InfluxDB入门
InfluxDB是一个用于存储和分析时间序列数据的开源数据库
时序数据是基于时间的一系列的数据
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能
InfluxDB主要特性:
- 内置HTTP接口,使用方便
- 数据可以打标记,查让查询可以很灵活
- 类SQL的查询语句
- 安装管理很简单,并且读写数据很高效
- 能够实时查询,数据在写入时被索引后就能够被立即查出
1.安装
(1)windows下
下载 https://portal.influxdata.com/downloads/

选择

解压
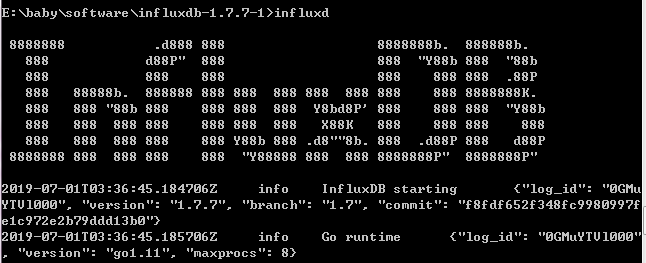
启动服务端,打开命令窗口,到这个目录下,执行
influxd
启动客户端,打开命令窗口,到这个目录下,执行
influx
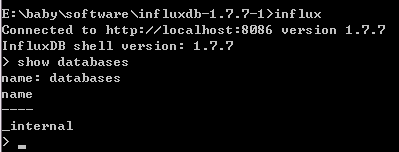
安装成功
(2)Linux下
下载
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.7_linux_amd64.tar.gz
解压
tar xvfz influxdb-1.7.7_linux_amd64.tar.gz
重命名
mv influxdb-1.7.7-1 influxdb
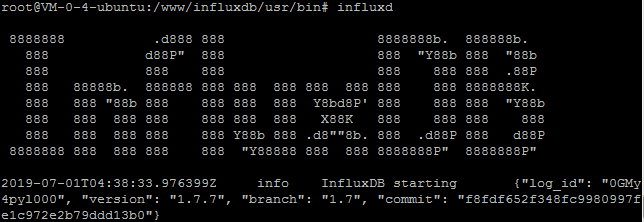
influxdb/usr/bin/influxd服务端
./influxd
全局使用
ln -s /www/influxdb/usr/bin/influxd /usr/local/bin/influxd
使用
influxd
influxdb/usr/bin/influxd客户端命令
ln -s /www/influxdb/usr/bin/influx /usr/local/bin/influx
使用
influx

