阿里巴巴大规模应用Flink的踩坑经验:如何大幅降低 HDFS 压力?
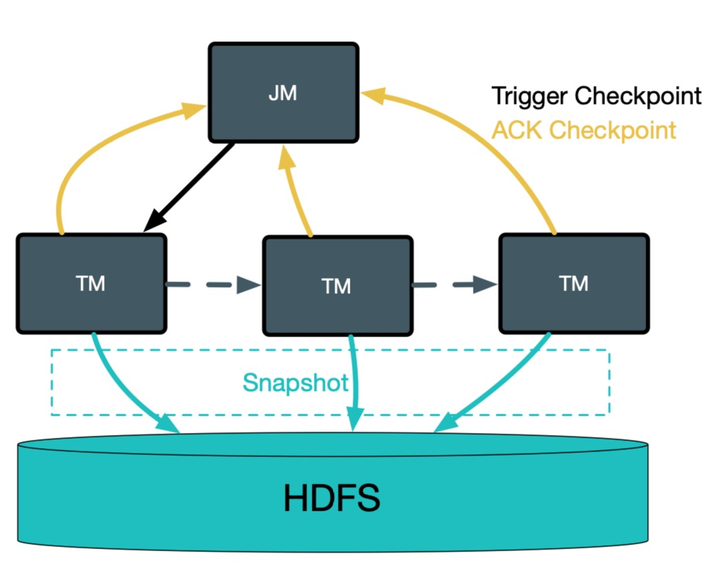
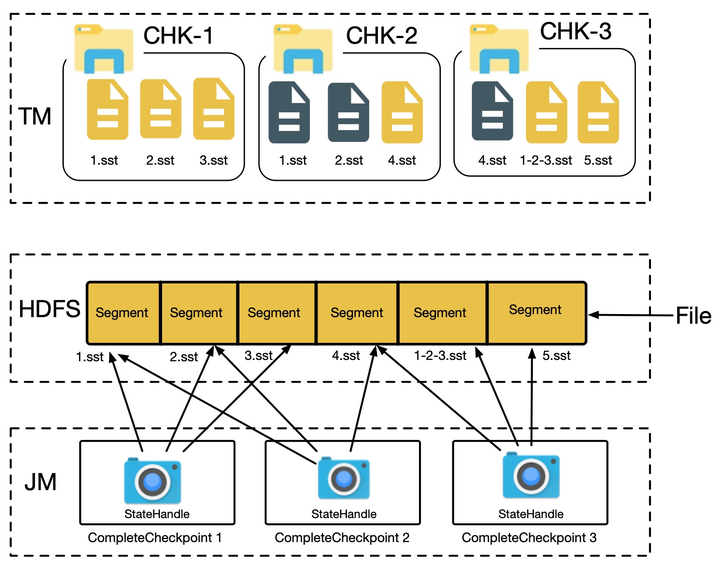
- 并发 checkpoint 的支持 Flink 天生支持并发 checkpoint,小文件合并方案则会将多个文件写往同一个分布式存储文件中,如果考虑不当,数据会写串或者损坏,因此我们需要有一种机制保证该方案的正确性,详细描述参考 2.1 节
- 防止误删文件 我们使用引用计数来记录文件的使用情况,仅通过文件引用计数是否降为 0 进行判断删除,则可能误删文件,如何保证文件不会被错误删除,我们将会在 2.2 节进行阐述
- 降低空间放大 使用小文件合并之后,只要文件中还有一个 statehandle 被使用,整个分布式文件就不能被删除,因此会占用更多的空间,我们在 2.3 节描述了解决该问题的详细方案
- 异常处理 我们将在 2.4 节阐述如何处理异常情况,包括 JM 异常和 TM 异常的情况
- 2.5 节中会详细描述在 Checkpoint 被取消或者失败后,如何取消 TM 端的 Snapshot,如果不取消 TM 端的 Snapshot,则会导致 TM 端实际运行的 Snapshot 比正常的多
- TM 端 barrier 对齐
- TM Snapshot 同步操作
- TM Snapshot 异步操作
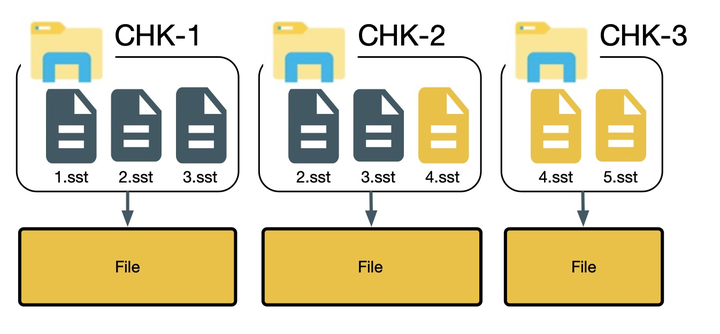
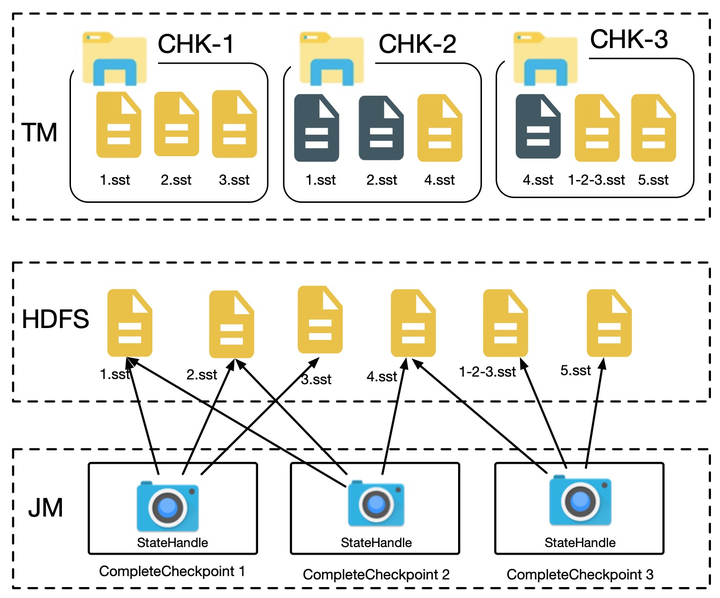
