[转帖]Kubernetes1.25.6部署文档 使用cri-docker部署K8s1.25.6
https://zhuanlan.zhihu.com/p/600808149
本文档将通过kubeadm+docker部署K8s集群,本次集群使用的容器运行工具为docker,K8s的容器运行工具也可以用除docker之外的、containerd、cio等等,在K8s的1.24版本以后移除了docker-shim,而Docker Engine默认不支持CRI规范,因而二者将无法直接完成整合,因此,Mirantis和Docker联合创建了cri-dockerd项目,用于为Docker Engine提供一个能够支持到CRI规范的垫片,从而能够让Kubernetes基于CRI控制Docker ,所以想在1.24版本及以后的版本中使用docker部署K8s集群,需要安装cri-dockerd
环境准备
准备3台服务器,虚拟机也行,每台主机的CPU要在2核心以上,RAM 2GB以上,否则后续初始化K8s时会不通过。
| 主机名 | IP | CPU | 内存 |
|---|---|---|---|
| http://master.example.com | 172.25.80.10 | 4核心 | 8GB |
| http://node1.example.com | 172.25.80.11 | 4核心 | 8GB |
| http://node2.example.com | 172.25.80.12 | 4核心 | 8GB |
环境搭建
系统环境初始化
(所有节点同时操作)
配置主机名
hostnamectl set-hostname master.example.com && bash
hostnamectl set-hostname node1.example.com && bash
hostnamectl set-hostname node2.example.com && bash配置Hosts文件解析
Edit /etc/hosts
172.25.80.10 master master.example.com
172.25.80.11 node1 node1.example.com
172.25.80.12 node2 node2.example.com关闭SELINUX以及swap
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config配置YUM仓库
备份原有YUM仓库配置文件并下载docker,K8s的仓库文件
cd /etc/yum.repos.d/
mkdir back && mv *.repo back
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum clean all && yum makecache fast调整内核参数
将桥接的IPV4流量传递到iptables的链同一节点的不同pod,利用linux bridge进行二层通讯,由于没有原路返回造成pod请求services时的session无法收到返回值而连接超时,所以需要设置让第二层的bridge在转发时也通过第三层的iptables进行通信,并禁止使用swap,只有当系统 OOM 时才允许使用它
cat <<EOF> /etc/sysctl.d/kubernetes.conf
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
modprobe br_netfilter &&
sysctl -p /etc/sysctl.d/kubernetes.conf配置时区,时间同步
配置时区
timedatectl set-timezone Asia/Shanghai
timedatectl set-local-rtc 0
systemctl restart rsyslog
systemctl restart crondNTP时间同步(采用chrony)
yum remove -y ntp ntpdate
yum -y install chronyEdit /etc/chrony.conf
注释掉原先配置,并将时间服务器更改为阿里云服务器
https://help.aliyun.com/document_detail/92704.html
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server ntp.aliyun.com iburst
systemctl enable --now chronyd #启动该服务并设置为开启启动验证 (带* 表示同步成功)
chronyc sources -v
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* 203.107.6.88 2 6 7 1 -1258us[+28752s] +/- 19ms配置防火墙
设置防火墙为 Iptables 并设置空规则
systemctl stop firewalld && systemctl disable firewalld
yum -y install iptables-services && systemctl start iptables && systemctl enable
iptables -F && iptables-save开启ipvs
不开启ipvs将会使用iptables,但是效率低,所以官网推荐需要开通ipvs内核
