初始 Kafka Consumer 消费者
温馨提示:整个 Kafka 专栏基于 kafka-2.2.1 版本。
1、KafkaConsumer 概述
根据 KafkaConsumer 类上的注释上来看 KafkaConsumer 具有如下特征:
在 Kafka 中 KafkaConsumer 是线程不安全的。
2.2.1 版本的KafkaConsumer 兼容 kafka 0.10.0 和 0.11.0 等低版本。
消息偏移量与消费偏移量(消息消费进度)
Kafka 为分区中的每一条消息维护一个偏移量,即消息偏移量。这个偏移量充当该分区内记录的唯一标识符。消费偏移量(消息消费进度)存储的是消费组当前的处理进度。消息消费进度的提交在 kafka 中可以定时自动提交也可以手动提交。手动提交可以调用 ommitSync() 或 commitAsync 方法。消费组 与 订阅关系
多个消费这可以同属于一个消费组,消费组内的所有消费者共同消费主题下的所有消息。一个消费组可以订阅多个主题。队列负载机制
既然同一个消费组内的消费者共同承担主题下所有队列的消费,那他们如何进行分工呢?默认情况下采取平均分配,例如一个消费组有两个消费者c1、c2,一个 topic 的分区数为6,那 c1 会负责3个分区的消费,同样 c2 会负责另外3个分区的分配。那如果其中一个消费者宕机或新增一个消费者,那队列能动态调整吗?
答案是会重新再次平衡,例如如果新增一个消费者 c3,则c1,c2,c3都会负责2个分区的消息消费,分区重平衡会在后续文章中重点介绍。消费者也可以通过 assign 方法手动指定分区,此时会禁用默认的自动分配机制。
消费者故障检测机制
当通过 subscribe 方法订阅某些主题时,此时该消费者还未真正加入到订阅组,只有当 consumeer#poll 方法被调用后,并且会向 broker 定时发送心跳包,如果 broker 在 session.timeout.ms 时间内未收到心跳包,则 broker 会任务该消费者已宕机,会将其剔除,并触发消费端的分区重平衡。消费者也有可能遇到“活体锁”的情况,即它继续发送心跳,但没有任何进展。在这种情况下,为了防止消费者无限期地占用它的分区,可以使用max.poll.interval.ms 设置提供了一个活性检测机制。基本上,如果您调用轮询的频率低于配置的最大间隔,那么客户机将主动离开组,以便另一个消费者可以接管它的分区。当这种情况发生时,您可能会看到一个偏移提交失败(由调用{@link #commitSync()}抛出的{@link CommitFailedException}表示)。
kafka 对 poll loop 行为的控制参数
Kafka 提供了如下两个参数来控制 poll 的行为:- max.poll.interval.ms
允许 两次调用 poll 方法的最大间隔,即设置每一批任务最大的处理时间。 - max.poll.records
每一次 poll 最大拉取的消息条数。
对于消息处理时间不可预测的情况下上述两个参数可能不够用,那将如何是好呢?
通常的建议将消息拉取与消息消费分开,一个线程负责 poll 消息,处理这些消息使用另外的线程,这里就需要手动提交消费进度。为了控制消息拉起的过快,您可能会需要用到 Consumer#pause(Collection) 方法,暂时停止向该分区拉起消息。RocketMQ 的推模式就是采用了这种策略。如果大家有兴趣的话,可以从笔者所著的《RocketMQ技术内幕》一书中详细了解。
