【面试突击】-缓存击穿(布隆过滤器 Bloom Filter)
原文地址:https://blog.csdn.net/fouy_yun/article/details/81075432
前面的文章介绍了缓存的分类和使用的场景。通常情况下,缓存是加速系统响应的一种途径,通常情况下只有系统的部分数据。当请求了缓存中没有的数据时,这时候就会回源到DB里面。此时如果黑客故意对上面数据发起大量请求,则DB有可能会挂掉,这就是缓存击穿。当然缓存挂掉的话,正常的用户请求也有可能造成缓存击穿的效果。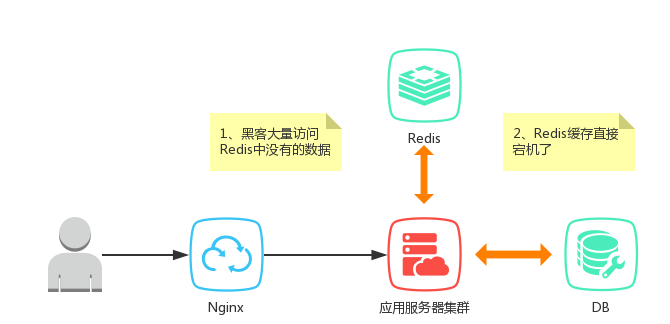
缓存中无值(未宕机)
互斥锁
我们最先想到的应该是加锁获取缓存。也就是当获取的value值为空时(这里的空表示缓存过期),先加锁,然后从数据库加载并放入缓存,最后释放锁。如果其他线程获取锁失败,则睡眠一段时间后重试。下面使用Redis的setnx来实现分布式锁,如下所示:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if (redis.setnx(key_mutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(key_mutex, 3 * 60)
value = db.get(key);
redis.set(key, value);
redis.delete(key_mutex);
} else {
//其他线程休息50毫秒后重试
Thread.sleep(50);
get(key);
}
}
}

缓存永不过期
缓存永不过期的意思是:真正的缓存过期时间不有Redis控制,而是由程序代码控制。当获取数据时发现数据超时时,就需要发起一个异步请求去加载数据。这种策略的有点就是不会产生死锁等现象,但是有可能会造成缓存不一致的现象,但是笔者看来一般情况下都是可以适用的。
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()) {
// 异步更新后台异常执行
threadPool.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
if (redis.setnx(keyMutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(keyMutex, 3 * 60);
String dbValue = db.get(key);
redis.set(key, dbValue);
redis.delete(keyMutex);
}
}
});
}
return value;
}
缓存宕机
上面说到的场景是缓存依旧有效的,当Redis挂掉时,这个时候如何来应对大量的回源请求呢?先来说一种简单的方式:白名单。
白名单
白名单顾名思义就是:在缓存宕机之前的一段时间里,会将请求的数据在系统中的有无,记录在一个Map中。当缓存宕机后,首先在Map中判断是否含有数据,有则回源DB,没有的话就直接返回结果。
这种方式实现起来比较简单(Demo就不提供了),但是占用的内存空间比较庞大。如一个value是10字节,那么要存储大小为1亿的Map时,其所需的内存大小大约是:10 * 2 * 10e8 = 2G(假设Map的利用率为50%)。由此可见其对于一种类型的数据判断就需要一个 2G 的Map去操作,这种方式就不可行了。
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为:O(n), O(log n), O(n/k)。
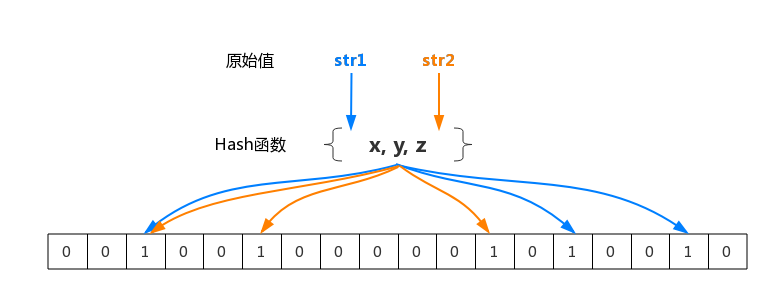
布隆过滤器的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
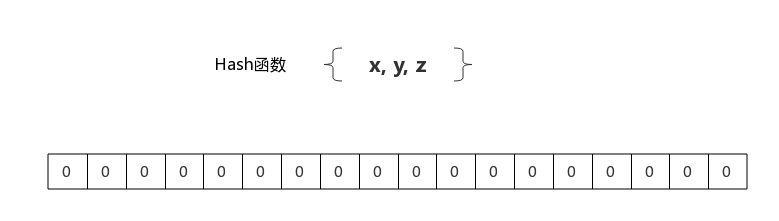
代码实现
在实际应用当中,我们不需要自己去实现BloomFilter。可以使用Guava提供的相关类库即可。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>
判断一个元素是否在集合中
public class Test1 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // 获取开始时间
//判断这一百万个数中是否包含29999这个数
if (bloomFilter.mightContain(29999)) {
System.out.println("命中了");
}
long endTime = System.nanoTime(); // 获取结束时间
System.out.println("程序运行时间: " + (endTime - startTime) + "纳秒");
}
}
运行结果如下:
命中了
程序运行时间: 441616纳秒
自定义错误率
public class Test3 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.01);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
// 故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
运行结果如下:
误判的数量:94
对于缓存宕机的场景,使用白名单或者布隆过滤器都有可能会造成一定程度的误判。原因是除了Bloom Filter 本身有误判率,宕机之前的缓存不一定能覆盖到所有DB中的数据,当宕机后用户请求了一个以前从未请求的数据,这个时候就会产生误判。当然,缓存宕机时使用白名单/布隆过滤器作为应急的方式,这种情况也是可以接受的。
【面试突击】-缓存击穿(布隆过滤器 Bloom Filter)的更多相关文章
- [转载]布隆过滤器(Bloom Filter)
[转载]布隆过滤器(Bloom Filter) 这部分学习资料来源:https://www.youtube.com/watch?v=v7AzUcZ4XA4 Filter判断不在,那就是肯定不在:Fil ...
