强化学习_PolicyGradient(策略梯度)_代码解析
使用策略梯度解决离散action space问题。
一、导入包,定义hyper parameter
import gym
import tensorflow as tf
import numpy as np
from collections import deque #################hyper parameters################、
#discount factor
GAMMA = 0.95
LEARNING_RATE = 0.01
二、PolicyGradient Agent的构造函数:
1、设置问题的状态空间维度,动作空间维度;
2、序列采样的存储结构;
3、调用创建用于策略函数近似的神经网络的函数,tensorflow的session;初始或神经网络的weights和bias。
def __init__(self, env):
#self.time_step = 0
#state dimension
self.state_dim = env.observation_space.shape[0]
#action dimension
self.action_dim = env.action_space.n
#sample list
self.ep_obs, self.ep_as, self.ep_rs = [],[],[]
#create policy network
self.create_softmax_network() self.session = tf.InteractiveSession()
self.session.run(tf.global_variables_initializer())
三、创建神经网络:
这里使用交叉熵误差函数,使用神经网络计算损失函数的梯度。softmax输出层输出每个动作的概率。
tf.nn.sparse_softmax_cross_entropy_with_logits函数先对 logits 进行 softmax 处理得到归一化的概率,将lables向量进行one-hot处理,然后求logits和labels的交叉熵:
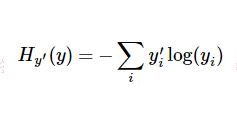
其中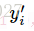
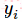
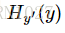
因此,在这里可以得到很好的理解(我自己的理解):当在time-step-i时刻,策略网络输出概率向量若与采样到的time-step-i时刻的动作越相似,那么交叉熵会越小。最小化这个交叉熵误差也就能够使策略网络的决策越接近我们采样的动作。最后用交叉熵乘上对应time-step的reward,就将reward的大小引入损失函数,entropy*reward越大,神经网络调整参数时计算得到的梯度就会越偏向该方向。
def create_softmax_network(self):
W1 = self.weight_variable([self.state_dim, 20])
b1 = self.bias_variable([20])
W2 = self.weight_variable([20, self.action_dim])
b2 = self.bias_variable([self.action_dim]) #input layer
self.state_input = tf.placeholder(tf.float32, [None, self.state_dim])
self.tf_acts = tf.placeholder(tf.int32, [None, ], name='actions_num')
self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value")
#hidden layer
h_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1)
#softmax layer
self.softmax_input = tf.matmul(h_layer, W2) + b2
#softmax output
self.all_act_prob = tf.nn.softmax(self.softmax_input, name='act_prob')
#cross entropy loss function
self.neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.softmax_input,labels=self.tf_acts)
self.loss = tf.reduce_mean(self.neg_log_prob * self.tf_vt) # reward guided loss
self.train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(self.loss) def weight_variable(self, shape):
initial = tf.truncated_normal(shape) #truncated normal distribution
return tf.Variable(initial) def bias_variable(self, shape):
initial = tf.constant(0.01, shape=shape)
return tf.Variable(initial)
四、序列采样:
def store_transition(self, s, a, r):
self.ep_obs.append(s)
self.ep_as.append(a)
self.ep_rs.append(r)
五、模型学习:
通过蒙特卡洛完整序列采样,对神经网络进行调整。
def learn(self):
#evaluate the value of all states in present episode
discounted_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * GAMMA + self.ep_rs[t]
discounted_ep_rs[t] = running_add
#normalization
discounted_ep_rs -= np.mean(discounted_ep_rs)
discounted_ep_rs /= np.std(discounted_ep_rs) # train on episode
self.session.run(self.train_op, feed_dict={
self.state_input: np.vstack(self.ep_obs),
self.tf_acts: np.array(self.ep_as),
self.tf_vt: discounted_ep_rs,
}) self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data
六、训练:
# Hyper Parameters
ENV_NAME = 'CartPole-v0'
EPISODE = 3000 # Episode limitation
STEP = 3000 # Step limitation in an episode
TEST = 10 # The number of experiment test every 100 episode def main():