- max.poll.interval.ms
2、KafkaConsume 使用示例
2.1 自动提交消费进度
public static void testConsumer1() {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092,localhost:9082,localhost:9072");
props.setProperty("group.id", "C_ODS_ORDERCONSUME_01");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("TOPIC_ORDER"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("消息消费中");
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
2.2 手动提交消费进度
public static void testConsumer2() {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "false");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
// insertIntoDb(buffer);
// 省略处理逻辑
consumer.commitSync();
buffer.clear();
}
}
}
3、认识 Consumer 接口
要认识 Kafka 的消费者,个人认为最好的办法就是从它的类图着手,下面给出 Consumer 接口的类图。
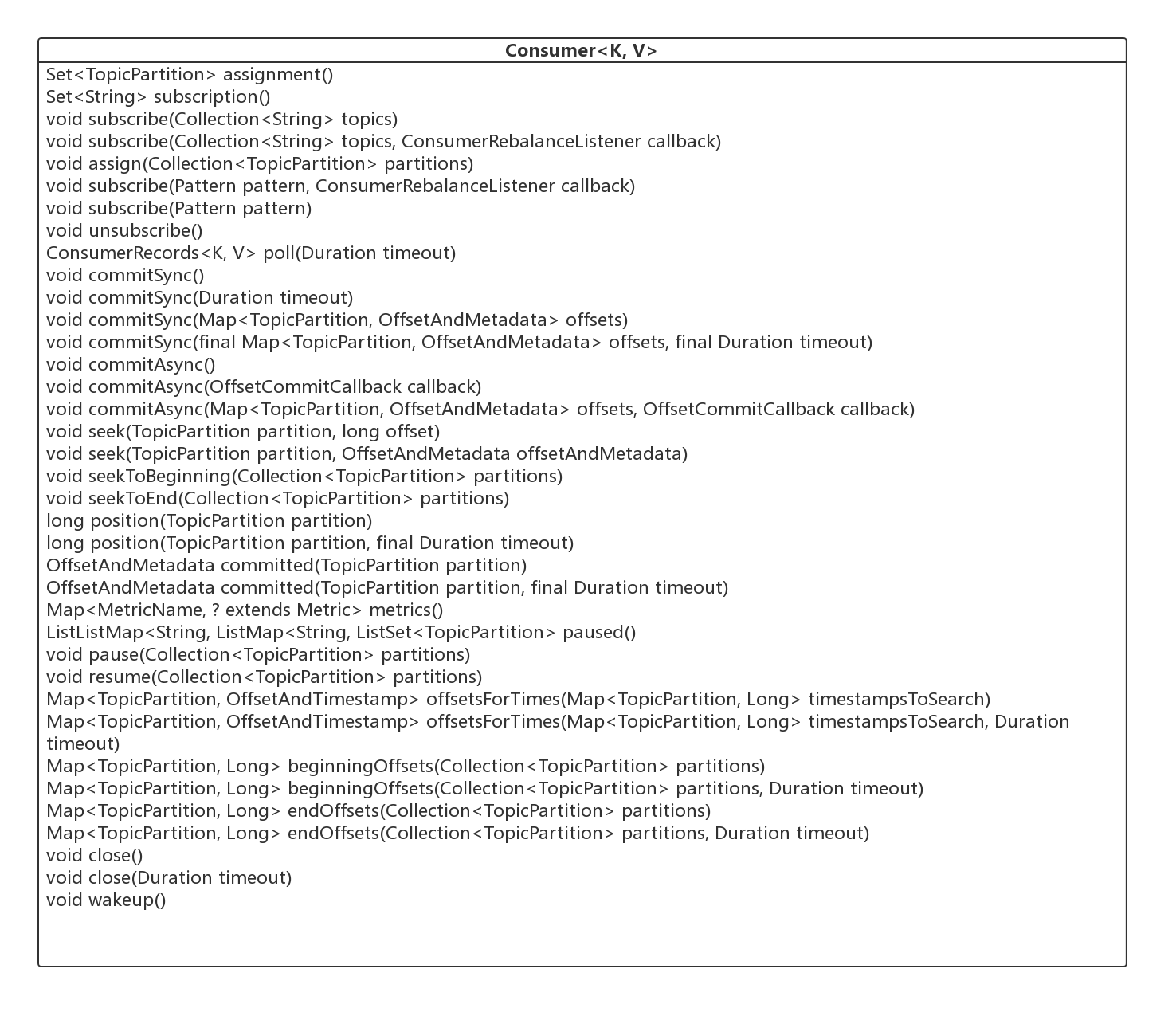
接下来对起重点方法进行一个初步的介绍,从下篇文章开始将对其进行详细设计。
- Set< TopicPartition> assignment()
获取该消费者的队列分配列表。 - Set< String> subscription()
获取该消费者的订阅信息。 - void subscribe(Collection< String> topics)
订阅主题。 - void subscribe(Collection< String> topics, ConsumerRebalanceListener callback)
订阅主题,并指定队列重平衡的监听器。 - void assign(Collection< TopicPartition> partitions)
取代 subscription,手动指定消费哪些队列。 - void unsubscribe()
取消订阅关系。 - ConsumerRecords<K, V> poll(Duration timeout)
拉取消息,是 KafkaConsumer 的核心方法,将在下文详细介绍。 - void commitSync()
同步提交消费进度,为本批次的消费提交,将在后续文章中详细介绍。 - void commitSync(Duration timeout)
同步提交消费进度,可设置超时时间。 - void commitSync(Map<TopicPartition, OffsetAndMetadata> offsets)
显示同步提交消费进度, offsets 指明需要提交消费进度的信息。 - void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets, final Duration timeout)