- 布隆过滤器(Bloom Filter)详解——基于多hash的概率查找思想
转自:http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- [转载] 布隆过滤器(Bloom Filter)详解
转载自http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- 布隆过滤器(Bloom Filter)详解
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中.和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一 ...
- 浅谈布隆过滤器Bloom Filter
先从一道面试题开始: 给A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL. 这个问题的本质在于判断一个元素是否在一个集合中.哈希表以O(1) ...
- 布隆过滤器 Bloom Filter 2
date: 2020-04-01 17:00:00 updated: 2020-04-01 17:00:00 Bloom Filter 布隆过滤器 之前的一版笔记 点此跳转 1. 什么是布隆过滤器 本 ...
- 布隆过滤器(Bloom Filter)的原理和实现
什么情况下需要布隆过滤器? 先来看几个比较常见的例子 字处理软件中,需要检查一个英语单词是否拼写正确 在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上 在网络爬虫里,一个网址是否被访问过 yahoo, ...
- 布隆过滤器(Bloom Filter)-学习笔记-Java版代码(挖坑ing)
布隆过滤器解决"面试题: 如何建立一个十亿级别的哈希表,限制内存空间" "如何快速查询一个10亿大小的集合中的元素是否存在" 如题 布隆过滤器确实很神奇, 简单 ...
- 探索C#之布隆过滤器(Bloom filter)
阅读目录: 背景介绍 算法原理 误判率 BF改进 总结 背景介绍 Bloom filter(后面简称BF)是Bloom在1970年提出的二进制向量数据结构.通俗来说就是在大数据集合下高效判断某个成员是 ...
随机推荐
- python gaussian,gaussian2
import numpy as np import matplotlib.pyplot as plt import mpl_toolkits.axisartist as axisartist from ...
- asp.netCore3.0 中使用app.UseMvc() 配置路由
一.新配置路由策略 在 Asp.Net Core 3.0中默认不再支持app.UserMvc() 方式配置路由 系统. 而是使用新的模式,点击查看asp.netCore3.0区域和路由配置变化 默认 ...
- CentOS7下安装ELK(nginx 、elasticsearch-5.1.1、logstash-5.1.1、kibana-5.1.1)
nginx: #直接yum安装: [root@elk-node1 ~]# yum install nginx -y 官方文档:http://nginx.org/en/docs/http/ngx_htt ...
- mybatis如何接受map类型的参数
Mybatis传入参数类型为Map mybatis更新sql语句: ? 1 2 3 4 5 6 7 8 9 <update id="publishT00_notice" ...
- wms证书异常问题
目前我司已定位到两个原因,详细如下, 1. 快速生成的证书存在问题,导致APACHE和NGINX显示的时间都是4号凌晨 2. 贵司在配置完成162和163两台应用的APACHE证书,以及其中10. ...
- java日期格式转换大全
public class DateFormatUtils { private static Log logger = LogFactory.getLog(DateFormatUtils.class); ...
- EasyDSS高性能RTMP、HLS(m3u8)、HTTP-FLV、RTSP流媒体服务器软件对数据库Sqlite3和MySQL的支持说明
背景分析 EasyDSS商用流媒体服务器提供一站式的转码.点播.直播.时移回放服务,极大地简化了开发和集成的工作,并且EasyDSS支持多种特性,完全能够满足企业视频信息化建设方面的需求.其中,点播功 ...
- JKS转PFX
通过jks2pfx工具 请下载:JKS2PFX转换工具. 将压缩包解开到 c:\jks2pfx 目录下, 运行以下命令:JKS2PFX <导出文件名> [Java Runtime的目录]备 ...
- CentOS7 ping: unknown host www.baidu.com
原文链接:https://blog.csdn.net/zz657114506/article/details/53871470
- shiro中anon配置不生效
再配置shiro的时候,如下代码要注意: 1.下述代码中必须是LinkedHashMap 而不能是HashMap. 2.anon定义必须在authc之前 否则anon定义不生效 @Bean ...