> create database mydb
> show databases
name: databases
name
----
_internal
mydb
2.简单使用
(1)名词介绍:
database:数据库
measurement:数据库中的表
points:表里面的一行数据
Point由时间戳(time)、数据(field)和标签(tags)组成
time:每条数据记录的时间,也是数据库自动生成的主索引
fields:各种记录的值
tags:各种有索引的属性
(2)数据库基本操作
#创建数据库
> create database "test"
#显示所有数据库
> show databases
name: databases
name
----
_internal
test
#打开数据库
> use test
Using database test
#显示该数据库中所有的表
> show measurements
#创建表,直接在插入数据的时候指定表名test
> insert test,host=127.0.0.1,monitor_name=test count=1
> show measurements
name: measurements
name
----
test
#删除表test
> drop measurement "test"
> show measurements
#删除数据库test
> drop database test
> show databases
name: databases
name
----
_internal
说明:
insert test,host=127.0.0.1,monitor_name=test count=1
test:表名
host=127.0.0.1,monitor_name=test:tag
count=1:field
插入与查询数据
> create database test
> show databases
name: databases
name
----
_internal
test
> show measurements
> insert test,host=127.0.0.1,monitor_name=test count=1
> show measurements
name: measurements
name
----
test
> select * from test order by time desc
name: test
time count host monitor_name
---- ----- ---- ------------
1561957302455301318 1 127.0.0.1 test
> insert test,host=127.0.0.1,monitor_name=test count=1
> select * from test order by time desc
name: test
time count host monitor_name
---- ----- ---- ------------
1561957336177679133 1 127.0.0.1 test
1561957302455301318 1 127.0.0.1 test
(3)数据保存策略(Retention Policies):
influxDB是没有提供直接删除数据记录的方法,但是提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据
查看当前数据库Retention Policies
> show retention policies on "test"
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 true
创建新的Retention Policies
> create retention policy "rp_name" on "test" duration 1w replication 1 default
> show retention policies on "test"
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
rp_name 168h0m0s 24h0m0s 1 true
说明:
rp_name:策略名
test:数据库名
1w:保存1周,1周之前的数据将被删除,influxdb具有各种事件参数,比如:h(小时),d(天),w(星期)
replication 1:副本个数,一般为1就可以了
default:设置为默认策略
修改Retention Policies
> alter retention policy "rp_name" on "test" duration 5d default
> show retention policies on "test"
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
rp_name 120h0m0s 24h0m0s 1 true
删除Retention Policies
> drop retention policy "rp_name" on "test"
> show retention policies on "test"
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
(4)连续查询(Continous Queries)
InfluxDB的数据保留策略,数据超过保存策略里指定的时间之后,就会被删除。但是如果我们不想完全将这些数据删除掉,就需要连续查询(Continuous Queries)的帮助了。
连续查询主要用在将数据归档,以降低系统空间的占用率,主要是以降低精度为代价。
连续查询是在数据库中自动定时启动的一组语句,语句中必须包含 SELECT 关键词和 GROUP BY time() 关键词。
InfluxDB会将查询结果放在指定的数据表中
查看Continous Queries
> show continuous queries
name: _internal
name query
---- ----- name: test
name query
---- -----
创建Continous Queries
> show continuous queries
name: _internal
name query
---- ----- name: test
name query
---- -----
> create continuous query cq_name on test begin select sum(count) into test1 from test group by time(10m) end
> show continuous queries name: _internal
name query
---- ----- name: test
name query
---- -----
cq_name CREATE CONTINUOUS QUERY cq_name ON test BEGIN SELECT sum(count) INTO test.rp_name.test1 FROM test.rp_name.test GROUP BY time(10m) END
删除Continous Queries
> drop continuous query cq_name on test
> show continuous queries
name: _internal
name query
---- ----- name: test
name query
---- -----
在InfluxDB中,将连续查询与数据存储策略一起使用会达到最好的效果
(5)用户管理
> show users
user admin
---- -----
> create user "abc" with password '123'
> show users
user admin
---- -----
abc false
> drop user "abc"
> show users
user admin
---- -----
注:
如果启动失败,请查看是否是端口被占用,默认端口为8088
InfluxDB入门的更多相关文章
- InfluxDB学习系列教程,InfluxDB入门必备教程
nfluxDB是一个当下比较流行的时序数据库,InfluxDB使用 Go 语言编写,无需外部依赖,安装配置非常方便,适合构建大型分布式系统的监控系统. 本文是一系列InfluxDB学习教程的目录,现主 ...
- influxdb入门——和mongodb一样可以动态增加字段
./influxd [--config yourconfigfile 2> /dev/null] 之所以重定向 因为默认log是stderr 再启动客户端./influx > CREAT ...
- InfluxDB入门教程
前言InfluxDB是一个时序性数据库,详细资料如下http://liubin.org/blog/2016/02/18/tsdb-intro/ 下载和安装LZ从官网下载的是influxdb-1.2.4 ...
- .NET Core微服务之基于App.Metrics+InfluxDB+Grafana实现统一性能监控
Tip: 此篇已加入.NET Core微服务基础系列文章索引 一.关于App.Metrics+InfluxDB+Grafana 1.1 App.Metrics App.Metrics是一款开源的支持. ...
- 别人家的 InfluxDB 实战 + 源码剖析
1. 前几次的分享,我们多次提到了下图中 Metrics 指标监控的 Prometheus.Grafana,而且 get 到了 influxdata 旗下的 InfluxDB 的入门技能. 本次,我们 ...
- 通过Python将监控数据由influxdb写入到MySQL
一.项目背景 我们知道InfluxDB是最受欢迎的时序数据库(TSDB).InfluxDB具有 持续高并发写入.无更新:数据压缩存储:低查询延时 的特点.从下面这个权威的统计图中,就可以看出Influ ...
- InfluxDB Java入门
添加依赖 <dependency> <groupId>org.influxdb</groupId> <artifactId>influxdb-java& ...
- influxDB安装部署及入门
1.下载安装包,本文使用1.7.7版本 https://portal.influxdata.com/downloads/ 2.安装 yum localinstall influxdb-1.7.7.x8 ...
- InfluxDB学习之InfluxDB的基本操作
InfluxDB提供类SQL语法,如果熟悉SQL的话会非常容易上手.本文就为大家介绍一下InfluxDB的基本操作. InfluxDB提供类SQL语法,如果熟悉SQL的话会非常容易上手. 本文 ...
随机推荐
- SOA 架构与微服务架构的区别
注重重用,微服务注重重写 SOA 的主要目的是为了企业各个系统更加容易地融合在一起. 微服务通常由重写一个模块开始.要把整个巨石型的应用重写是有很大的风险的,也不一定必要.我们向微服务迁移的时候通常从 ...
- Hive UDF函数构建
1. 概述 UDF函数其实就是一个简单的函数,执行过程就是在Hive转换成MapReduce程序后,执行java方法,类似于像MapReduce执行过程中加入一个插件,方便扩展.UDF只能实现一进一出 ...
- WebService(一)
最近一段时间研究webservice,一般来说,开发java的Webservice经常使用axis2和cxf这两个比较流行的框架 先使用cxf,开发一个完整示例,方便对webservice有一个整体的 ...
- C# Base64字符串生成图片
C# Base64字符串生成图片: //签字图片Base64格式去除开头多余字符data:image/png;base64, strSignImg = strSignImg.Substring(str ...
- ES6函数的个人总结
默认参数: 1. 在 ES5 语法中,为函数形参指定默认值的写法: 写法一: function foo (bar) { bar = bar || 'abc'; console.log(bar) } f ...
- oracle 按每天,每周,每月,每季度,每年查询统计数据
oracle 按每天,每周,每月,每季度,每年查询统计数据 //按天统计 select count(dataid) as 每天操作数量, sum() from tablename group by t ...
- jsp之大文件分段上传、断点续传
1,项目调研 因为需要研究下断点上传的问题.找了很久终于找到一个比较好的项目. 在GoogleCode上面,代码弄下来超级不方便,还是配置hosts才好,把代码重新上传到了github上面. http ...
- circus security 来自官方的安全建议
转自:https://circus.readthedocs.io/en/latest/design/security/ Circus is built on the top of the ZeroMQ ...
- Dart和JavaScript对比小结
作为一名web前端来入门dart,新语言和我们熟悉的js有所差异,写dart的过程中容易受到原有思维的影响,这里把dart和js做一个对比总结,方便查找和熟悉. 变量声明 var 关键字 dart和j ...
- 洛谷 P4568 [JLOI2011]飞行路线 题解
P4568 [JLOI2011]飞行路线 题目描述 Alice和Bob现在要乘飞机旅行,他们选择了一家相对便宜的航空公司.该航空公司一共在\(n\)个城市设有业务,设这些城市分别标记为\(0\)到\( ...