显示同步提交消费进度,带超时间。 - void seek(TopicPartition partition, long offset)
重置 consumer#poll 方法下一次拉消息的偏移量。 - void seek(TopicPartition partition, OffsetAndMetadata offsetAndMetadata)
seek 方法重载方法。 - void seekToBeginning(Collection< TopicPartition> partitions)
将 poll 方法下一次的拉取偏移量设置为队列的初始偏移量。 - void seekToEnd(Collection< TopicPartition> partitions)
将 poll 方法下一次的拉取偏移量设置为队列的最大偏移量。 - long position(TopicPartition partition)
获取将被拉取的偏移量。 - long position(TopicPartition partition, final Duration timeout)
同上。 - OffsetAndMetadata committed(TopicPartition partition)
获取指定分区已提交的偏移量。 - OffsetAndMetadata committed(TopicPartition partition, final Duration timeout)
同上。 - Map<MetricName, ? extends Metric> metrics()
统计指标。 - List< PartitionInfo> partitionsFor(String topic)
获取主题的路由信息。 - List< PartitionInfo> partitionsFor(String topic, Duration timeout)
同上。 - Map<String, List< PartitionInfo>> listTopics()
获取所有 topic 的路由信息。 - Map<String, List< PartitionInfo>> listTopics(Duration timeout)
同上。 - Set< TopicPartition> paused()
获取已挂起的分区信息。 - void pause(Collection< TopicPartition> partitions)
挂起分区,下一次 poll 方法将不会返回这些分区的消息。 - void resume(Collection< TopicPartition> partitions)
恢复挂起的分区。 - Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch)
根据时间戳查找最近的一条消息的偏移量。 - Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch, Duration timeout)
同上。 - Map<TopicPartition, Long> beginningOffsets(Collection< TopicPartition> partitions)
查询指定分区当前最小的偏移量。 - Map<TopicPartition, Long> beginningOffsets(Collection< TopicPartition> partitions, Duration timeout)
