神经网络基础篇:详解logistic 损失函数(Explanation of logistic regression cost function)
详解 logistic 损失函数
在本篇博客中,将给出一个简洁的证明来说明逻辑回归的损失函数为什么是这种形式。
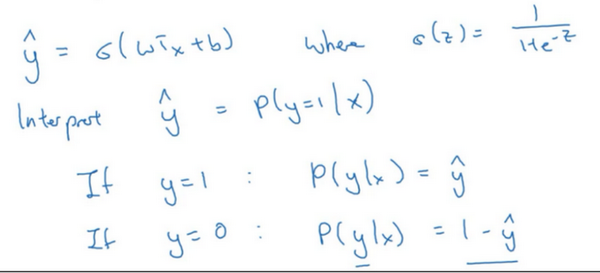
回想一下,在逻辑回归中,需要预测的结果\(\hat{y}\),可以表示为\(\hat{y}=\sigma(w^{T}x+b)\),\(\sigma\)是熟悉的\(S\)型函数 \(\sigma(z)=\sigma(w^{T}x+b)=\frac{1}{1+e^{-z}}\) 。约定 \(\hat{y}=p(y=1|x)\) ,即算法的输出\(\hat{y}\) 是给定训练样本 \(x\) 条件下 \(y\) 等于1的概率。换句话说,如果\(y=1\),在给定训练样本 \(x\) 条件下\(y=\hat{y}\);反过来说,如果\(y=0\),在给定训练样本\(x\)条件下 \(y\) 等于1减去\(\hat{y}(y=1-\hat{y})\),因此,如果 \(\hat{y}\) 代表 \(y=1\) 的概率,那么\(1-\hat{y}\)就是 \(y=0\)的概率。接下来,就来分析这两个条件概率公式。
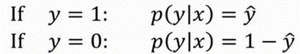
这两个条件概率公式定义形式为 \(p(y|x)\)并且代表了 \(y=0\) 或者 \(y=1\) 这两种情况,可以将这两个公式合并成一个公式。需要指出的是讨论的是二分类问题的损失函数,因此,\(y\)的取值只能是0或者1。上述的两个条件概率公式可以合并成如下公式:
\(p(y|x)={\hat{y}}^{y}{(1-\hat{y})}^{(1-y)}\)
接下来会解释为什么可以合并成这种形式的表达式:\((1-\hat{y})\)的\((1-y)\)次方这行表达式包含了上面的两个条件概率公式,现在来解释一下为什么。
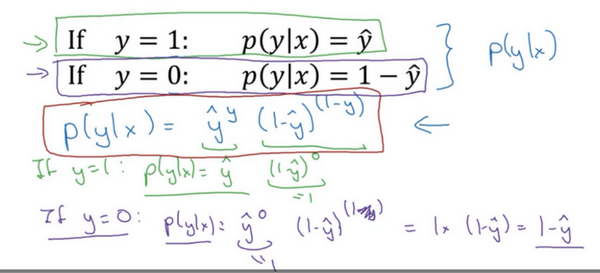
第一种情况,假设 \(y=1\),由于\(y=1\),那么\({(\hat{y})}^{y}=\hat{y}\),因为 \(\hat{y}\)的1次方等于\(\hat{y}\),\(1-{(1-\hat{y})}^{(1-y)}\)的指数项\((1-y)\)等于0,由于任何数的0次方都是1,\(\hat{y}\)乘以1等于\(\hat{y}\)。因此当\(y=1\)时 \(p(y|x)=\hat{y}\)(图中绿色部分)。
第二种情况,当 \(y=0\) 时 \(p(y|x)\) 等于多少呢?