- 计算每个文件的放大率
- 如果放大率较小则直接跳到步骤 7
- 如果文件 A 的放大率超过阈值,则生成一个对应的新文件 A‘(如果这个过程中创建文件失败,则由 TM 负责清理工作)
- 记录 A 与 A’ 的映射关系
- 在下一次 checkpoint X 往 JM 发送落在文件 A 中的 StateHandle 时,则使用 A` 中的信息生成一个新的 StateHandle 发送给 JM
- checkpoint X 完成后,我们增加 A‘ 的引用计数,减少 A 的引用计数,在引用计数降为 0 后将文件 A 删除(如果 JM 增加了 A’ 的引用,然后出现异常,则会从上次成功的 checkpoint 重新构建整个引用计数器)
- 文件压缩完成
- 文件已经汇报过给 JM 文件汇报过给 JM,因此在 JM 端有文件的引用计数,文件的删除由 JM 控制,当文件的引用计数变为 0 之后,JM 将删除该文件。
- 文件尚未汇报给 JM 该文件暂时尚未汇报过给 JM,该文件不再被使用,也不会被 JM 感知,成为孤儿文件。这种情况暂时有外围工具统一进行清理。
- 每个 TM 分到自己需要 restore 的 state handle
- TM 从远程下载 state handle 对应的数据
- 从本地进行恢复
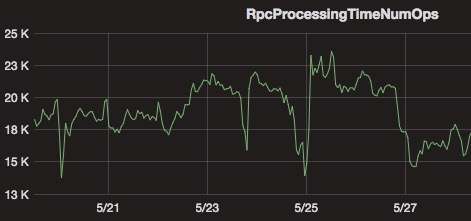
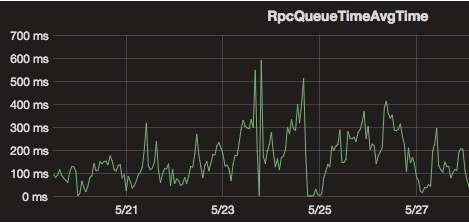
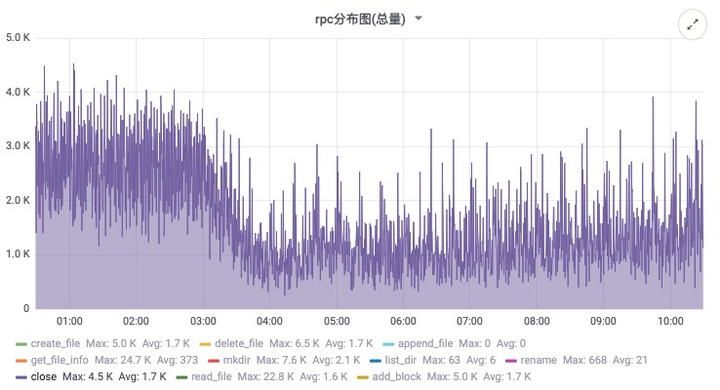
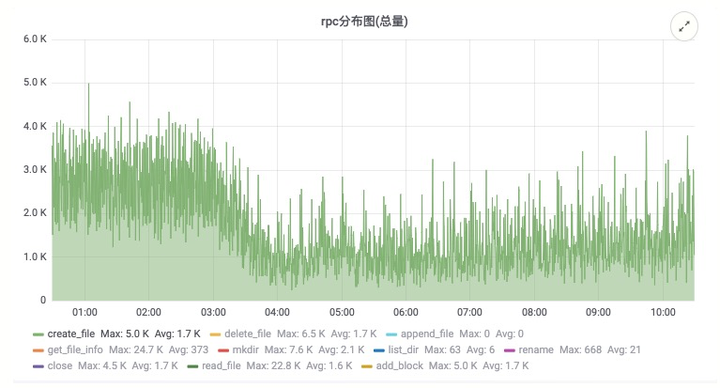