同上。 - Map<TopicPartition, Long> endOffsets(Collection< TopicPartition> partitions)
查询指定分区当前最大的偏移量。 - Map<TopicPartition, Long> endOffsets(Collection< TopicPartition> partitions, Duration timeout)
同上。 - void close()
关闭消费者。 - void close(Duration timeout)
关闭消费者。 - void wakeup()
唤醒消费者。
4、初始 KafkaConsumer
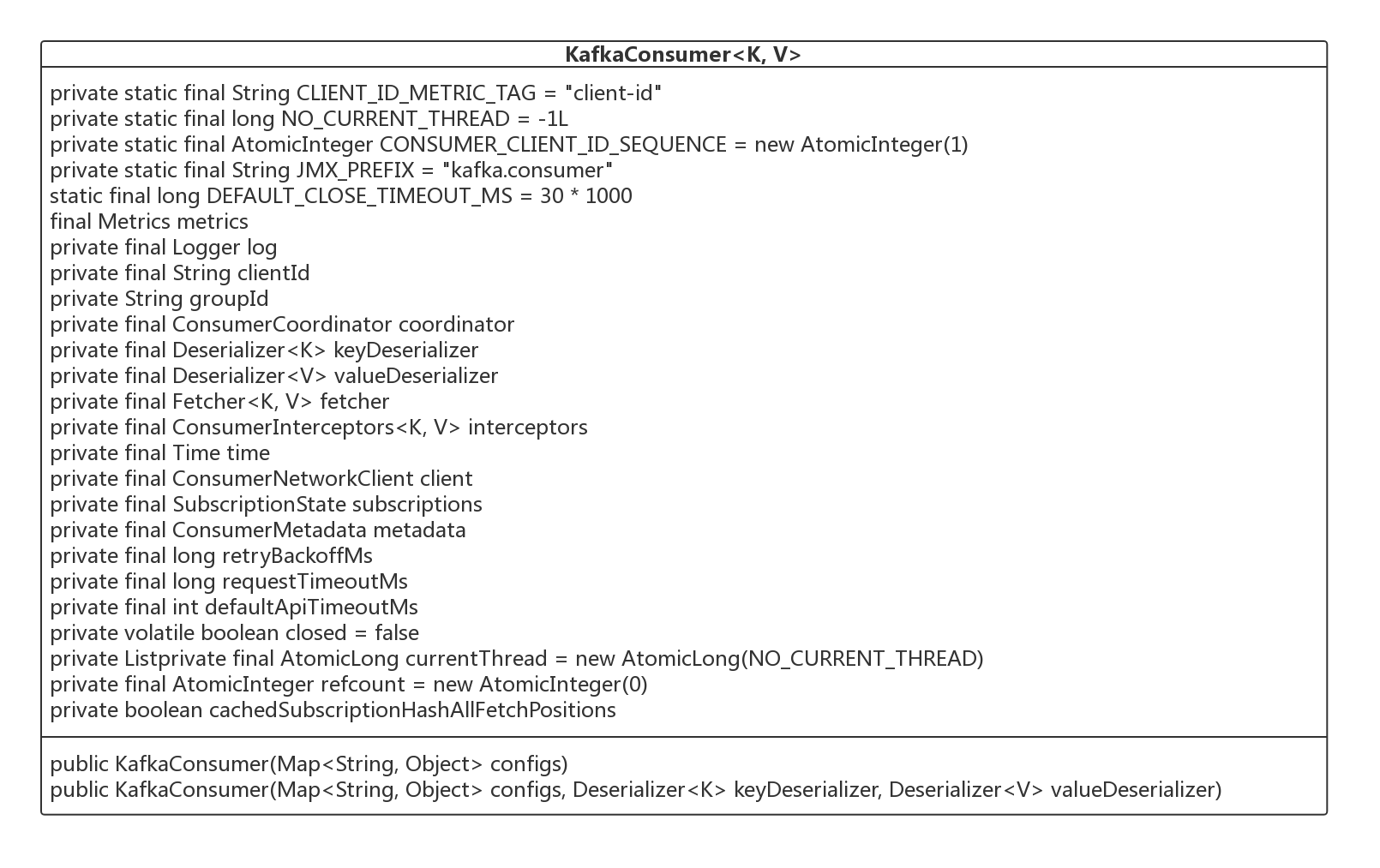
接下来笔者根据其构造函数,对一一介绍其核心属性的含义,为接下来讲解其核心方法打下基础。
- String groupId
消费组ID。同一个消费组内的多个消费者共同消费一个主题下的消息。 - String clientId
发出请求时传递给服务器的id字符串。设置该值的目的是方便在服务器端请求日志中包含逻辑应用程序名称,从而能够跟踪ip/端口之外的请求源。该值可以设置为应用名称。 - ConsumerCoordinator coordinator
消费协调器,后续会详细介绍。 - Deserializer< K> keyDeserializer
key 序列化器。 - Deserializer< V> valueDeserializer
值序列化器。 - ConsumerNetworkClient client
网络通讯客户端。 - SubscriptionState subscriptions
用于管理订阅状态的类,用于跟踪 topics, partitions, offsets 等信息。后续会详细介绍。 - ConsumerMetadata metadata
消费者元数据信息,包含路由信息。 - long retryBackoffMs
如果向 broker 发送请求失败后,发起重试之前需要等待的间隔时间,通过属性 retry.backoff.ms 指定。 - long requestTimeoutMs
一次请求的超时时间。 - int defaultApiTimeoutMs
为所有可能阻塞的API设置一个默认的超时时间。 - List< PartitionAssignor> assignors
分区分配算法(分区负载算法)。
Kafka Consumer 消费者就介绍到这里了,从下篇文章开始将开始详细介绍 Kafka 关于消息消费的方方面面。
作者介绍:
丁威,《RocketMQ技术内幕》作者,RocketMQ 社区布道师,公众号:中间件兴趣圈 维护者,目前已陆续发表源码分析Java集合、Java 并发包(JUC)、Netty、Mycat、Dubbo、RocketMQ、Mybatis等源码专栏。欢迎加入我的知识星球,构建一个高质量的技术交流社群。

初始 Kafka Consumer 消费者的更多相关文章
- Apache Kafka Consumer 消费者集
1.目标 在我们的上一篇文章中,我们讨论了Kafka Producer.今天,我们将讨论Kafka Consumer.首先,我们将看到什么是Kafka Consumer和Kafka Consumer的 ...
