聚焦企业数据生命周期全链路 火山引擎数智平台 VeDI 发布《数据智能知识图谱》
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
近日,火山引擎数智平台(VeDI)正式发布《数据智能知识图谱》(以下简称「图谱」),内容覆盖了包括数据存储计算、数据分析加速、数据研发治理、数据洞察分析,数据辅助决策、数据赋能营销等企业数据全生命周期的管理与应用。
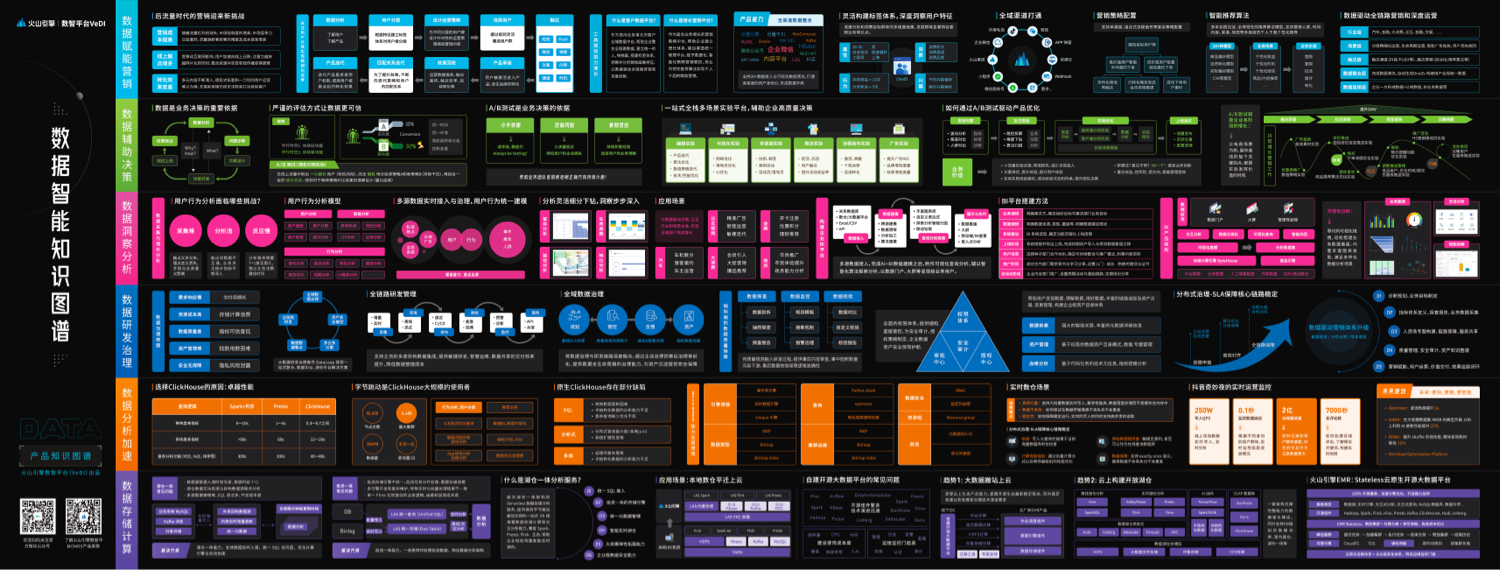
更强劲的数据基座能力
随着企业数字化转型的需求愈加强烈,数据存储计算作为转型最底层的基座也更加受到关注。过去,传统湖仓一体时常发生数据源数据入湖时效性差、多源数据管理难等问题;而在批流一体方面,由于批流存储引擎不统一导致批流任务分开处理、数据存储浪费,以及单一 Flink 实现复杂的业务逻辑,运维和回溯成本高等问题也令企业头痛不已。为了帮助企业更好解决这些问题,火山引擎 VeDI 推出了湖仓一体分析服务 LAS,为企业提供源自字节跳动最佳实践的一站式 EB 级海量数据存储计算和交互分析能力。
此外,针对企业面临的:自建开源大数据平台常见的组件繁多且演进迅速、建设使用成本高、运维监控门槛高等问题。云原生开源大数据平台 E-MapReduce(简称 EMR)还能提供 100%开源兼容的大数据生态组件和丰富的运维管控能力,配合智能化的冷热数据分层存储和 Stateless 瞬态集群能力,帮助企业在大数据基建领域进一步降本提效。
考虑到部分企业对数据实时分析的加速需求,火山引擎 VeDI 还推出云原生数据仓库 ByteHouse。2017 年,字节跳动大规模启用 ClickHouse,并拥有着大规模 ClickHouse 集群。在持续使用过程中,字节跳动应对了诸多挑战并将每一次经验加以沉淀,在 2021 年 8 月正式发布 ByteHouse,并通过火山引擎对外服务。
从架构上来看,火山引擎 ByteHouse 与其他同类型产品相比,采用了自研的高可用引擎,支持数据实时更新、删除,新增了自研的查询优化器,并且在集群的运维和多表关联的场景都做了相应的增强;另一方面,全自研的查询优化能力,让 ByteHouse 可以保证用户在复杂查询的场景下具备更高的查询效能,这对重视实时数仓能力的用户来说,尤为重要。比如,丰富的表引擎不仅能帮助企业用户实现数据的快速写入去重、更新、删除与分析,还能支持高效方便的运维方式,实现高性能更灵活的实时查询。
当海量数据存储上云,如何让数据变得更有价值?这时候就需要对数据进行研发治理。对大多数企业来说,数据的研发和治理向来是“老、大、难”问题,需求响应慢、资源成本高、数据质量差、资产管理难、安全无保障,每一项都在阻挠让数据成为企业可用资源。
火山引擎 VeDI 旗下大数据研发治理套件 DataLeap 聚焦企业数据研发治理两个环节,提供全链路解决方案。