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in \${ipvs_modules}; do
/sbin/modinfo -F filename \${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe \${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs配置持久化
mkdir /var/log/journal
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间 10G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间 2 周
MaxRetentionSec=2week
# 不将日志转发到 syslog
ForwardToSyslog=no
EOF
systemctl restart systemd-journald安装Docker并配置镜像加速
(所有节点同时操作)
如需指定版本可以使用
yum list docker-ce --showduplicates | sort -r查看版本信息通过yum -y install docker-ce-18.0.3安装
yum install -y vim yum-utils device-mapper-persistent-data lvm2
yum install -y docker-ce配置Docker镜像加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://vwlrpbcp.mirror.aliyuncs.com"]
}
EOF
systemctl daemon-reload && systemctl restart docker && systemctl enable --now docker安装cri-docker 使kubernetes以docker作为运行时 (因为github速度慢,这边把rpm包镜像到自己服务器了)
https://github.com/Mirantis/cri-dockerd/releases/
yum localinstall -y http://opt.itwk.cc/rpm/el7/cri-dockerd-0.2.6-3.el7.x86_64.rpm修改service文件
Edit /usr/lib/systemd/system/cri-docker.service
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.8 --container-runtime-endpoint
systemctl daemon-reload && systemctl enable --now cri-docker cri-docker.socket安装K8S
yum install -y kubelet-1.25.2 kubeadm-1.25.2 kubectl-1.25.2
systemctl enable kubelet部署Master节点
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
kubeadm init --kubernetes-version=v1.25.6 --pod-network-cidr=10.224.0.0/16 --apiserver-advertise-address=172.25.80.10 --cri-socket unix:///var/run/cri-dockerd.sock --image-repository=registry.aliyuncs.com/google_containers部署成功; 按照日志说明进行配置
根据日志的提示创建文件夹
mkdir -p $HOME/.kube根据日志的提示把配置文件复制进刚刚新创建的文件夹里
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config根据日志的提示输入以下命令
chown $(id -u):$(id -g) $HOME/.kube/config安装 Pod 网络插件(CNI)
wget https://docs.projectcalico.org/manifests/calico.yaml
kubectl apply -f calico.yaml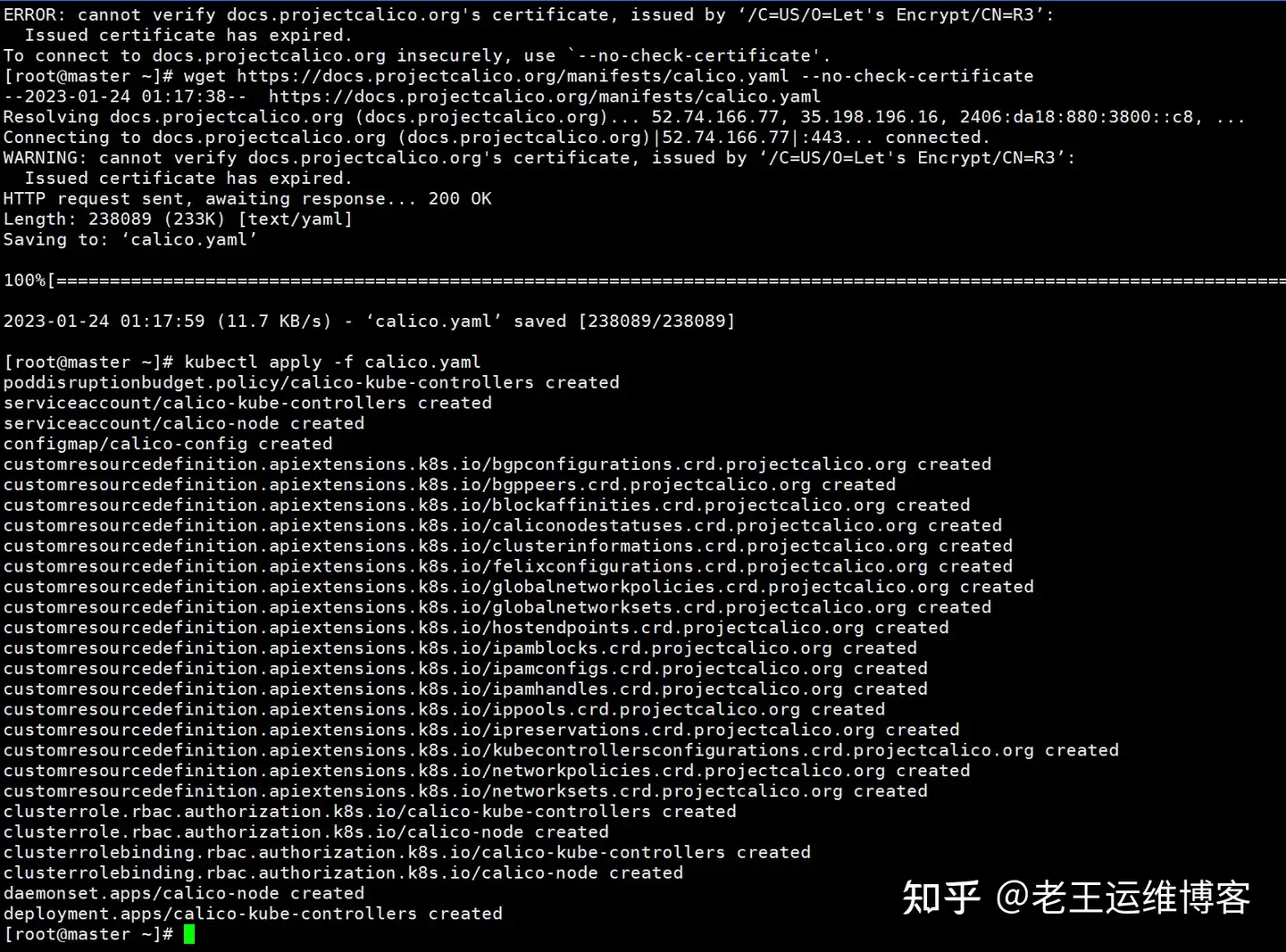
Node节点部署
根据提示把node节点加如到master节点中,复制你们各自在日志里的提示,然后分别粘贴在2个node节点上,最后回车即可(注意要在后面加上--cri-socket unix:///var/run/cri-dockerd.sock这一参数,不然会失败)
如下图所示,最终提示"This node has joined the cluster" 即为成功

[转帖]Kubernetes1.25.6部署文档 使用cri-docker部署K8s1.25.6的更多相关文章
- tomcat+memcached+nginx部署文档(附完整部署包直接运行即可)
1 前言 1.1 目的 为了正确的部署“ngix+memcached”特编写此部署手册,使安装人员可以通过部署手册知道如何部署系统,也为需要安装该系统的安装人员正确.快速的部署本系统提供帮助. 1.2 ...
