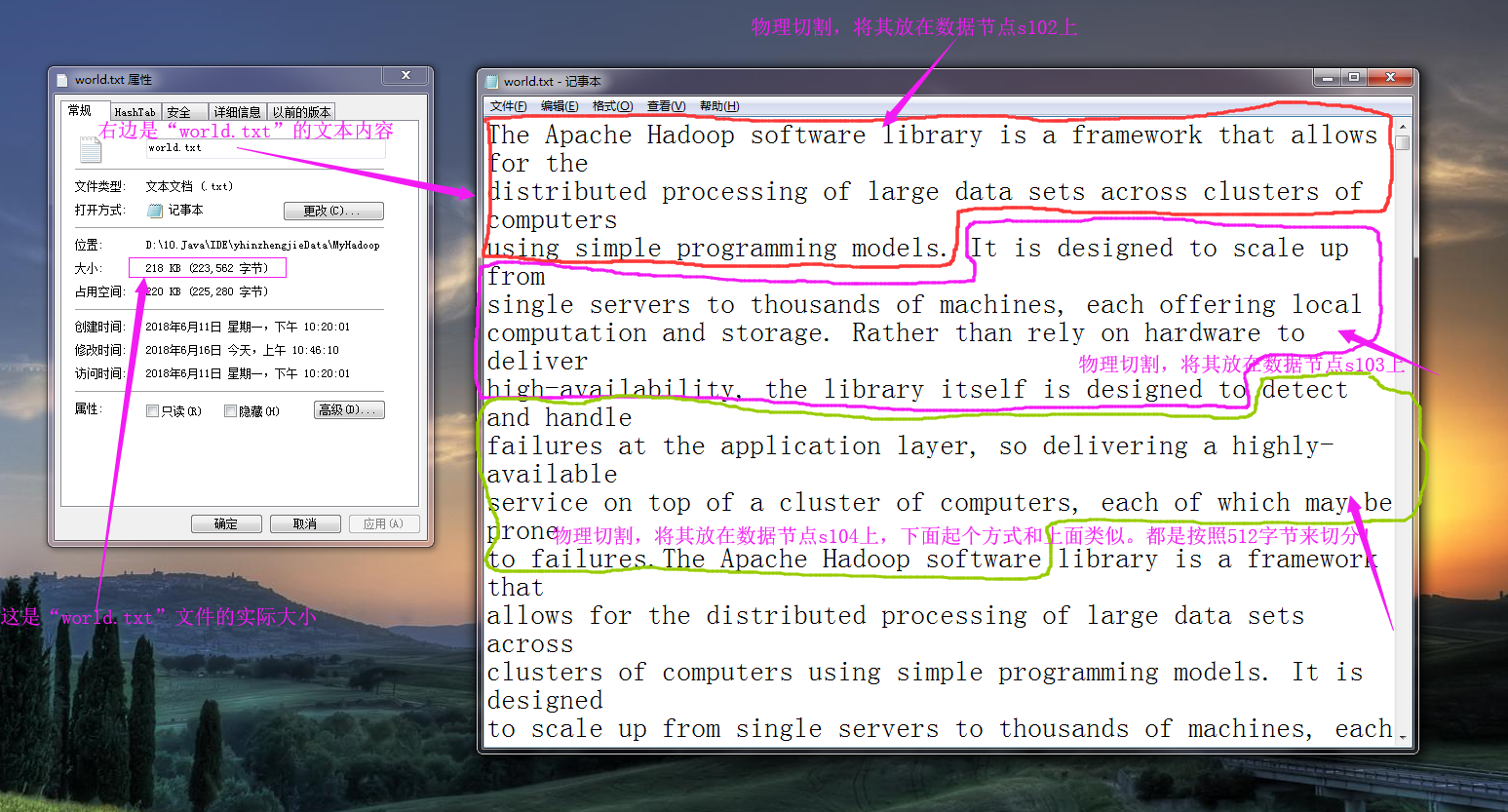
所谓的逻辑切割会判断切割处是否是行分隔符,换句话说,逻辑切割在切割文件的时候并不能像物理切割那样按照指定大小切割,而是按照程序员指定的规则进行切割(Split)。我们来举个例子,还记得我们之前写的一个单词统计的程序吗(https://www.cnblogs.com/yinzhengjie/p/9153256.html)?为了实验方便,我们可以把hdfs默认的128M改为512字节,那么我们在存储“world.txt”文件时,其物理切割大致用下图表示为:
而所谓的逻辑切割是程序员指定规则进行切割的,比如我们将“word.txt”按照空格进行切分,大致逻辑如下图所示:(逻辑切割很灵活的,它可以是按空格切割,也可以按行切割,还可以按照“\t”切割,在SequenceFile的话就直接是key和value的形式取值了,相对来说更正规,推荐使用这类的文件格式,我这里为了演示方便,就直接用文本类型格式进行切割操作。)
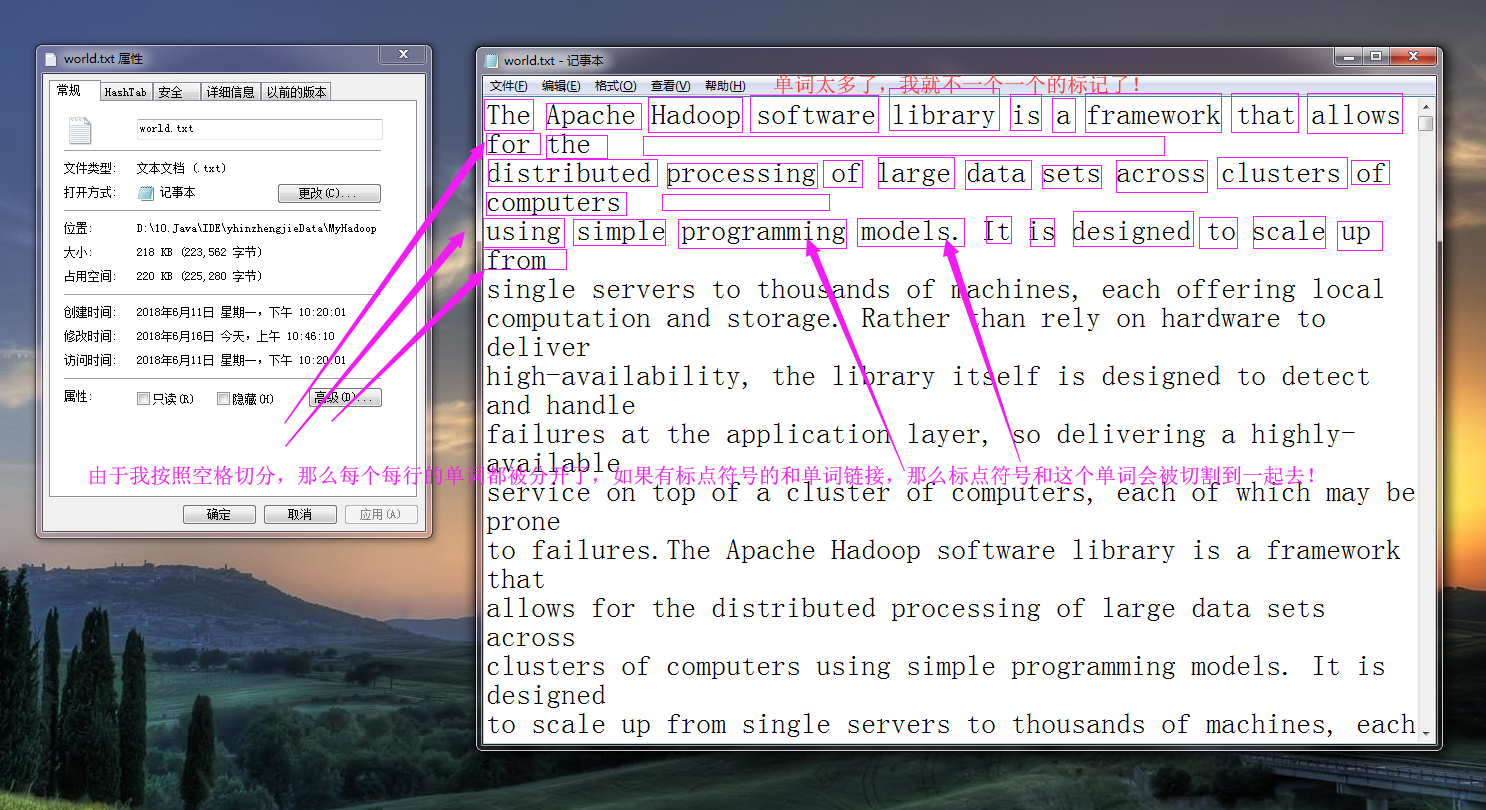
