ARM下KVM虚拟化的损耗验证--redis
ARM下KVM虚拟化的损耗验证
摘要
看Windows 上面的 Workstation的虚拟机的 网络层的延迟特别高.
突然想之前统计都是直接在本地验证的, 只考虑了虚拟化CPU的性能损耗
没有考虑虚拟化层网络层的损耗.
所以想验证完了 Windows 和 intel平台 再抓紧验证一下
ARM平台的宿主机和KVM下面的虚拟机的redis性能比较
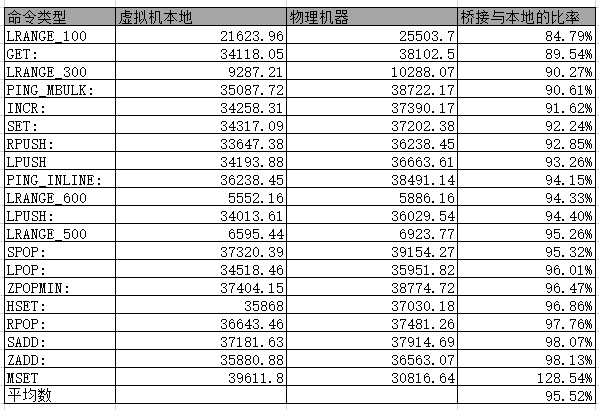
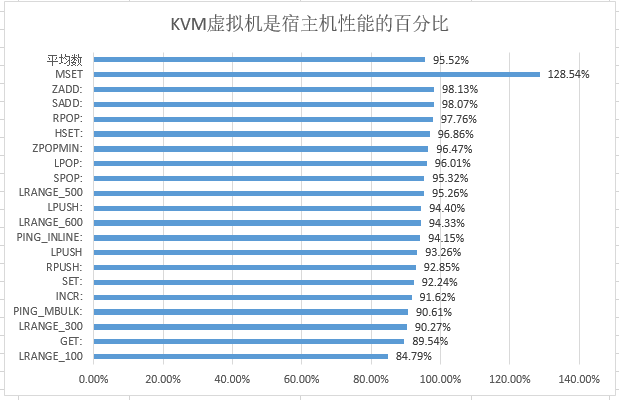
比较结果
测试命令:
虚拟机, 物理机使用类似的命令
./redis-benchmark -h 10.110.xxx.xxx -p 16379 -a xxxxx -n 200000 -c 20 -q
测试结果:
出去MSET 虚拟机比物理机性能好之外.
都是物理机比虚拟机性能好很多.
算数平均值是 95.5%
感觉KVM的损耗还是非常低的.
测试原始数据-物理机
PING_INLINE: 38491.14 requests per second, p50=0.455 msec
PING_MBULK: 38722.17 requests per second, p50=0.439 msec
SET: 37202.38 requests per second, p50=0.479 msec
GET: 38102.50 requests per second, p50=0.479 msec
INCR: 37390.17 requests per second, p50=0.487 msec
LPUSH: 36029.54 requests per second, p50=0.503 msec
RPUSH: 36238.45 requests per second, p50=0.503 msec
LPOP: 35951.82 requests per second, p50=0.503 msec
RPOP: 37481.26 requests per second, p50=0.479 msec
SADD: 37914.69 requests per second, p50=0.479 msec
HSET: 37030.18 requests per second, p50=0.487 msec
SPOP: 39154.27 requests per second, p50=0.463 msec
ZADD: 36563.07 requests per second, p50=0.495 msec
ZPOPMIN: 38774.72 requests per second, p50=0.463 msec
LPUSH (needed to benchmark LRANGE): 36663.61 requests per second, p50=0.495 msec
LRANGE_100 (first 100 elements): 25503.70 requests per second, p50=0.575 msec
LRANGE_300 (first 300 elements): 10288.07 requests per second, p50=1.023 msec
LRANGE_500 (first 500 elements): 6923.77 requests per second, p50=1.455 msec
LRANGE_600 (first 600 elements): 5886.16 requests per second, p50=1.711 msec
MSET (10 keys): 30816.64 requests per second, p50=0.591 msec
测试原始数据-虚拟机
PING_INLINE: 36238.45 requests per second, p50=0.439 msec
PING_MBULK: 35087.72 requests per second, p50=0.463 msec
SET: 34317.09 requests per second, p50=0.479 msec
GET: 34118.05 requests per second, p50=0.479 msec
INCR: 34258.31 requests per second, p50=0.471 msec
LPUSH: 34013.61 requests per second, p50=0.487 msec
RPUSH: 33647.38 requests per second, p50=0.479 msec
LPOP: 34518.46 requests per second, p50=0.479 msec
RPOP: 36643.46 requests per second, p50=0.479 msec
SADD: 37181.63 requests per second, p50=0.471 msec
HSET: 35868.00 requests per second, p50=0.487 msec
SPOP: 37320.39 requests per second, p50=0.471 msec
ZADD: 35880.88 requests per second, p50=0.487 msec
ZPOPMIN: 37404.15 requests per second, p50=0.471 msec
LPUSH (needed to benchmark LRANGE): 34193.88 requests per second, p50=0.495 msec
LRANGE_100 (first 100 elements): 21623.96 requests per second, p50=0.591 msec
LRANGE_300 (first 300 elements): 9287.21 requests per second, p50=1.159 msec
LRANGE_500 (first 500 elements): 6595.44 requests per second, p50=1.567 msec
LRANGE_600 (first 600 elements): 5552.16 requests per second, p50=1.831 msec
MSET (10 keys): 39611.80 requests per second, p50=0.415 msec
ARM下KVM虚拟化的损耗验证--redis的更多相关文章
- <llinux下kvm虚拟化>
原理就是本来可能要10台物理机完成的事现在只要5台,分别在每台物理机上虚拟一台,这5太虚拟机共享一个stronge,比如有一台物理机down掉后或是要做维护,我们可以把它上面的虚拟机牵走,从而减少损失 ...