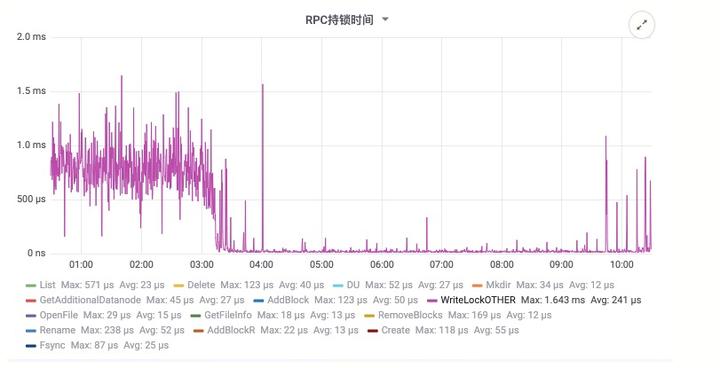
- 优势:大幅度降低 HDFS 的压力:包括 RPC 压力以及 NameNode 内存的压力
- 不足:不支持 State 多线程上传的功能(State 上传暂时不是 checkpoint 的瓶颈)
阿里巴巴大规模应用Flink的踩坑经验:如何大幅降低 HDFS 压力?的更多相关文章
- 程序员的踩坑经验总结(一):如何把Bug的偶现变必现
程序员的踩过的坑也是可以分类的,很常见又很难解决的一类是偶然的现象,表现起来比较怪异. 而把一个问题Bug的偶现变成必现,是开发人员的一种能力.我认为也应该是测试人员的一种能力,但是各个公司要求不一样 ...
- 微信jssdk批量添加卡券接口(踩坑经验)
1)首先是官方接口文档: 1.批量添加卡券接口:https://mp.weixin.qq.com/wiki?action=doc&id=mp1421141115&t=0.0861973 ...
- SpringCloud整合过程中jar依赖踩坑经验
今天在搭建SpringCloud Eureka过程中,一直在报pom依赖错误,排查问题总结如下经验. 1.SpringBoot整合SpringCloud两者版本是有严格约束的,详细见SpringBoo ...
- TensorFlow保存、加载模型参数 | 原理描述及踩坑经验总结
写在前面 我之前使用的LSTM计算单元是根据其前向传播的计算公式手动实现的,这两天想要和TensorFlow自带的tf.nn.rnn_cell.BasicLSTMCell()比较一下,看看哪个训练速度 ...