文本文件默认都是可以切割的(如上图所示),由于我们处理的是大数据,处理的数据可能不止是文本,还有视频,图片等等,比如淘宝公司的举行的双十一活动,一天光记录用户访问量就得需要“1PB”的数据量,如果这个时候我们还用文本文件去存储的话就不太合适了,实际上hadoop提供了一种SequenceFile容器文件,它不仅仅可以按照特定的格式存储文本信息,还支持Deflate,Gzip,Bzip2,Lz4,Snappy等压缩算法,其中Bzip2是极致压缩比例,而Lz4,Lzo和Snappy则是优化压缩速度,在生产环境下根据算法相关特性进行技术选型(当然除了hadoop序列化,还有Avro,Protocol Buffers等序列化技术都是可以供你选择的)。
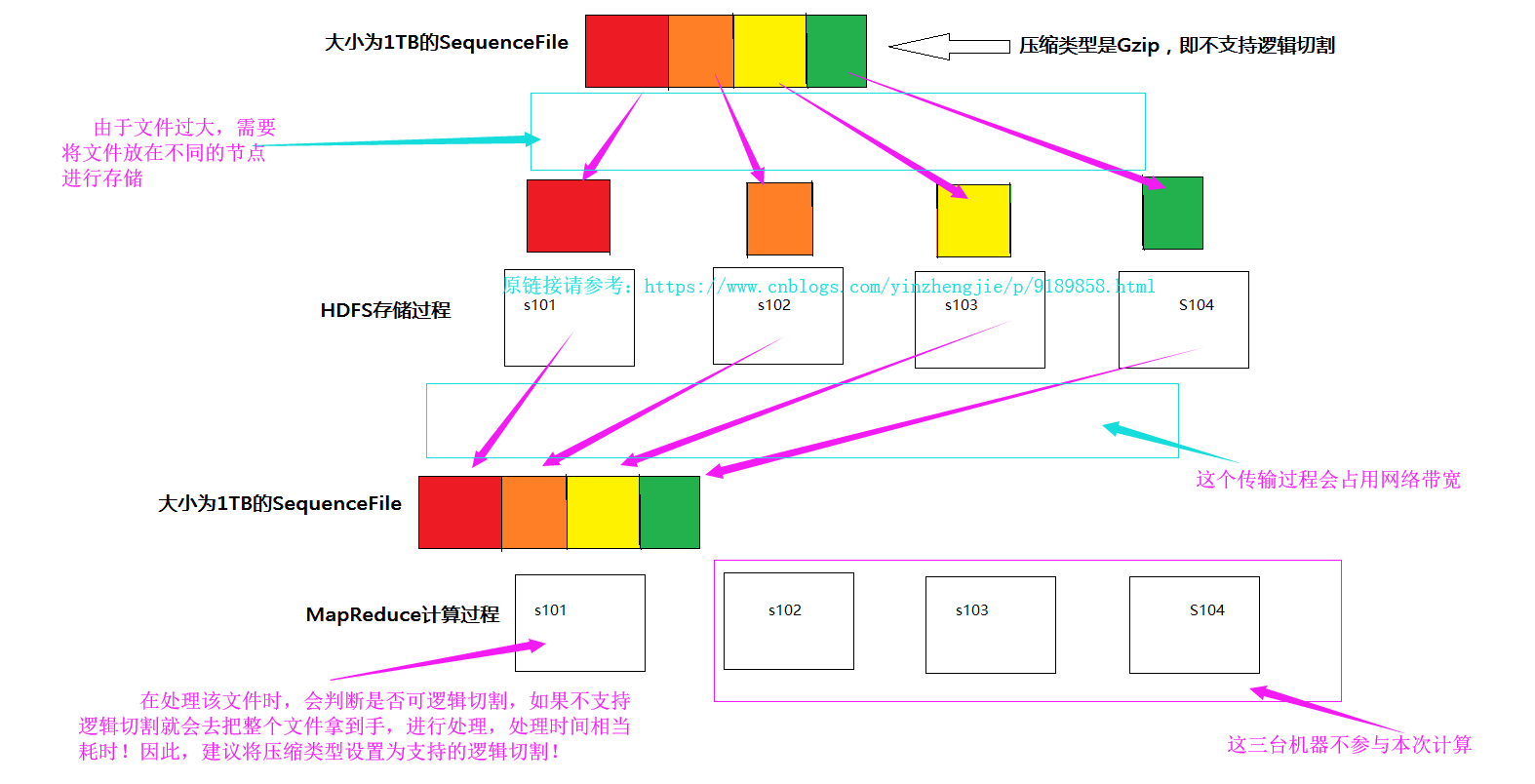
这些算法都是支持物理切割的,注意:Lzo(with index)和Bzip2是可逻辑切割的算法,适合在MR中使用。如果你的SequenceFile不是使用Lzo或是BZip进行压缩的,那就麻烦了,因为他们不支持逻辑切割,就会出现以下的情况。
3>.计算切片数量
从源代码中可以看出,有一个变量为"MinSize",其值为“1”

从源代码中可以看出,有一个变量为"MaxSize",其值为“long.Max_Value”
