布隆过滤器(Bloom Filter)的原理和实现
什么情况下需要布隆过滤器?
先来看几个比较常见的例子
- 字处理软件中,需要检查一个英语单词是否拼写正确
- 在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上
- 在网络爬虫里,一个网址是否被访问过
- yahoo, gmail等邮箱垃圾邮件过滤功能
这几个例子有一个共同的特点: 如何判断一个元素是否存在一个集合中?
常规思路
- 数组
- 链表
- 树、平衡二叉树、Trie
- Map (红黑树)
- 哈希表
虽然上面描述的这几种数据结构配合常见的排序、二分搜索可以快速高效的处理绝大部分判断元素是否存在集合中的需求。但是当集合里面的元素数量足够大,如果有500万条记录甚至1亿条记录呢?这个时候常规的数据结构的问题就凸显出来了。数组、链表、树等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长,最终达到瓶颈。有的同学可能会问,哈希表不是效率很高吗?查询效率可以达到O(1)。但是哈希表需要消耗的内存依然很高。使用哈希表存储一亿 个垃圾 email 地址的消耗?哈希表的做法:首先,哈希函数将一个email地址映射成8字节信息指纹;考虑到哈希表存储效率通常小于50%(哈希冲突);因此消耗的内存:8 * 2 * 1亿 字节 = 1.6G 内存,普通计算机是无法提供如此大的内存。这个时候,布隆过滤器(Bloom Filter)就应运而生。在继续介绍布隆过滤器的原理时,先讲解下关于哈希函数的预备知识。
哈希函数
哈希函数的概念是:将任意大小的数据转换成特定大小的数据的函数,转换后的数据称为哈希值或哈希编码。下面是一幅示意图:
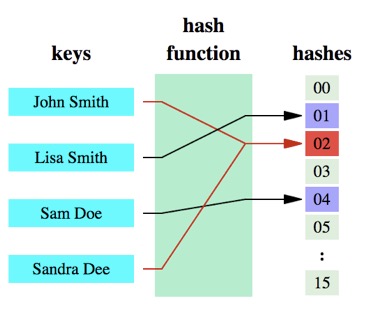
可以明显的看到,原始数据经过哈希函数的映射后称为了一个个的哈希编码,数据得到压缩。哈希函数是实现哈希表和布隆过滤器的基础。
布隆过滤器介绍
- 巴顿.布隆于一九七零年提出
- 一个很长的二进制向量 (位数组)
- 一系列随机函数 (哈希)
- 空间效率和查询效率高
- 有一定的误判率(哈希表是精确匹配)
布隆过滤器原理
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k
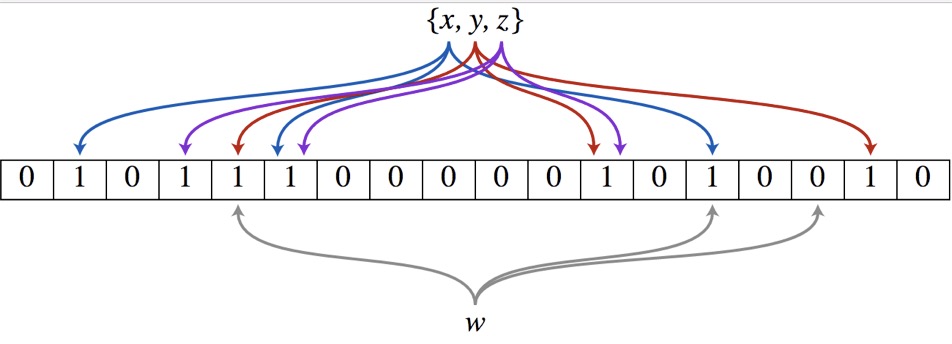
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
布隆过滤器添加元素
- 将要添加的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 将这k个位置设为1
布隆过滤器查询元素
- 将要查询的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 如果k个位置有一个为0,则肯定不在集合中
- 如果k个位置全部为1,则可能在集合中
布隆过滤器实现
下面给出python的实现,使用murmurhash算法
import mmh3
from bitarray import bitarray
# zhihu_crawler.bloom_filter
# Implement a simple bloom filter with murmurhash algorithm.
# Bloom filter is used to check wether an element exists in a collection, and it has a good performance in big data situation.