- 踩坑经验总结之go web开源库第一次编译构建
前言:记录一个go新手第一次构建复杂开源库的经历.go虽然是新手,但是编程上还是有多年的经验,除了c/c++,用过IDEA能进行简单的java编程.甚至scala编程.所以最开始还是有点信心的.所以也 ...
- 攻城记:Thinkphp框架的项目规划总结和踩坑经验
一.项目模块规划 1.项目分为PC端.移动端.和PC管理端,分为对应目录为 /Application/Home,/Application/Mobile,/Application/Admin: 对应入口 ...
- Nodejs 8.0 踩坑经验汇总
.Linq:Linq to sql 类 高度集成化的数据库访问技术 使用Linq是应该注意的问题: 1.创建Linq连接后生成的dbml文件不要变动,生成的表不要碰,拖动表也会造成数据库连接发生变动, ...
- 【转】Thinkphp框架的项目规划总结和踩坑经验
http://www.360doc.com/content/16/1206/22/466494_612576533.shtml
- html2canvas以及domtoimage的使用踩坑总结
前言 首先做个自我介绍,我是成都某企业的一名刚刚入行约一年的前端,在之前的开发过程中,遇到了问题,也解决了问题,但是在下一次解决相同问题的时候,只对这个问题有一丝丝的印象,还需要从新去查找,于是,我注 ...
- Abp vnext EFCore 实现动态上下文DbSet踩坑记
背景 我们在用EFCore框架操作数据库的时候,我们会遇到在 xxDbContext 中要写大量的上下文 DbSet<>; 那我们表少还可以接受,表多的时候每张表都要写一个DbSet, 大 ...
随机推荐
- 基于stm32H730的解决方案开发之freertos系统解析
一 概述 在嵌入式小系统领域,freertos是一个非常厉害的角色.它和小芯片结合,能迸发出非常大的威力.这里在H730上使用了这个freertos,是应该做一个总结和备忘. 二 实例解析 1 线程初 ...
- SparseTable ST表
Sparse Table ST表是一个静态二维数组st[i][j],作用是快速查询(O(1))区间最值(不只是最值,可重复贡献问题都可以用),st[i][j]代表的是在以引索i为起点,长度为\(2^j ...
- 24_用Qt和FFmpeg实现简单的YUV播放器
前面文章FFmpeg像素格式转换中我们使用FFmpeg实现了一个像素格式转换工具类,现在我们就可以在Qt中利用QImage很容易的实现一个简单的YUV播放器了. 播放器功能很简单,只有播放.暂停和停止 ...
- 谷歌Linux 运维工程师面试真题
谷歌Linux 运维工程师面试真题 下面是谷歌 Linux 运维工程师面试真题: 1.如何查看当前的 Linux 服务器的运行级别? 答: 'who -r' 和 'runlevel' 命令可以用来查看 ...
- 手把手制作mobileconfig文件,在iphone上创建h5网页桌面图标
1,下载mobileconfig文件制作工具 下载地址:点击关注公众号,回复appicon, 获取工具的下载地址 新建配置描述文件,填写通用信息 填写Web Clip信息 点击菜单栏的导出,注意这里一 ...
- fs.1.10 ON CENTOS7 docker镜像制作
概述 freeswitch是一款简单好用的VOIP开源软交换平台. centos7 docker上编译安装fs1.10版本的流程记录. 环境 docker engine:Version 24.0.6 ...
- KingbaseES创建外键与Mysql的差异
Mysql mysql> select version(); +-----------+ | version() | +-----------+ | 8.0.23 | +-----------+ ...
- KingbaseES V8R6 运维案例之---数据库连接访问故障分析
KingbaseES V8R6运维案例之---数据库连接访问故障分析 案例说明: 在部署KingbaseES V8R6后,正常启动数据库服务,但是通过ksql连接数据库服务访问时,出现连接到postg ...
- linux下firefox用css配置把网页设置成黑白
网址输入 about:config 忽略警告 toolkit.legacyUserProfileCustomizations.stylesheets设置为true 在 /home/user/.mozi ...
- #分治,Dijkstra#洛谷 3350 [ZJOI2016]旅行者
题目 给定一张\(n*m\)的网格图,\(q\)次询问两点之间距离 \(n*m\leq 2*10^4,q\leq 10^5\) 分析 首先floyd会TLE,考虑两点间距离可以由两段拼凑起来, 那么枚 ...