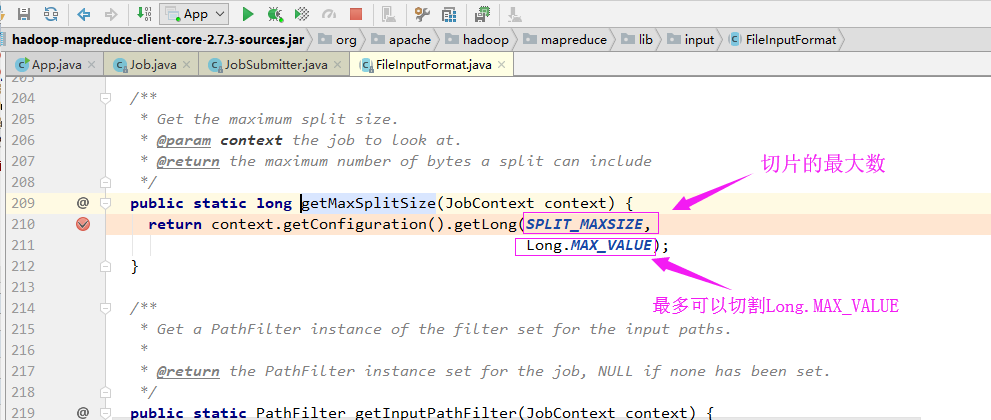
实际切片大小从代码调试的大小(长度)如下:
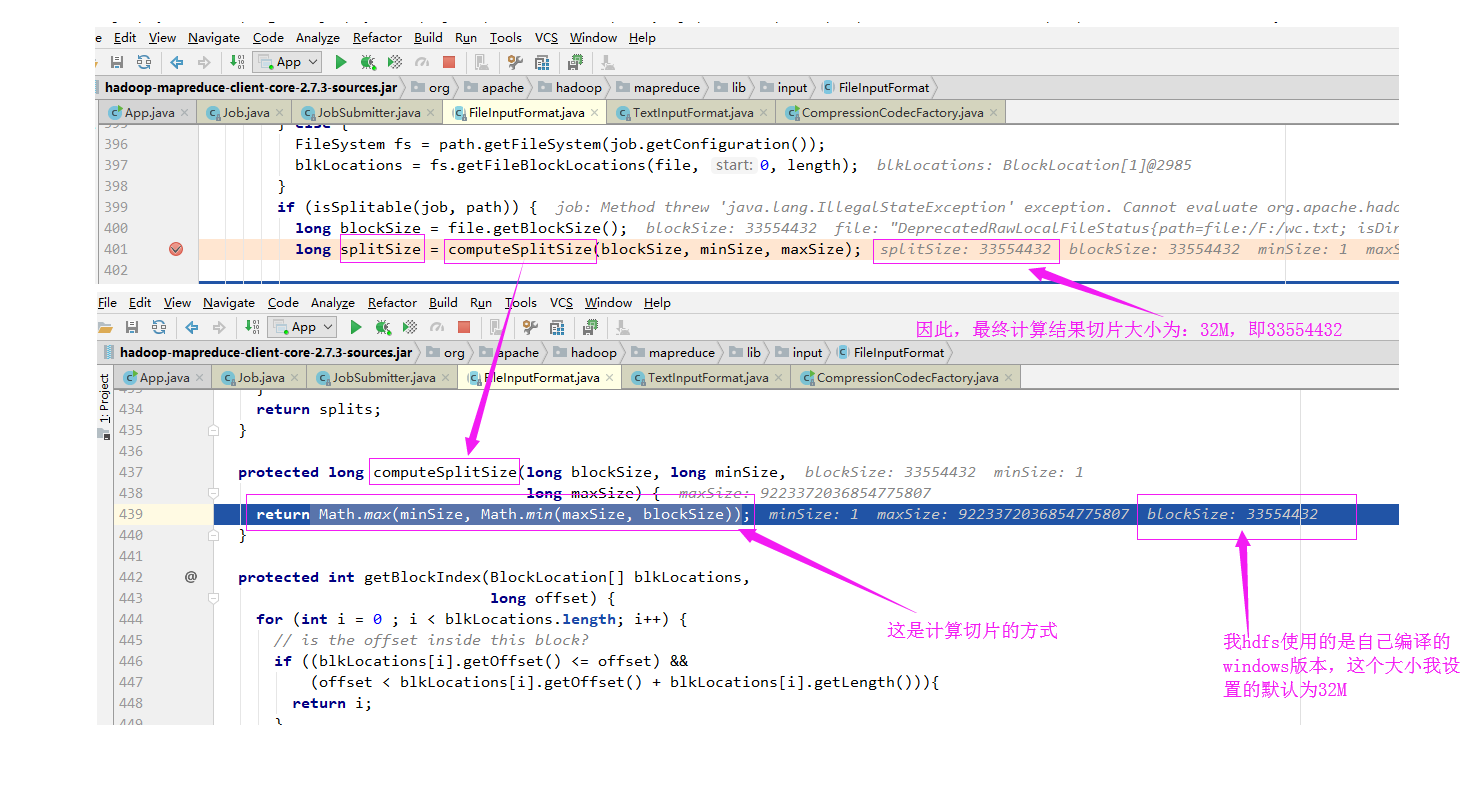
确认切片的偏移量:

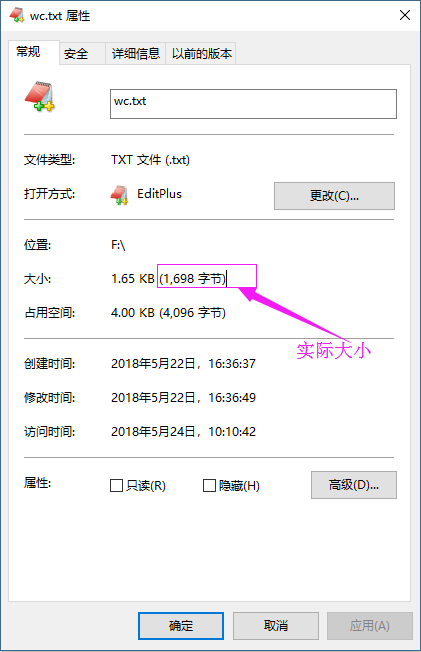
偏移量“0+1698”指的是文件的偏移量,如果文件较大,可能会被切割成多个切片进行处理,由于我测试的文件比较小,因此就被MapReduce切割成一个了,这个1698其实是文件的实际大小,如下:
4>.创建切片列表
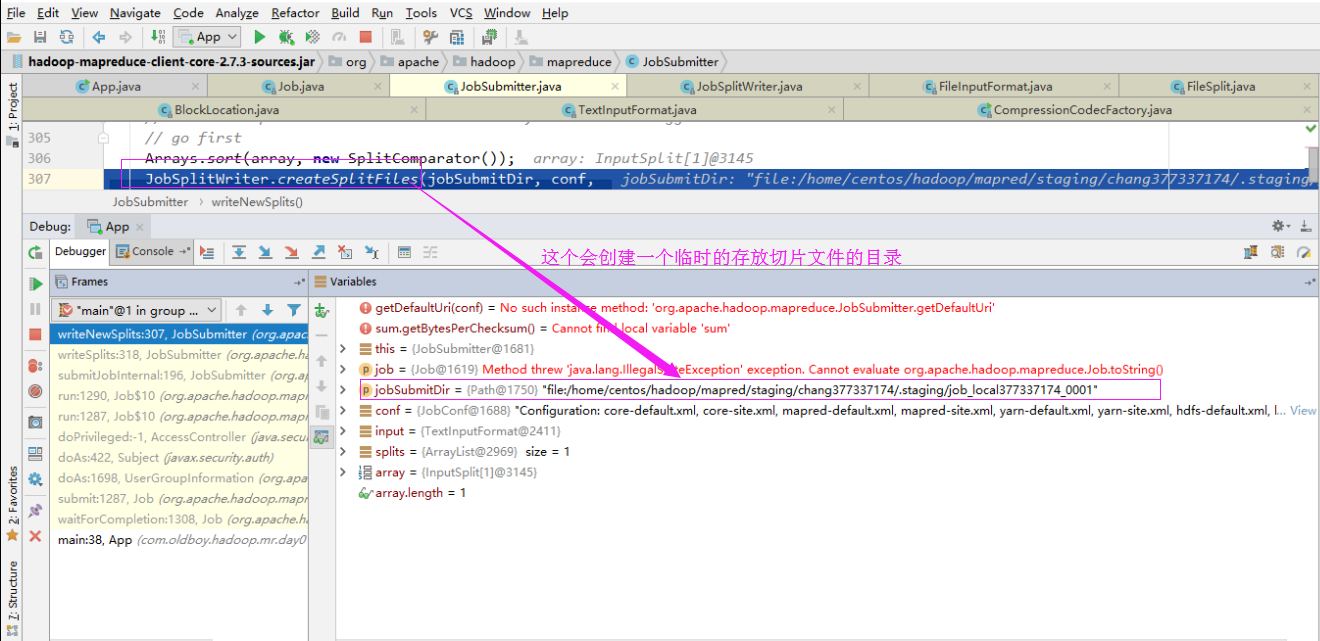
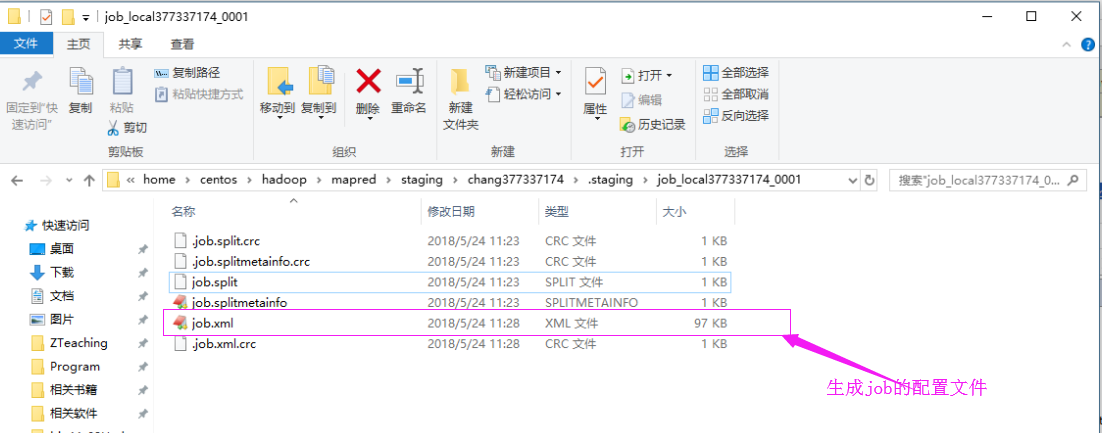
我们可以去这个切片目录中看看,如下:

5>..编写作业
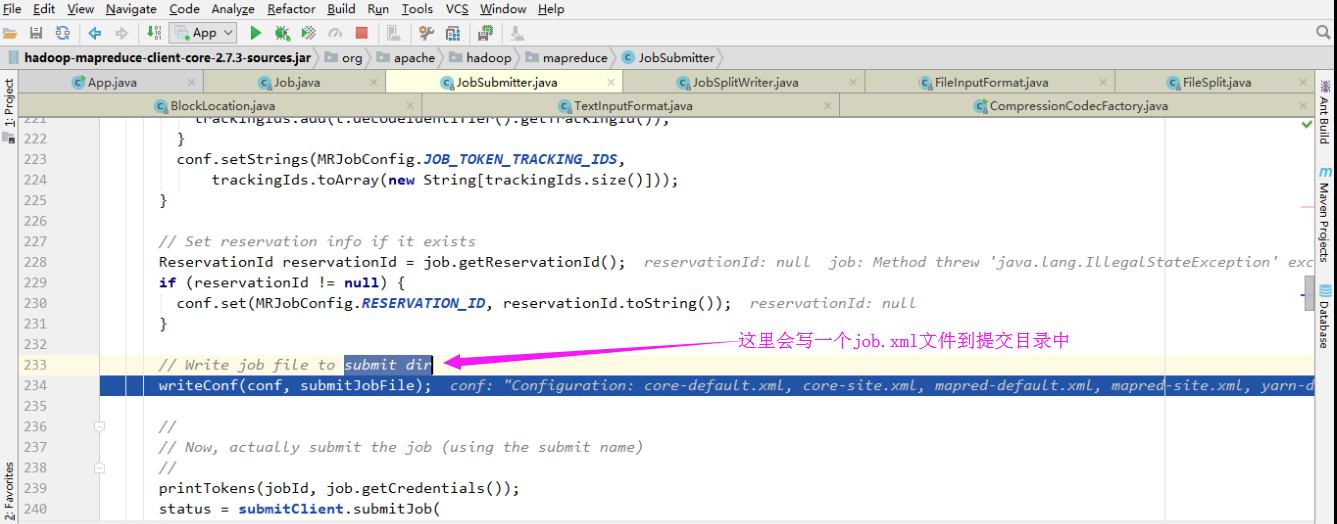
这个job文件和切片存放在同一个目录中:
5>.提交作业

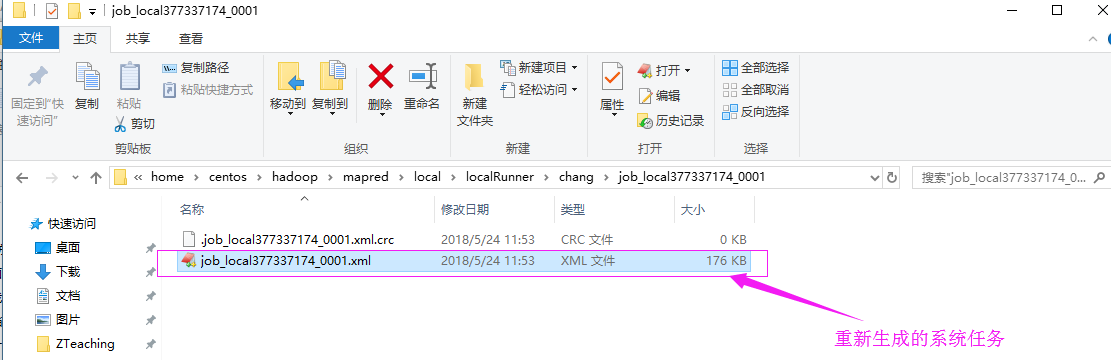
6>.创建当前job(比之前的job.xml更加详细的任务)