首先,DataLeap 能够为企业提供基于字节大数据研发流程沉淀的 DataOps 敏捷研发流程、海量任务秒级调度能力和开源计算引擎的拓展能力;其次,在数据治理上,提供了分布式自治、全链路治理等服务;最后,在数据资产建设上,具备数据资产快速接入及自动构建全链路血缘等技术能力。
多个环节问题,一套解决流程,让企业得以真正实现“数据资产”积累。
更多维的数据应用场景
除了数据引擎能力之外,本次图谱还公布了火山引擎数智平台 VeDI 聚焦企业具体数据应用场景的多项能力与产品。
如,在辅助业务科学决策方面,历经字节跳动内部多业务、多场景验证的 A/B 测试能力已经通过火山引擎 DataTester 产品化输出。DataTester 能够深度耦合推荐、广告、搜索、UI、产品功能等多种业务场景需求,通过快速、简洁、智能化的实验配置,为业务增长、转化、产品迭代、策略优化、运营提效等各个环节提供科学的决策依据。
企业使用 DataTester 就可轻松依据业务需求开启 A/B 实验,能够通过更轻量的投入在实际业务场景中验证不同决策的可靠性,以此得出最优决策,帮助企业以持续小跑姿态实现业务增长。
此外,在智能洞察方面,火山引擎 VeDI 增长分析 DataFinder 能够基于埋点技术帮助企业洞察用户在包括 APP、小程序、商城等在内的路径旅程,同时可前置设置异常数据告警线,以帮助企业能即时发现问题。与此同时,通过 DataFinder 回流的数据还能接入到智能数据洞察 DataWind 中,后者是支持千亿级别数据自助分析的一站式数据分析与协作平台,提供 AI 与 BI 能力融合建模,帮助企业实现更精细化地数据深钻和分析,并支持多种报表形式展现。
而在智能营销场景中上,火山引擎 VeDI 推出的客户数据平台 VeCDP,可以帮助企业更好地找准目标市场,同时还能基于目标市场属性反向推导营销内容定制,以保障能把“合适的内容触达合适的人”,进一步提高营销转化;值得一提的是,在营销触达环节,增长营销平台 GMP 能够依据企业的具体业务需求, 通过全终端触点触达、智能策略、算法推荐、活动完整流程管理帮助企业实现降本增效以及业务持续增长。
如今,《数据智能知识图谱》涵盖的火山引擎数智平台 VeDI 系列能力都已经以产品化形式融入在企业数智化升级实践中。
截至 2023 年 2 月,包括陕西旅游集团、海王集团、Levi's、凯叔讲故事 APP、峰米科技、杭州银行等文旅、医药制造、零售、互联网、金融等多个行业在内的几百家企业,都已使用火山引擎数智平台 VeDI 的产品,并在多个数智化场景中获得实效。
点击跳转 火山引擎数智平台VeDI 了解更多
聚焦企业数据生命周期全链路 火山引擎数智平台 VeDI 发布《数据智能知识图谱》的更多相关文章
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- Activiti进行时——企业工作流生命周期贯通 (zhuan)
http://www.jianshu.com/p/e6971e8a8dad ********************************************** 图1:一个典型的审批工作流程 ...