- VMware下的Centos7实践Kvm虚拟化(通俗易懂)
虽然网上已经有很多关于kvm安装的教程了,但我还是看得头晕,有的教程里安装的包很多,有的很少,也没说明那些安装包的作用是干嘛的,用的命令也不一样,也没解释命令的意思是什么. 我重新写一个教程,尽量通俗 ...
- <Mastering KVM Virtualization>:第三章 搭建独立的KVM虚拟化
在第二章,你了解了KVM的内部结构:在本章中,您将了解如何将Linux服务器设置为虚拟化主机.我们正在讨论将KVM用于虚拟化并将libvirt作为虚拟化管理引擎. KVM开启了虚拟化并利用你的服务器或 ...
- [原创]KVM虚拟化管理平台的实现
KVM虚拟化管理平台的实现 源码链接:https://github.com/wsjhk/IaaS_admin.git 根据KVM虚拟化管理的要求,设计并实现网页操作管理KVM虚拟机.设计原理架构如下图 ...
- KVM虚拟化知识的一些笔记
一.KVM介绍 KVM:运行在内核空间,提供CPU 和内存的虚级化,以及客户机的 I/O 拦截.Guest 的 I/O 被 KVM 拦截后,交给 QEMU 处理. QEMU:修改过的为 KVM 虚机使 ...
- kvm虚拟化平台搭建入门
KVM虚拟化有两种网络模式:1)Bridge网桥模式2)NAT网络地址转换模式Bridge方式适用于服务器主机的虚拟化.NAT方式适用于桌面主机的虚拟化. 环境: 本次实验要开启VMWare中对应Ce ...
- KVM虚拟化技术
KVM虚拟化技术 Qemu-kvm kvm virt-manager VNC Qemu-kvm创建和管理虚拟机 一.KVM简介 KVM(名称来自英语:Kernel-basedVirtual Machi ...
- kvm虚拟化管理平台WebVirtMgr部署-完整记录(1)
公司机房有一台2U的服务器(64G内存,32核),由于近期新增业务比较多,测试机也要新增,服务器资源十分有限.所以打算在这台2U服务器上部署kvm虚拟化,虚出多台VM出来,以应对新的测试需求.当KVM ...
- 云计算之KVM虚拟化实战
1 基础环境规划 1.1 主机环境规划 系统版本 主机名 IP地址 内存 磁盘 CentOS6.9 kvm-node1 10.0.0.200 2G 20G CentOS6.9 kvm-node2 10 ...
- KVM虚拟化简介及安装
kvm是基于图形化的linux操作的 安装图形化界面的知识点: 磁盘空间有两个词: 精简置备:我先在我系统里面去声明我要一个50G的空间,但是呢,我不会把50G都分给你,你用多少,我分给你多少,但是做 ...
随机推荐
- CUDA个人入坟笔记
CUDA是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,基于CUDA编程可以利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题.近年来,GPU最成功的一个应用就是深度学习领 ...
- Golang代码测试:一点到面用测试驱动开发
摘要:TDD(Test Driven Development),测试驱动开发.期望局部最优到全局最优,这个是一种非常不错的好习惯. 了解Golang的测试之前,我们先了解一下go语言自带的测试工具. ...
- 如何正确使用Python临时文件
摘要:临时文件通常用来保存无法保存在内存中的数据,或者传递给必须从文件读取的外部程序.一般我们会在/tmp目录下生成唯一的文件名,但是安全的创建临时文件并不是那么简单,需要遵守许多规则. 1.前言 临 ...
- 你的Parquet该升级了:IOException: totalValueCount == 0问题定位之旅
摘要:使用Spark SQL进行ETL任务,在读取某张表的时候报错:"IOException: totalValueCount == 0",但该表在写入时,并没有什么异常. 本文分 ...
- 浏览器层面优化前端性能(2):Reader引擎线程与模块分析优化点
Reader 引擎线程与模块分析 首先是网页内容,加载完输入到HTML解释器,解释后构成DOM树,这期间如果遇到JavaScript代码就交给JavaScript引擎去处理,如果网页中包含CSS,就交 ...
- 火山引擎A/B测试在消费行业的案例实践
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近日,火山引擎数智平台举办了"走进火山-全链路增长:数据飞轮转动消费新生力"的活动,其中火山引 ...
- 开启一个 A/B 实验到底有多简单?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 火山引擎 A/B 测试平台 DataTester 孵化于字节跳动业务内部,在字节跳动,"万事皆 A/B, ...
- Java SpringBoot FTP 上传下载文件
POM 添加依赖 <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all< ...
- SocketChannel支持设定参数
SocketChannel支持设定参数SO_SNDBUF 套接字发送缓冲区大小SO_RCVBUF 套接字接收缓冲区大小SO_KEEPALIVE 保护连接O_REUSEADDR 复用地址SO_LINGE ...
- python发送邮件+多人+附件 !!!!
import smtplib import os from email.header import Header from email.mime.text import MIMEText # shen ...