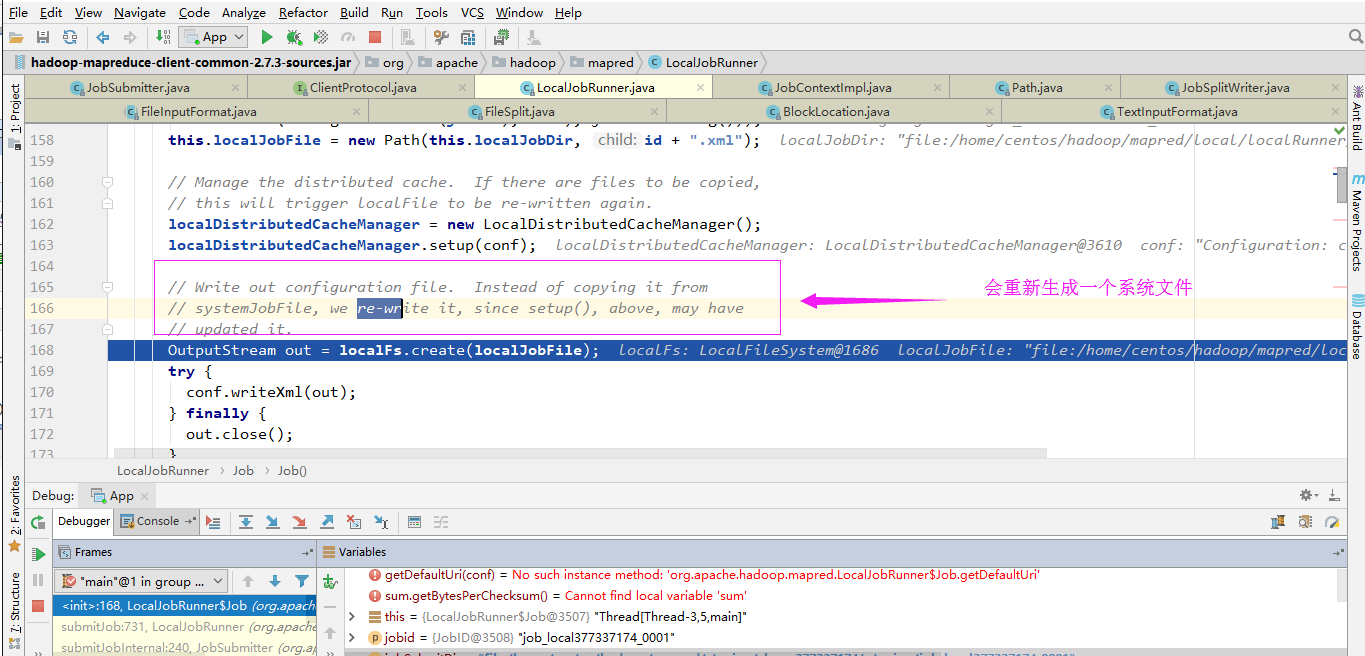
具体存放路径如下:
7>.启动线程
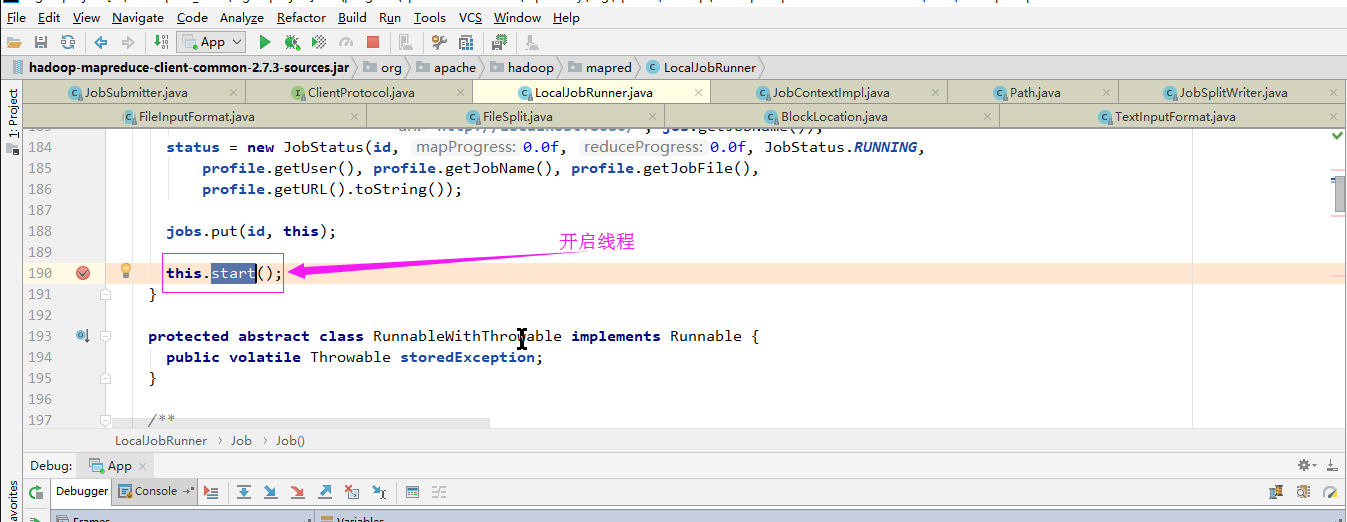
开启线程后会调用run方法:
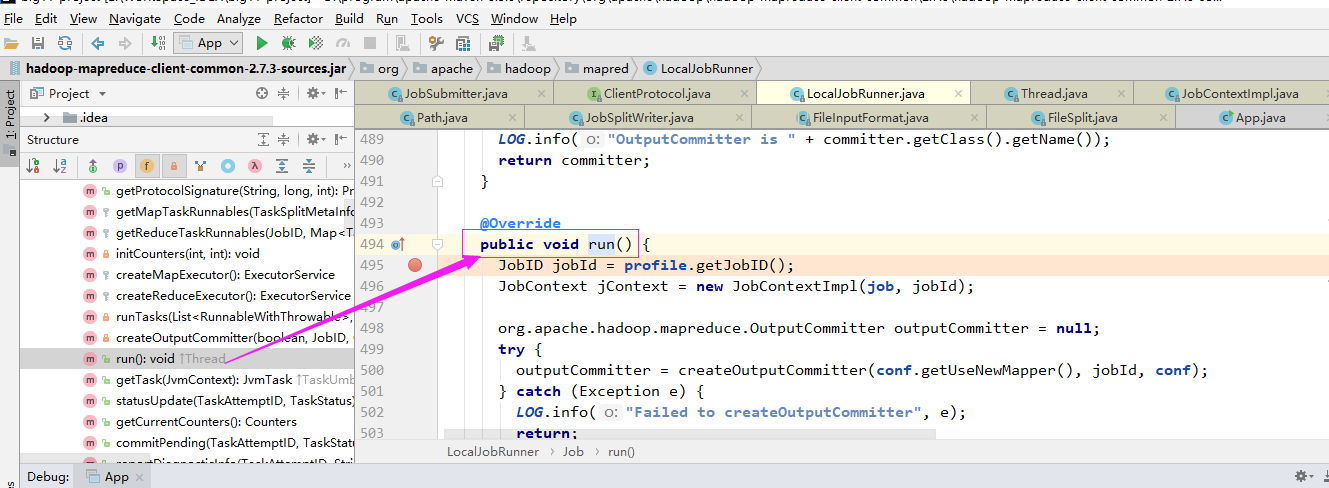
二.Mapper
1>.运行任务
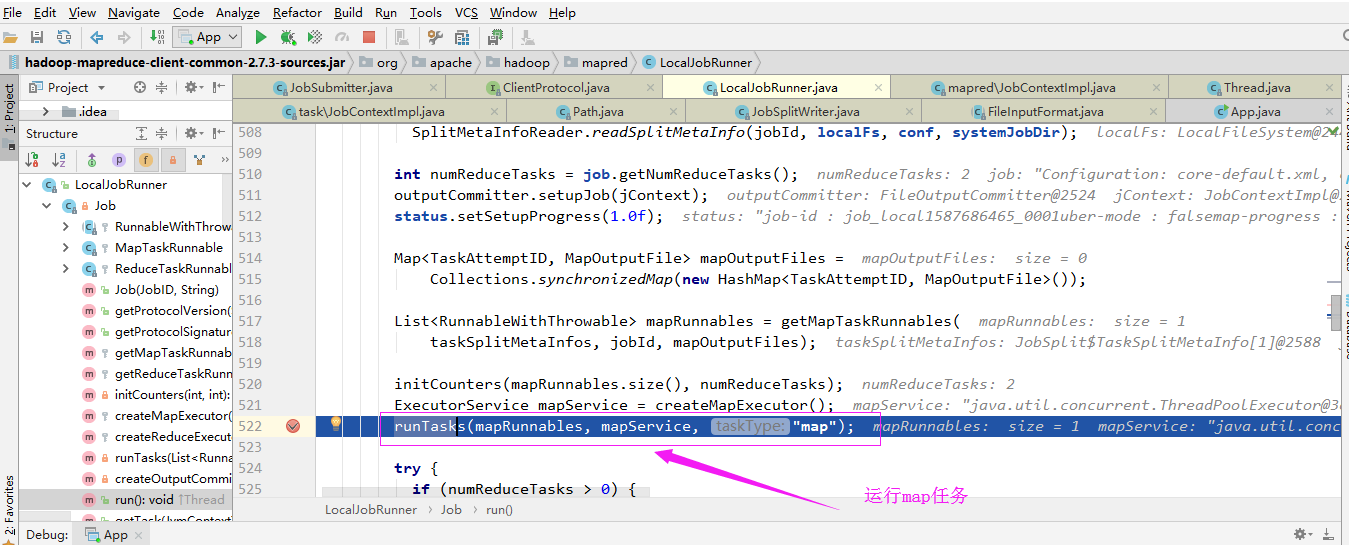
通过“LocalJobRunner$Job$MapTaskRunnable”内部类运行任务:
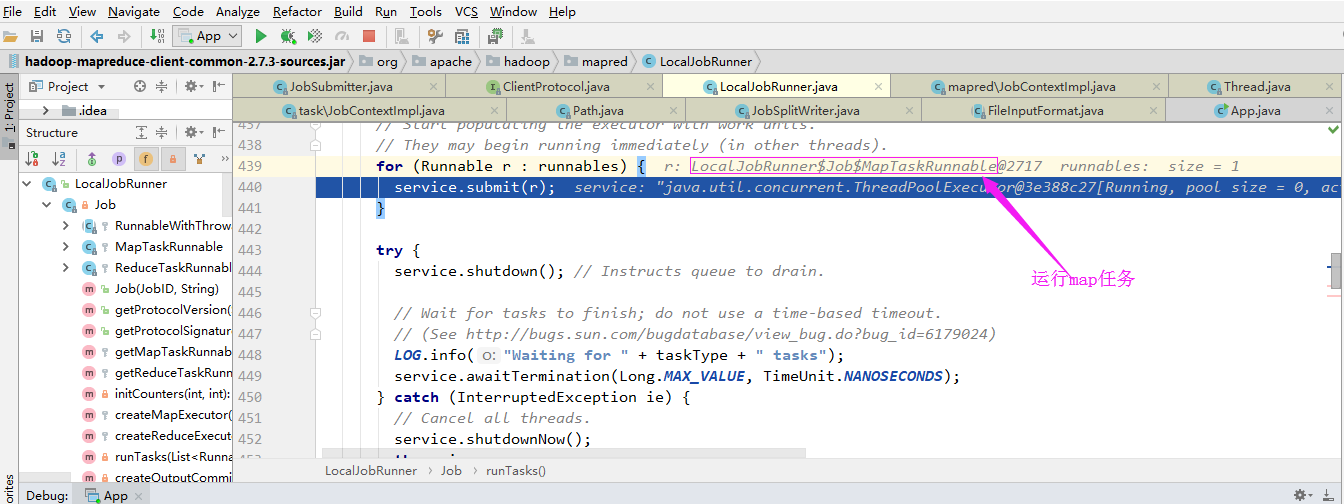
进入maper任务:
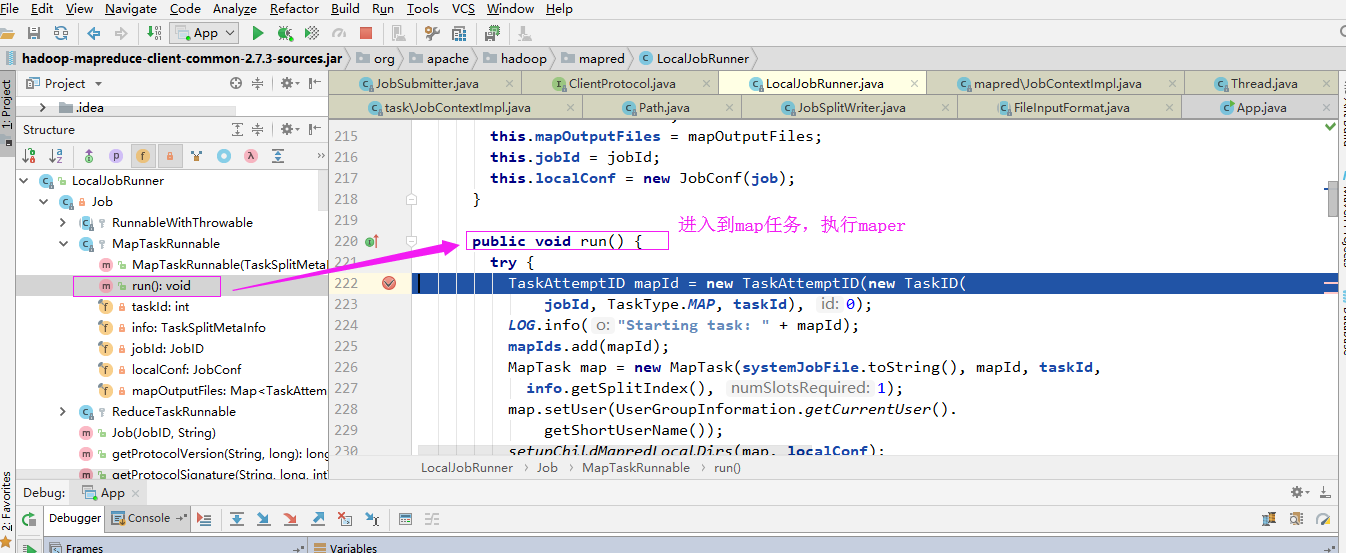
2>.通过反射得到map对象(Map程序是用户在通过“job.setMapperClass”方法设置的)
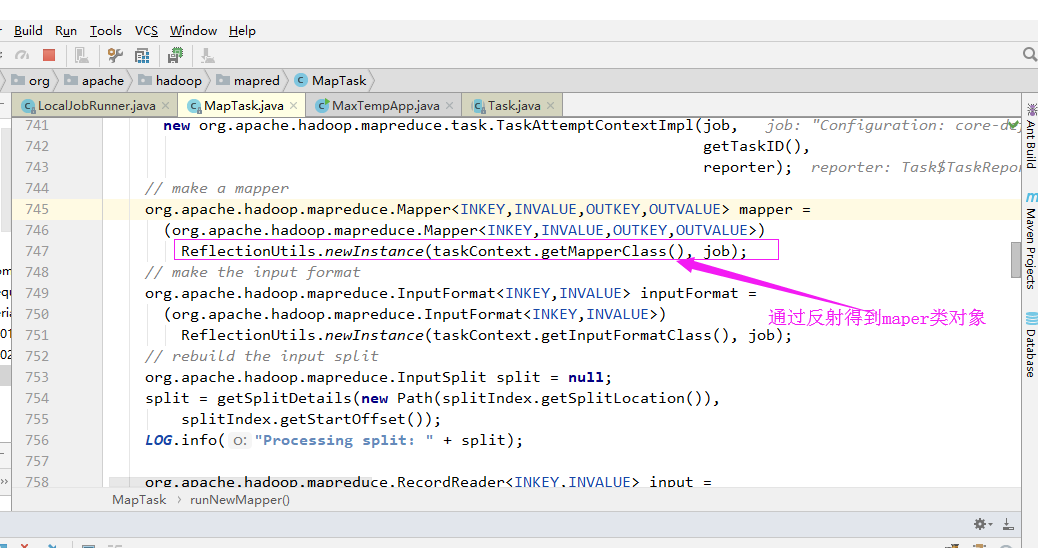
3>.记录阅读器
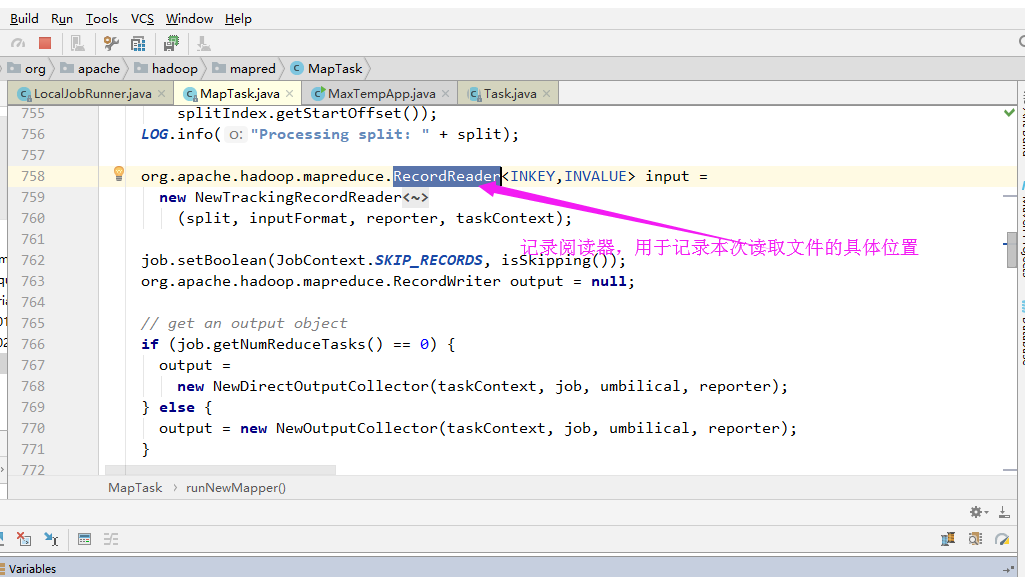