- hadoop2.6.0汇总:新增功能最新编译 32位、64位安装、源码包、API下载及部署文档
相关内容: hadoop2.5.2汇总:新增功能最新编译 32位.64位安装.源码包.API.eclipse插件下载Hadoop2.5 Eclipse插件制作.连接集群视频.及hadoop-eclip ...
- CDH简易离线部署文档
CDH 离线简易部署文档 文档说明 本文为开发部署文档,生产环境需做相应调整. 以下操作尽量在root用户下操作,避免权限问题. 目录 文档说明 2 文档修改历史记录 2 目录 3 ...
- HDFS NameNode HA 部署文档
简介: HDFS High Availability Using the Quorum Journal Manager Hadoop 2.x 中,HDFS 组件有三个角色:NameNode.DataN ...
- PPTP部署文档
PPTP部署文档 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 欢迎加入:高级运维工程师之路 598432640 前言:这款VPN部署起来特别简单,想对OPENVON配 ...
- B3log部署文档
https://github.com/b3log/solo/wiki/standalone_mode 独立模式 只要已经安装好了 Java 环境,一个命令就能启动! 不依赖 MySQL 数据库,而是使 ...
- supervisor 部署文档
supervisor 部署文档 supervisor 需要Python支持,如果不用系统的supervisor,单独安装python python 安装 #依赖 yum install python- ...
- centos6 Cacti部署文档
centos6 Cacti部署文档 1.安装依赖 yum -y install mysql mysql-server mysql-devel httpd php php-pdo php-snmp ph ...
- HP DL160 Gen9服务器集群部署文档
HP DL160 Gen9服务器集群部署文档 硬件配置=======================================================Server Memo ...
- Sqlserver2008安装部署文档
Sqlserver2008部署文档 注意事项: 如果你要安装的是64位的服务器,并且是新机器.那么请注意,你需要首先需要给64系统安装一个.net framework,如果已经安装此功能,请略过这一步 ...
随机推荐
- 云MSP技本功|redis的5种对象与8种数据结构之字符串对象(下)
简介: 引言 本文是对<redis设计与实现(第二版)>中数据结构与对象相关内容的整理与说明.本篇文章只对对象结构,1种对象--字符串对象.以及字符串对象所对应的两种编码--raw和emb ...
- 心理健康数据集:mental_health_chatbot_dataset
一.数据集描述 1.数据集摘要 该数据集包含与心理健康相关的问题和答案的对话对,以单一文本形式呈现.数据集是从流行的医疗博客(如WebMD.Mayo Clinic和HealthLine).在线常见 ...
- DTT年度收官圆桌π,华为云8位技术专家的年末盘点
摘要:收下这份DTT年度收官圆桌π总结,在新的一年心想事成,技术上更上一层楼. 本文分享自华为云社区<DTT年度收官圆桌π,华为云8位技术专家的年末盘点>,作者:华为云社区精选 . 在20 ...
- openGauss内核分析:SQL by pass & 经典执行器
摘要:执行引擎一般负责查询的执行,执行引擎在SQL执行栈中起到接收优化器生成的执行计划Plan.并对通过存储引擎提供的数据读写接口,实现对数据进行计算得到查询的结果集. 本文分享自华为云社区<o ...
- Spring中部署Activiti流程定义的三种姿势
摘要:本文对工作流Activiti框架中流程定义的部署进行了详细说明介绍. 本文分享自华为云社区<项目中工作流部署详细解析!Spring中部署Activiti流程定义的三种姿势>,作者:攻 ...
- SpringBoot java 一个接口,多个实现,客户定制化
产品定制化时,在不同的客户中会有不同的需求,这时候会产生,一个接口,多个实现 SpringBoot ,如果发现有多实现时,会报如下错误 Consider marking one of the bean ...
- selenium-web自动化(po模型)
什么是po模型呢?简单理解就是:把每个页面当成一个对象,给这些页面当成一个类,主要就是完成元素定位和业务操作:把它和测试脚本区分开来,需要什么取这些页面类去调用即可.这样的好处在于页面元素发生变化时, ...
- 初识Selenium自动化(为什么要去用自动化?)
什么是自动化测试 让程序代替人去验证程序功能的过程 自动化测试就是把以人为驱动的测试行为转化为机器执行的一种过程 比如说:我们设计好执行脚本,通过驱动连接浏览器去模拟人去操作浏览器一般 为什么要进行自 ...
- python 使用 Google Gemini API
python 使用 Google Gemini API 注册APIKEY : Google AI Studio [免费] import base64 import requests import js ...
- Python | 解放双手,用Python实现自动发送邮件
解放双手,用Python实现自动发送邮件 使用Python实现自动化邮件发送,可以让你摆脱繁琐的重复性业务,节省非常多的时间. Python有两个内置库:smtplib和email,能够实现邮件功能, ...