- 关于Kafka 的 consumer 消费者处理的一些见解
前言 在上一篇 Kafka使用Java实现数据的生产和消费demo 中介绍如何简单的使用kafka进行数据传输.本篇则重点介绍kafka中的 consumer 消费者的讲解. 应用场景 在上一篇kaf ...
- 四、 kafka consumer 配置
consumer配置 #指明当前消费进程所属的消费组,一个partition只能被同一个消费组的一个消费者消费(同一个组的consumer不会重复消费同一个消息) group.id #针对一个part ...
- 【原创】Kafka Consumer多线程实例
Kafka 0.9版本开始推出了Java版本的consumer,优化了coordinator的设计以及摆脱了对zookeeper的依赖.社区最近也在探讨正式用这套consumer API替换Scala ...
- Kafka设计解析(四)- Kafka Consumer设计解析
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/08/09/KafkaColumn4 摘要 本文主要介绍了Kafka High Level Con ...
- 【原创】kafka consumer源代码分析
顾名思义,就是kafka的consumer api包. 一.ConsumerConfig.scala Kafka consumer的配置类,除了一些默认值常量及验证参数的方法之外,就是consumer ...
- kafka集群搭建和使用Java写kafka生产者消费者
1 kafka集群搭建 1.zookeeper集群 搭建在110, 111,112 2.kafka使用3个节点110, 111,112 修改配置文件config/server.properties ...
- Kafka consumer处理大消息数据问题
案例分析 处理kafka consumer的程序的时候,发现如下错误: ERROR [2016-07-22 07:16:02,466] com.flow.kafka.consumer.main.Kaf ...
- Python 使用python-kafka类库开发kafka生产者&消费者&客户端
使用python-kafka类库开发kafka生产者&消费者&客户端 By: 授客 QQ:1033553122 1.测试环境 python 3.4 zookeeper- ...
随机推荐
- 2018-9-28-WPF-自定义-TextBoxView-的-Margin-大小
title author date CreateTime categories WPF 自定义 TextBoxView 的 Margin 大小 lindexi 2018-09-28 17:16:17 ...
- Python基础知识汇总
1.执行脚本的两种方式 Python a.py 直接调用Python解释器执行文件 chomd +x a.py ./a.py #修改a.py文件的属性,为可执行,在用 ./ 执行 ...
- Spark1.6.1 MLlib 特征抽取和变换
Spark1.6.1 MLlib 特征抽取和变换 1 TF-IDF TF-IDF是一种特征向量化方法,这种方法多用于文本挖掘,通过算法可以反应出词在语料库中某个文档中的重要性.文档中词记为t,文档记为 ...
- uni-app 常用框架内置方法 更新中 .....
获取 登录信息,getStorage 初始化页面数据 请求 下拉刷新页面 加载更多 点击跳转 个人中心 uni.request(OBJECT) success=成功 fail=失 ...
- 无限调用函数add(1)(2)(3)......
无限调用函数,并且累计结果 其实这也算一道面试题吧,笔者曾经被提问过,可惜当时没能答上来...
- ActiveMQ安装报错Wrapped Stopped解决办法
在安装ActiveMQ的时候遇到了这个问题,一直报Wrapper Stopped 先开始也是修改环境变量,重启电脑,发现没有用,后来打开任务管理器,关闭了erl.exe,就成功了. 原文地址:http ...
- 2018-8-10-win10-uwp-绑定-OneWay-无法使用
title author date CreateTime categories win10 uwp 绑定 OneWay 无法使用 lindexi 2018-08-10 19:16:50 +0800 2 ...
- H3C使用ping命令
- SDOI2019热闹又尴尬的聚会
P5361 [SDOI2019]热闹又尴尬的聚会 出题人用脚造数据系列 只要将\(p\)最大的只求出来,\(q\)直接随便rand就能过 真的是 我们说说怎么求最大的\(p\),这个玩意具有很明显的单 ...
- 2018-9-30-C#-使用外部别名
title author date CreateTime categories C# 使用外部别名 lindexi 2018-09-30 18:37:23 +0800 2018-07-02 14:31 ...