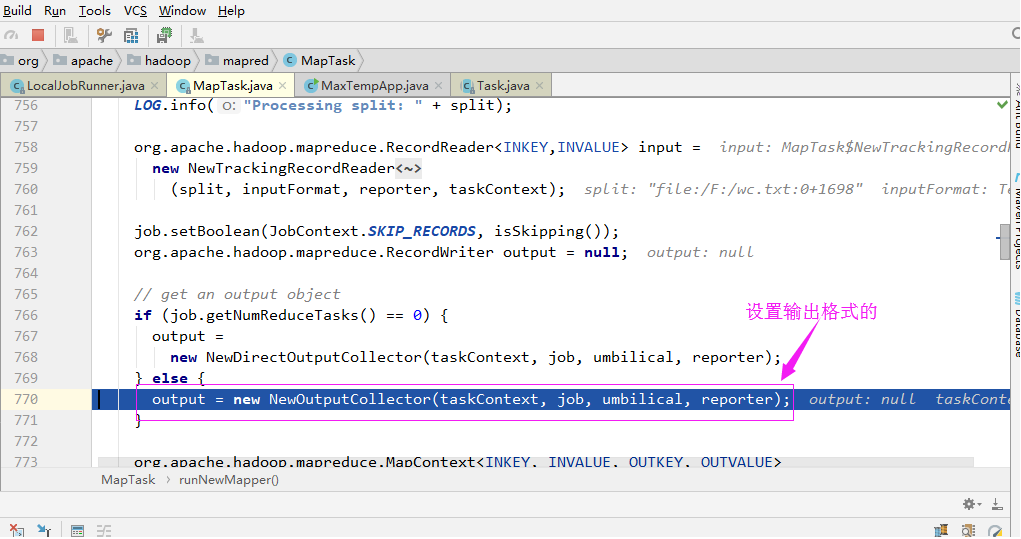
3>.设置输出格式
4>.Maper的回调机制
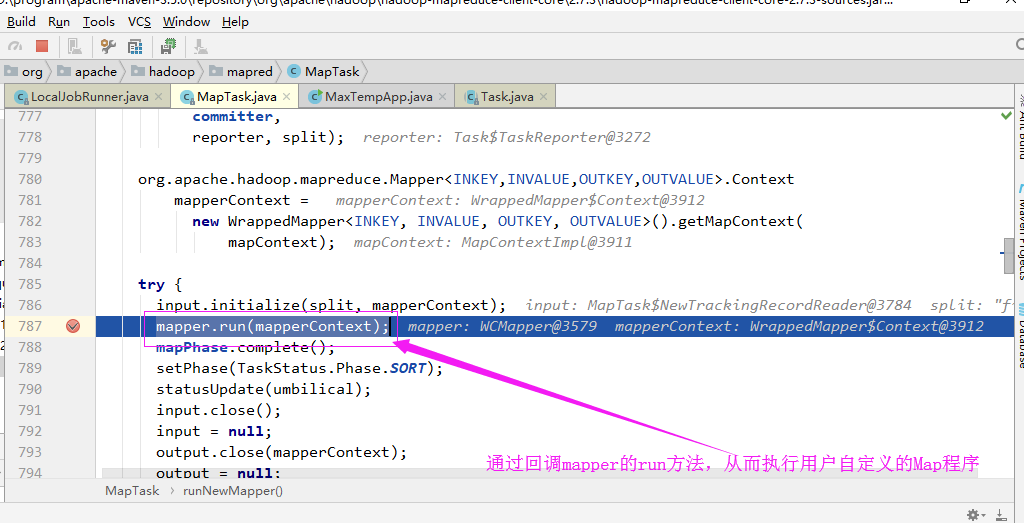
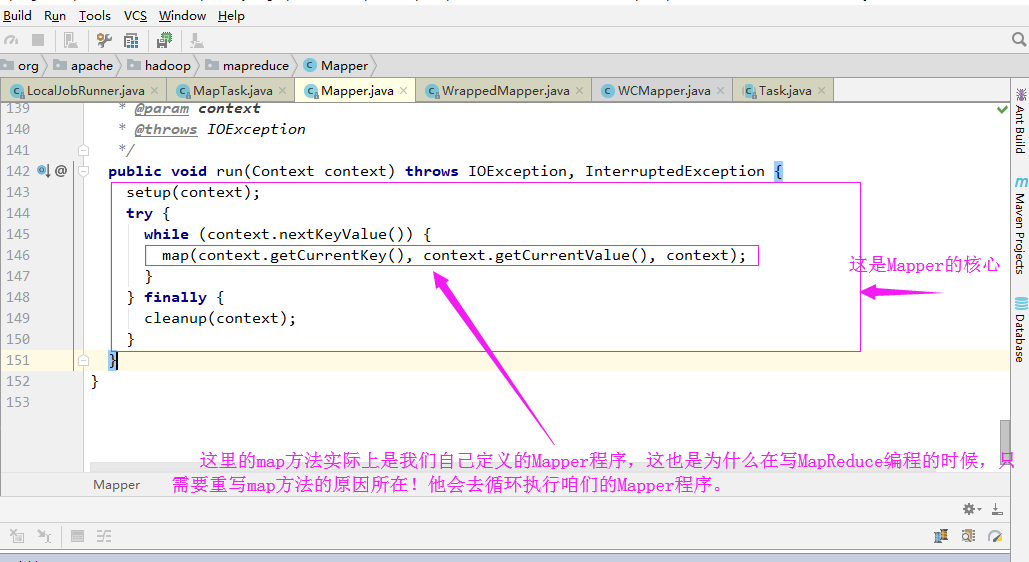
回调函数其实调用的mapper的run方法:
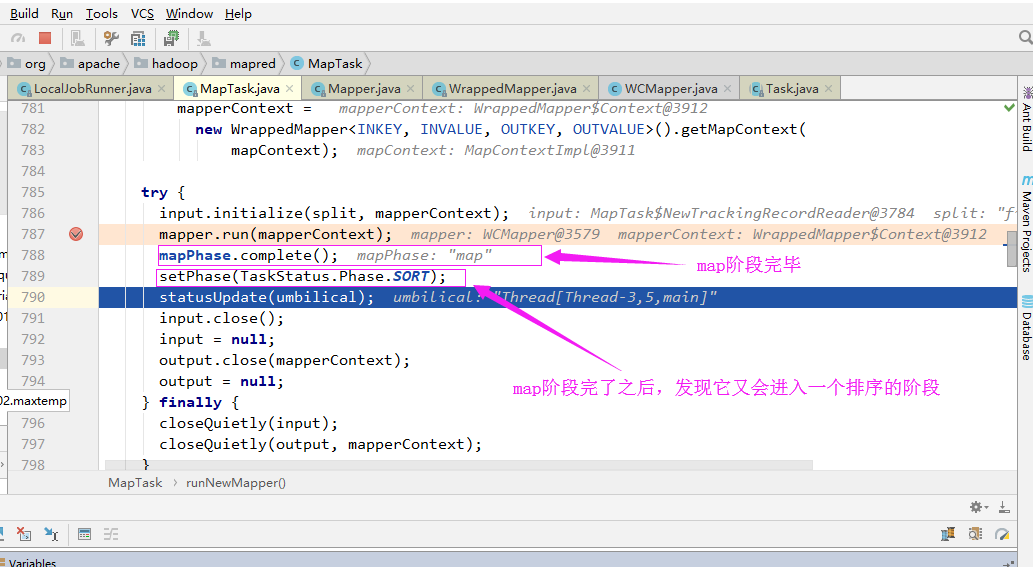
5>.排序阶段
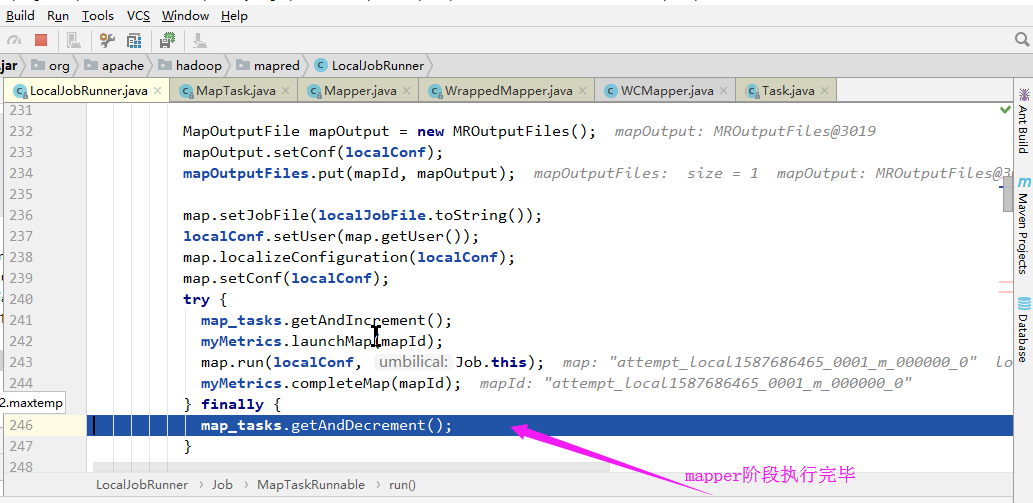
6>.Maper阶段执行结束
三.Reduce
Mapper阶段执行完毕之后,经过shuffle和sort等操作最终会进入到Reduce阶段,而Reduce阶段的实现过程和Mapper类似,它会首先启动一个”LocalJobRunner$Job$ReduceTaskRunnable“的线程,这里就不带截图了。继续打断点调试即可。此部分略过。
四.InputFormat
1>.TextInputFormat

2>.LzoTextInputFormat
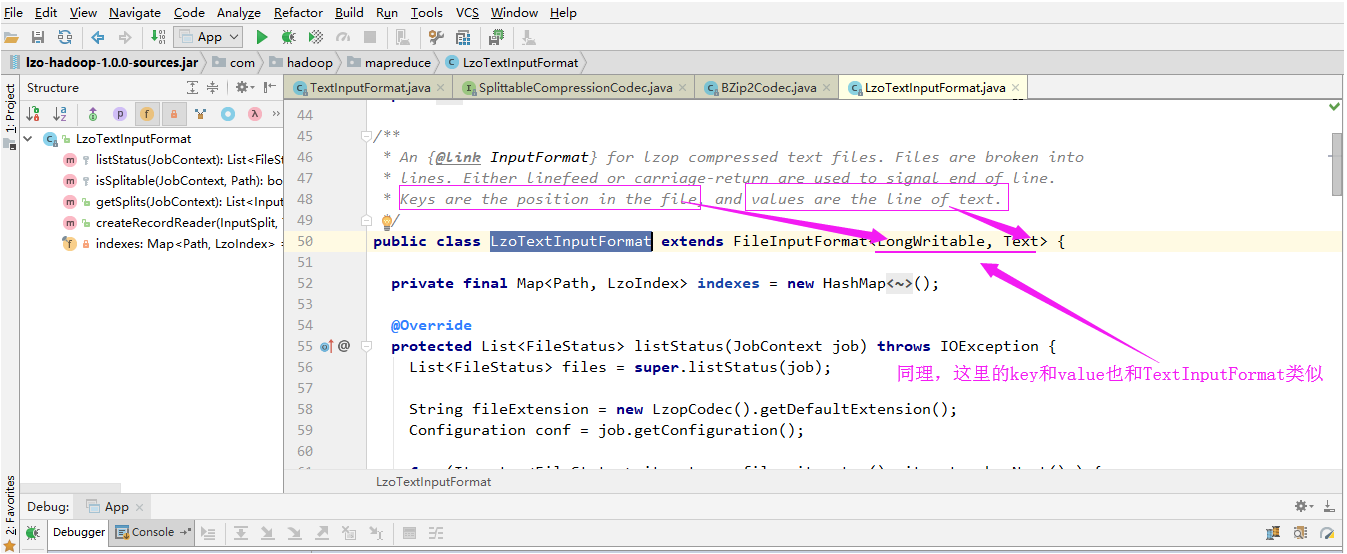
3>.读行的类