- shell中的数据生命周期scope
#!/bin/shexit 0#shell 中, 默认所有的变量都是 全局变量,除非主动变量前面加 local 修饰#shell 变量是字符变量,只能放字符和数字,shell数组也是如此;而数字也是图 ...
- 1.1 大数据简介-hadoop-最全最完整的保姆级的java大数据学习资料
目录 1 hadoop-最全最完整的保姆级的java大数据学习资料 1.1 大数据简介 1.1.1 大数据的定义 1.1.2 大数据的特点 1.1.3 大数据的应用场景 1.1.4 大数据的发展趋势及 ...
- Django 数据生命周期
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 数据是ERP系统搭建的基础,但,不要让数据毁了ERP
很难想象没有数据的ERP是什么样子的.然而,实际情况又是如何的呢? 根据AMT的研究,在那些上线不成功或者上线后掉线的案例中,有高达70%的项目都有一个共同的直接原因,那就是在数据上出了问题.有的是在 ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- "过期不候"--具备生命周期的数据的技术实现方案
"过期不候"--具备生命周期的数据的技术实现方案 1 引言 本文可以作为之前的一个 原理性文章 对应的 技术实现部分 . 此处给出其上文的直达电梯: http://www.cn ...
随机推荐
- 1.参考例5.2.1,设计一个序列检测器。功能是检测出串行输入数据Sin中的4位二进制序列0101(自左至右输入),当检测到该序列时,输入Out=1;没有检测到该序列时,输入Out=0。要求不考虑序列重叠,如010101的序列中只包含一个0101序列。
设计块: module Detector2 ( input CP,Sin,nCR, output reg Out ); reg [1:0] Current_state,Next_state; para ...
- Java SPI机制学习之开发实例
原创/朱季谦 在该文章正式开始前,先对 Java SPI是什么做一个简单的介绍. SPI,是Service Provider Interface的缩写,即服务提供者接口,它允许开发人员定义一组接口,并 ...
- 【主流技术】详解 Spring Boot 2.7.x 集成 ElasticSearch7.x 全过程(二)
目录 前言 一.添加依赖 二. yml 配置 三.注入依赖 四.CRUD 常用 API ES 实体类 documents 操作 常见条件查询(重点) 分页查询 排序 构造查询 测试调用 五.文章小结 ...
- 2023-11-25:用go语言,给定一个数组arr,长度为n,表示n个格子的分数,并且这些格子首尾相连, 孩子不能选相邻的格子,不能回头选,不能选超过一圈, 但是孩子可以决定从任何位置开始选,也可以
2023-11-25:用go语言,给定一个数组arr,长度为n,表示n个格子的分数,并且这些格子首尾相连, 孩子不能选相邻的格子,不能回头选,不能选超过一圈, 但是孩子可以决定从任何位置开始选,也可以 ...
- TS版LangChain实战:基于文档的增强检索(RAG)
LangChain LangChain是一个以 LLM (大语言模型)模型为核心的开发框架,LangChain的主要特性: 可以连接多种数据源,比如网页链接.本地PDF文件.向量数据库等 允许语言模型 ...
- 25 个超棒的 Python 脚本合集
Python是一种功能强大且灵活的编程语言,拥有广泛的应用领域.下面是一个详细介绍25个超棒的Python脚本合集: 1. 网络爬虫:使用Python可以轻松编写网络爬虫,从网页中提取数据并保存为结构 ...
- 吉特日化MES & HttpClient基础连接已经关闭: 连接被意外关闭
在吉特日化MES调用某公司AGV平台下发任务的时候,使用HttpClient 进行POST请求,出现如下异常: HttpClient基础连接已经关闭: 连接被意外关闭 , 之前已经使用HTTPCli ...
- 聊聊GLM基座模型的理论知识
概述 大模型有两个流程:预训练和推理. 预训练是在某种神经网络模型架构上,导入大规模语料数据,通过一系列的神经网络隐藏层的矩阵计算.微分计算等,输出权重,学习率,模型参数等超参数信息. 推理是在预训练 ...
- PyTorch 中自定义数据集的读取方法
显然我们在学习深度学习时,不能只局限于通过使用官方提供的MNSIT.CIFAR-10.CIFAR-100这样的数据集,很多时候我们还是需要根据自己遇到的实际问题自己去搜集数据,然后制作数据集(收集数据 ...
- python tkinter 使用(二)
python tkinter 使用(二) 本篇文章着重讲下tkinter中messagebox的使用. 1:提示框 def showinfo(event): messagebox.showinfo(& ...