# initialize OpenAI Gym env and dqn agent
env = gym.make(ENV_NAME)
agent = Policy_Gradient(env) for episode in range(EPISODE):
# initialize task
state = env.reset()
# Train
for step in range(STEP):
action = agent.choose_action(state) # e-greedy action for train
#take action
next_state,reward,done,_ = env.step(action)
#sample
agent.store_transition(state, action, reward)
state = next_state
if done:
#print("stick for ",step, " steps")
#model learning after a complete sample
agent.learn()
break # Test every 100 episodes
if episode % 100 == 0:
total_reward = 0
for i in range(TEST):
state = env.reset()
for j in range(STEP):
env.render()
action = agent.choose_action(state) # direct action for test
state,reward,done,_ = env.step(action)
total_reward += reward
if done:
break
ave_reward = total_reward/TEST
print ('episode: ',episode,'Evaluation Average Reward:',ave_reward) if __name__ == '__main__':
main()
reference:
https://www.cnblogs.com/pinard/p/10137696.html
https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/policy_gradient.py
强化学习_PolicyGradient(策略梯度)_代码解析的更多相关文章
- 强化学习(十三) 策略梯度(Policy Gradient)
在前面讲到的DQN系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习.这种Value Based强化学习方法在很多领域都得到比较好的应用,但是Value Based强化学习方法也有很 ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- java自定义注解学习(三)_注解解析及应用
上篇文章已经介绍了注解的基本构成信息.这篇文章,主要介绍注解的解析.毕竟你只声明了注解,是没有用的.需要进行解析.主要就是利用反射机制在运行时进行查看和利用这些信息 常用方法汇总 在Class.Fie ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 强化学习(十四) Actor-Critic
在强化学习(十三) 策略梯度(Policy Gradient)中,我们讲到了基于策略(Policy Based)的强化学习方法的基本思路,并讨论了蒙特卡罗策略梯度reinforce算法.但是由于该算法 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 强化学习-学习笔记14 | 策略梯度中的 Baseline
本篇笔记记录学习在 策略学习 中使用 Baseline,这样可以降低方差,让收敛更快. 14. 策略学习中的 Baseline 14.1 Baseline 推导 在策略学习中,我们使用策略网络 \(\ ...
- 【论文笔记】AutoML for MCA on Mobile Devices——论文解读与代码解析
理论部分 方法介绍 本节将详细介绍AMC的算法流程.AMC旨在自动地找出每层的冗余参数. AMC训练一个强化学习的策略,对每个卷积层会给出其action(即压缩率),然后根据压缩率进行裁枝.裁枝后,A ...
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
原文地址: https://arxiv.org/pdf/1811.07871.pdf ======================================================== ...
随机推荐
- TypeScript完全解读(26课时)_8.ES6精讲-ES6中的类(进阶)
8.TypeScript完全解读-ES6精讲-类(进阶) 在index.ts内引入 Food创建的实例赋值给Vegetabled这个原型对象,这样使用Vegetables创建实例的时候,就能继承到Fo ...
- shell编程流程控制
前言: 在linux shell中,通常我们将一些命令写在一个文件中就算是一个shell脚本了,但是如果需要执行更为复杂的逻辑判断,我们就需要使用流程控制语句来支持了. 所谓流程控制既是通过使用流程控 ...
- PHP中的常用正则表达式集锦
PHP中的常用正则表达式集锦: 匹配中文字符的正则表达式: [\u4e00-\u9fa5] 评注:匹配中文还真是个头疼的事,有了这个表达式就好办了 匹配双字节字符(包括汉字在内):[^\x00-\xf ...
- 使用fastadmin的页面跳转模板
1.效果图 2.修改tp默认跳转模板文件( /thinkphp/tpl/dispatch_jump.tpl ),将文件中的内容全部替换成下面的内容然后保存即可,注意替换语言包和图片路径 {__NOLA ...
- POJ1111【BFS】
在搜1011的时候误搜了1111,简单BFS吧,多一个X就是多四个面,每次看看他的四个面有多少个重复的,然后剪掉,最后答案加上就好了: code: //#include <bits/stdc++ ...
- VR相关学习资源
ptgui全景图制作工具 http://blog.csdn.net/xoyojank mems陀螺误差补偿的算法研究 http://www.docin.com/p-619540171.html 极客工 ...
- route(2018.10.24)
建出最短路图之后\(topsort\)即可. 具体思路: 先用\(dijkstra\)算法在原图中跑出\(1\)号点到\(i\)号节点的最短距离\(dist_1(i)\),将所有边反向后用\(dijk ...
- win10怎么修改DNS
方法/步骤 1 鼠标右键桌面单击此电脑--属性,如下图所示 2 进入电脑属性,选择控制面板主页,如下图所示 3 我们继续选择网络和Internet进入,如下图所示 4 进入网络和Internet, ...
- __slots__,__doc__,__module__,__class__.__call__
__slots__ 1.__slots__是什么:是一个类变量,变量值可以是列表,元祖,或者可迭代对象,也可以是一个字符串(意味着所有实例只有一个数据属性)2.引子:使用点来访问属性本质就是在访问类或 ...
- [POJ1463] Strategic game
题目链接: 传送门 题目大意: Bob非常享受玩电脑游戏的过程,尤其是策略游戏,但是在有些时候,他因为不能在第一时间找到最佳的策略而十分伤心. 现在,他遇到了一个问题.他必须保卫一个中世纪的城市,有很 ...