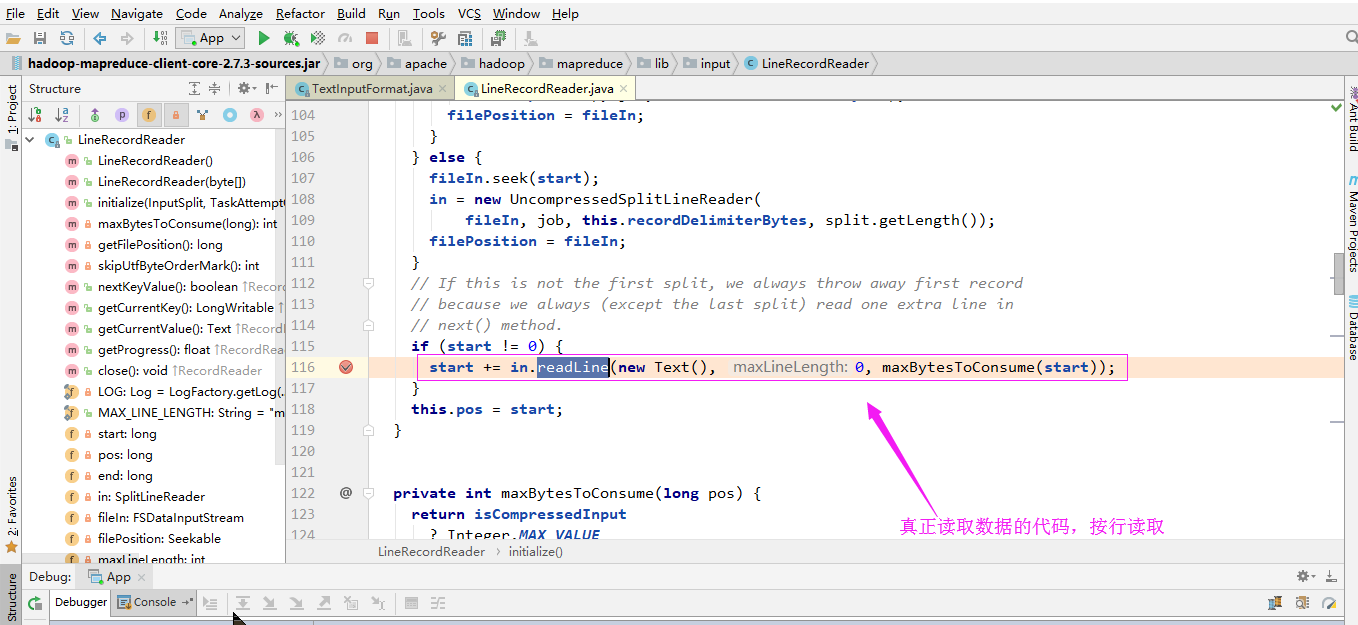
下图是部分调用过程:

4>.SequenceFileInputFormat
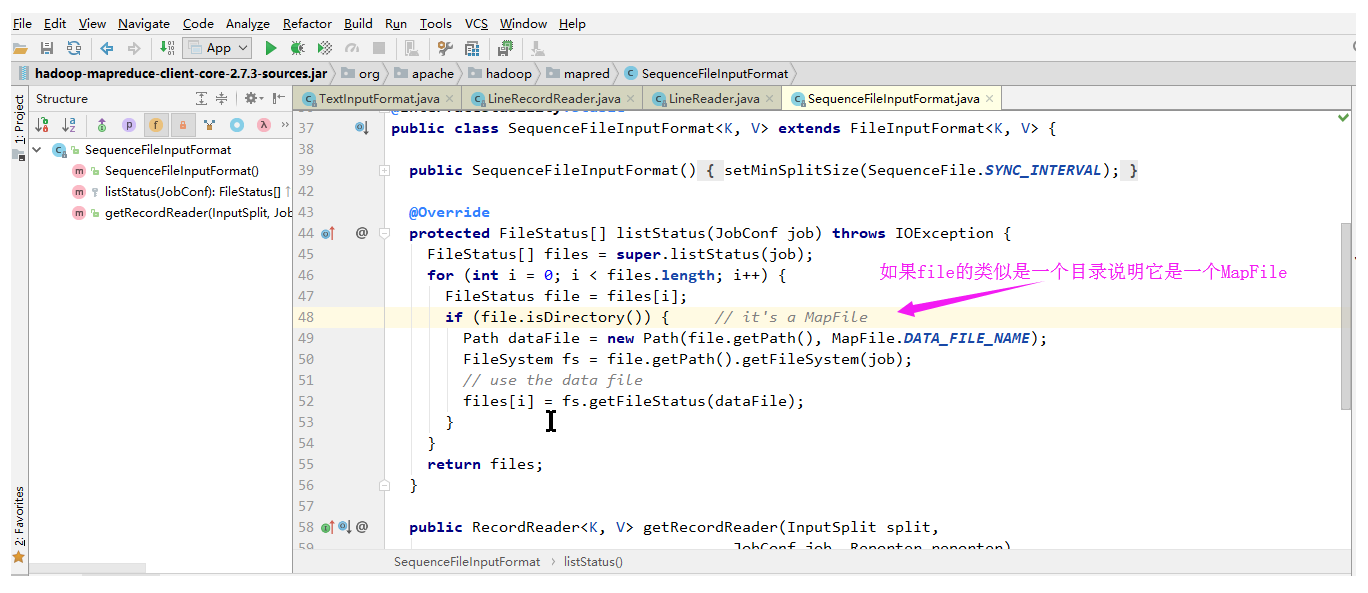
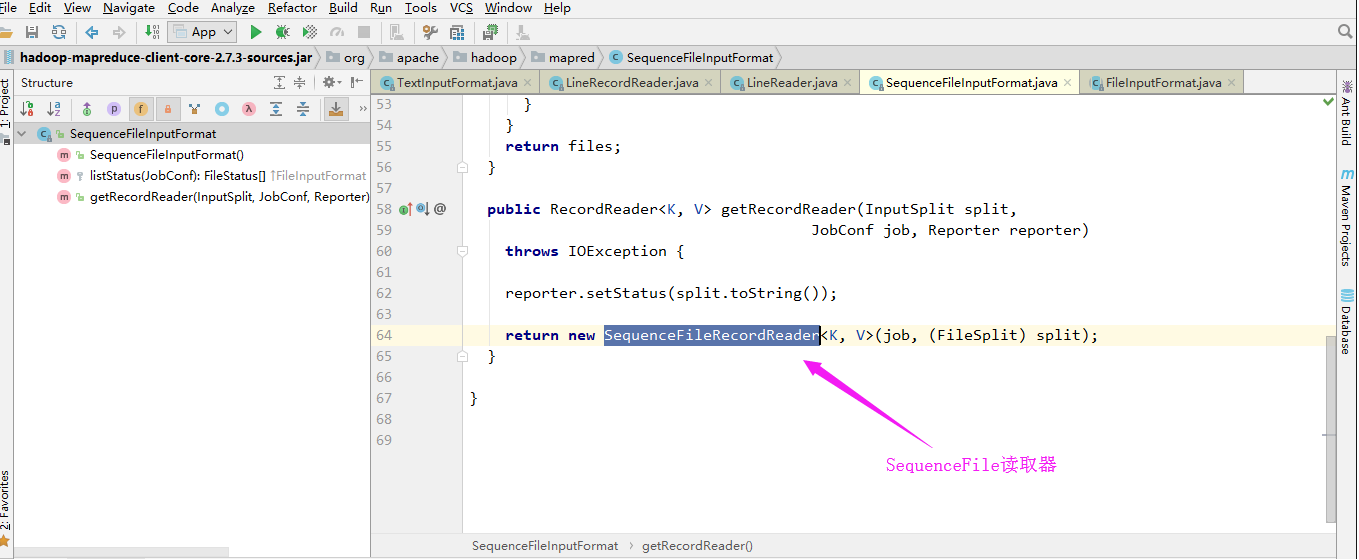
SequenceFileInputFormat是可切割的:

SequenceFile读取器:
Hadoop基础-MapReduce的工作原理第二弹的更多相关文章
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
随机推荐
- angular-ui-router速学
Demo1 初始化 <html ng-app="app"> <head> <style>.active { color: red; font-w ...
- 利用Github搭建自己的博客
教程链接:搭建个人博客 嘿嘿嘿!!一直想自己搭建博客的,一直没机会,这次终于把博客搭了起来.虽然只是一个壳子..套了别人的模板~不过还是很令人兴奋哟!总的来说,就按照这个教程一直往下走,其中有一个坑就 ...