# It may has positive rate depend on hash functions and elements count.
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]
源码地址:https://github.com/cpselvis/zhihu-crawler/blob/master/bloom_filter.py
布隆过滤器(Bloom Filter)的原理和实现的更多相关文章
- [转载]布隆过滤器(Bloom Filter)
[转载]布隆过滤器(Bloom Filter) 这部分学习资料来源:https://www.youtube.com/watch?v=v7AzUcZ4XA4 Filter判断不在,那就是肯定不在:Fil ...
- url去重 --布隆过滤器 bloom filter原理及python实现
https://blog.csdn.net/a1368783069/article/details/52137417 # -*- encoding: utf-8 -*- ""&qu ...
- 【面试突击】-缓存击穿(布隆过滤器 Bloom Filter)
原文地址:https://blog.csdn.net/fouy_yun/article/details/81075432 前面的文章介绍了缓存的分类和使用的场景.通常情况下,缓存是加速系统响应的一种途 ...
- 布隆过滤器 Bloom Filter 2
date: 2020-04-01 17:00:00 updated: 2020-04-01 17:00:00 Bloom Filter 布隆过滤器 之前的一版笔记 点此跳转 1. 什么是布隆过滤器 本 ...
- 布隆过滤器(Bloom Filter)详解——基于多hash的概率查找思想
转自:http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- [转载] 布隆过滤器(Bloom Filter)详解
转载自http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- 布隆过滤器(Bloom Filter)详解
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中.和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一 ...
- 浅谈布隆过滤器Bloom Filter
先从一道面试题开始: 给A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL. 这个问题的本质在于判断一个元素是否在一个集合中.哈希表以O(1) ...
- 布隆过滤器(Bloom Filter)-学习笔记-Java版代码(挖坑ing)
布隆过滤器解决"面试题: 如何建立一个十亿级别的哈希表,限制内存空间" "如何快速查询一个10亿大小的集合中的元素是否存在" 如题 布隆过滤器确实很神奇, 简单 ...
随机推荐
- 客户端(android,ios)与服务器通信
android,ios客户端与服务器通信为了便于理解,直接用PHP作为服务器端语言 其实就是一个 http请求响应的过程序,先从 B/S模式说起浏览器发起http请求,服务器响应请求,并把数据返回给浏 ...
- Cassandra1.2文档学习(9)—— 数据写入
数据参考:http://www.datastax.com/documentation/cassandra/1.2/webhelp/index.html#cassandra/dml/manage_dml ...
- CSS3的position:sticky介绍
用户的屏幕越来越大,而页面太宽的话会不宜阅读,所以绝大部分网站的主体宽度和之前相比没有太大的变化,于是浏览器中就有越来越多的空白区域,所以你可能注意到很多网站开始在滚动的时候让一部分内容保持可见,比如 ...
- 【1】Bootstrap入门引言
Bootstrap学习者要具备的一些要求: [1]xhtml常用标签的基础知识 [2]xhtml+css布局的基础知识 [3]html5+css3的基础知识 ===================== ...
- c++重载与覆写
重载:指子类改写了父类的方法,覆写:指同一个函数,同样的参数列表,同样的返回值的,但是函数内部的实现过程不同. 重载: 1.方法名必须相同. 2.参数列表必须不相同,与参数列表的顺序无关. 3.返回值 ...
- [BZOJ 2212] [Poi2011] Tree Rotations 【线段树合并】
题目链接:BZOJ - 2212 题目分析 子树 x 内的逆序对个数为 :x 左子树内的逆序对个数 + x 右子树内的逆序对个数 + 跨越 x 左子树与右子树的逆序对. 左右子树内部的逆序对与是否交换 ...
- Yours 的博客开张啦!
虽然申请博客已经1个月了,但是一直没有来写,没办法,题都刷不完,哪有心思写啊``` 现在集训终于完了,有了属于自己的时间了.所以该把以前做的题,学的算法好好的整理整理了.一来顺顺思路,二来也可以给后来 ...
- http://blog.csdn.net/carolzhang8406/article/details/7196011
http://blog.csdn.net/carolzhang8406/article/details/7196011
- [状压dp]HDU3001 Travelling
题意: 走n个城市, m条路, 起点任意, 每个城市走不超过两次, 求最小花费, 不能走输出-1. $1\le n\le 10$ 分析: 每个城市的拜访次数为0 1 2, 所以三进制状压, 先预处理1 ...
- 万能脚本助Web执行底层Linux命令
需求分析: 这里先要说明的是,这一篇不是QT系列的文章,而是关于Web的,之所以要写这篇,是因为以前做Web相关开发的时候,经常涉及到与linux底层命令打交道,比如说创建一个目录,删除一个目录,或者 ...