假设\(y=0\),\(\hat{y}\)的\(y\)次方就是 $$\hat{y}$$ 的0次方,任何数的0次方都等于1,因此 \(p(y|x)=1×{(1-\hat{y})}^{1-y}\) ,前面假设 \(y=0\) 因此\((1-y)\)就等于1,因此 \(p(y|x)=1×(1-\hat{y})\)。因此在这里当\(y=0\)时,\(p(y|x)=1-\hat{y}\)。这就是这个公式(第二个公式,图中紫色字体部分)的结果。
因此,刚才的推导表明 \(p(y|x)={\hat{y}}^{(y)}{(1-\hat{y})}^{(1-y)}\),就是 \(p(y|x)\) 的完整定义。由于 log 函数是严格单调递增的函数,最大化 \(log(p(y|x))\) 等价于最大化 \(p(y|x)\) 并且地计算 \(p(y|x)\) 的 log对数,就是计算 \(log({\hat{y}}^{(y)}{(1-\hat{y})}^{(1-y)})\) (其实就是将 \(p(y|x)\) 代入),通过对数函数化简为:
\(ylog\hat{y}+(1-y)log(1-\hat{y})\)
而这就是前面提到的损失函数的负数 \((-L(\hat{y},y))\) ,前面有一个负号的原因是当训练学习算法时需要算法输出值的概率是最大的(以最大的概率预测这个值),然而在逻辑回归中需要最小化损失函数,因此最小化损失函数与最大化条件概率的对数 \(log(p(y|x))\) 关联起来了,因此这就是单个训练样本的损失函数表达式。
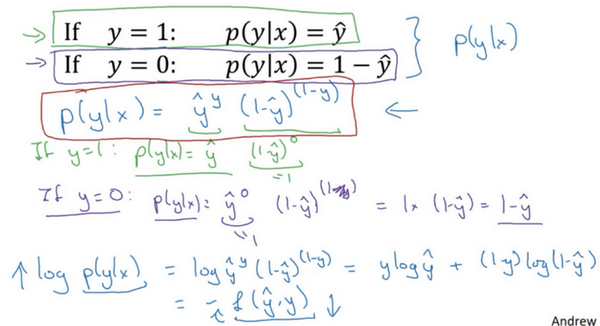
在 \(m\)个训练样本的整个训练集中又该如何表示呢。
整个训练集中标签的概率,更正式地来写一下。假设所有的训练样本服从同一分布且相互独立,也即独立同分布的,所有这些样本的联合概率就是每个样本概率的乘积:
\(P\left(\text{labels in training set} \right) = \prod_{i =1}^{m}{P(y^{(i)}|x^{(i)})}\)。
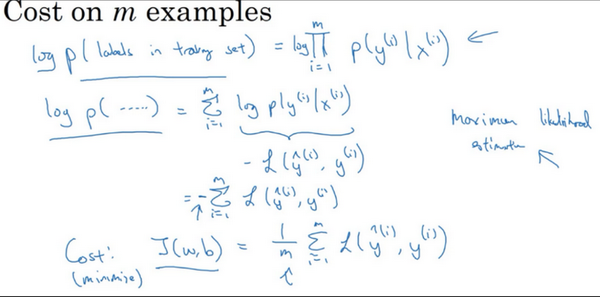
如果想做最大似然估计,需要寻找一组参数,使得给定样本的观测值概率最大,但令这个概率最大化等价于令其对数最大化,在等式两边取对数:
\(logp\left( \text{labels in training set} \right) = log\prod_{i =1}^{m}{P(y^{(i)}|x^{(i)})} = \sum_{i = 1}^{m}{logP(y^{(i)}|x^{(i)})} = \sum_{i =1}^{m}{- L(\hat y^{(i)},y^{(i)})}\)
在统计学里面,有一个方法叫做最大似然估计,即求出一组参数,使这个式子取最大值,也就是说,使得这个式子取最大值,\(\sum_{i= 1}^{m}{- L(\hat y^{(i)},y^{(i)})}\),可以将负号移到求和符号的外面,\(- \sum_{i =1}^{m}{L(\hat y^{(i)},y^{(i)})}\),这样就推导出了前面给出的logistic回归的成本函数\(J(w,b)= \sum_{i = 1}^{m}{L(\hat y^{(i)},y^{\hat( i)})}\)。
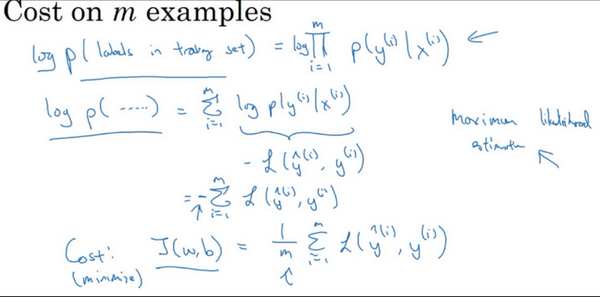
由于训练模型时,目标是让成本函数最小化,所以不是直接用最大似然概率,要去掉这里的负号,最后为了方便,可以对成本函数进行适当的缩放,就在前面加一个额外的常数因子\(\frac{1}{m}\),即:\(J(w,b)= \frac{1}{m}\sum_{i = 1}^{m}{L(\hat y^{(i)},y^{(i)})}\)。
总结一下,为了最小化成本函数\(J(w,b)\),从logistic回归模型的最大似然估计的角度出发,假设训练集中的样本都是独立同分布的条件下。
神经网络基础篇:详解logistic 损失函数(Explanation of logistic regression cost function)的更多相关文章
- JavaScript基础篇详解
全部的数据类型: 基本数据类型: undefined Number Boolean null String 复杂数据类型: object ①Undefined: >>>声明但未初始化 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- Python基础知识详解 从入门到精通(七)类与对象
本篇主要是介绍python,内容可先看目录其他基础知识详解,欢迎查看本人的其他文章Python基础知识详解 从入门到精通(一)介绍Python基础知识详解 从入门到精通(二)基础Python基础知识详 ...