- Android与Libgdx入门实例
本文讲解如何实现Android与Libgdx各自的Hello World过程. 1. Android版Hello World 点击Eclipse快捷方式,选择New Android Applicati ...
- kubernetes 集群新增node 节点并将应用分配到新增节点
第一章 1.重新安装一台kubernetes node节点,新增节点:192.168.1.192 网址:https://www.cnblogs.com/zoulixiang/p/9504324.htm ...
- manjaro设置国内源
升级系统到最新 sudo pacman -Syyu 配置源 kate /etc/pacman.conf 官方镜像源(包括 core, extra, community, multilib ) sudo ...
- pyinstaller将python编写的打卡程序打包成exe
编写了一个简易的定时提醒下班打卡程序,python代码如下: #coding:utf-8 import time import datetime from tkMessageBox import * ...
- Invalid AABB inAABB UnityEngine.Canvas:SendWillRenderCanvases()的解决办法
我遇到这个问题的情况是, 在Start()中直接使用WWW价值本地图片,可能是加载图片相对比较耗时,就出现了这个错误. 解决的办法是使用协程: // Use this for initializati ...
- Python中元组,列表,字典的区别
http://blog.csdn.net/yasi_xi/article/details/38384047
- 链家鸟哥:从留级打架问题学生到PHP大神,他的人生驱动力竟然是?
链家鸟哥:从留级打架问题学生到PHP大神,他的人生驱动力竟然是?| 二叉树短视频 http://mp.weixin.qq.com/s/D4l_zOpKDakptCM__4hLrQ 从问题劝退学生到高考 ...
- Notes of Daily Scrum Meeting(12.18)
前期落下的进度我们会在周六周日赶一下,在编译课程设计中期测试之后集中处理项目中的问题. 今天的任务总结如下: 团队成员 今日团队工作 陈少杰 调试后端连接的部分,寻找bug 王迪 测试搜索功能,修改b ...