- I2C 基础原理详解
今天来学习下I2C通信~ I2C(Inter-Intergrated Circuit)指的是 IC(Intergrated Circuit)之间的(Inter) 通信方式.如上图所以有很多的周边设备都 ...
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- 【原创 深度学习与TensorFlow 动手实践系列 - 3】第三课:卷积神经网络 - 基础篇
[原创 深度学习与TensorFlow 动手实践系列 - 3]第三课:卷积神经网络 - 基础篇 提纲: 1. 链式反向梯度传到 2. 卷积神经网络 - 卷积层 3. 卷积神经网络 - 功能层 4. 实 ...
- RabbitMQ基础知识详解
什么是MQ? MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取队列中 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- Nmap扫描教程之基础扫描详解
Nmap扫描教程之基础扫描详解 Nmap扫描基础扫描 当用户对Nmap工具了解后,即可使用该工具实施扫描.通过上一章的介绍,用户可知Nmap工具可以分别对主机.端口.版本.操作系统等实施扫描.但是,在 ...
随机推荐
- C#学习笔记--逻辑语句(分支和循环)
逻辑语句 条件分支语句 条件分支语句可以让顺序执行的代码逻辑产生分支,满足对应条件地执行对应代码逻辑. IF语句 //IF语句块 int a=5; if(a>0&&a<15 ...
- Python - 读取CSV文件发现有重复数据,如何清洗以及保存为CSV文件,这里有完整的过程!!!! 片尾有彩蛋
语言:Python 功能: 1.清洗CSV文件中重复数据. 2.保存为CSV文件 大体流程: 1.首先观察CSV文件中的数据布局格式如何? 2.通过csv包读取数据.并根据规则使用continue,来 ...
- linux- 挂载本地iso,配置本地yum
------------------------------------ 关于centos8安装vm-tools: workstation部署centos8之后,不需要单独安装vm-tools,系统已 ...
- meet
以后就放弃csdn了,就来这里记录自己的成长,就当成一个树洞吧,开心与难过,学习与生活,进步与成长,留下时间的痕迹!冲!冲!冲!
- LVS负载均衡群集——其一
LVS负载均衡群集 一.LVS简介 LVS(Linux Virtual Server)即Linux虚拟服务器,是由章文嵩博士主导的开源负载均衡项目,目前LVS已经被集成到Linux内核模块中.该项目在 ...
- List 切割成小 list 分批处理数据
使用 Google Guava 库中的方法对 bmList 进行分割. Lists.partition() 方法用于将一个列表按指定大小进行分割,返回一个包含分割后子列表的新列表. 在这个例子中,bm ...
- 虚拟机centos7上安装docker+jenkins
虚拟机centos7上安装docker+jenkins 学习某册子的CICD时,安装了docker和jenkins,记录的安装过程和中间碰到的问题. 使用的虚拟机为Parallels Desktop, ...
- 代码安全之代码混淆及加固(Android)🔒
代码安全之代码混淆及加固(Android) 目录 代码安全之代码混淆及加固(Android) 摘要 引言 正文 代码混淆 代码加固 总结 参考资料 摘要 本文将介绍如何通过代码混淆和加固来保护An ...
- 如何通过C++ 给PDF文档添加文字水印
因PDF文档具有较好的稳定性和兼容性,现在越来越多的合同.研究论文.报告等都采用PDF格式.为了进一步保护这些重要文档内容免受未经授权的复制或使用,我们可以添加水印以表明其状态.所有权或用途.针对工作 ...
- Why Microservices ?
微服务(Microservices)是一种软件架构设计风格,其中应用程序由一组小型.独立.自治的服务组成,这些服务共同工作以构建整体应用.每个服务都专注于一个特定的业务功能,可以独立部署.扩展和维护. ...