java 简单操作HDFS
创建java 项目
package com.yw.hadoop273; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.junit.Test; import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection; /**
* 完成hdfs操作
* @Auther: YW
* @Date: 2019/9/11 21:51
* @Description:
*/
public class TestHdfs {
/**
* 读取hdfs文件
*/
@Test
public void readFile() throws Exception{
//注册url流处理器工厂(hdfs)
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); URL url = new URL("hdfs://http://192.168.248.129:8020/usr/local/hadoop/core-site.xml");
URLConnection conn = url.openConnection();
InputStream is = conn.getInputStream();
byte[] buf = new byte[is.available()];
is.read(buf);
is.close();
String str = new String(buf);
System.out.println(str);
} /**
* 通过hadoop API访问文件
*/
@Test
public void readFileByAPI() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.248.129:8020/");
FileSystem fs = FileSystem.get(conf) ;
Path p = new Path("/usr/local/hadoop/core-site.xml");
FSDataInputStream fis = fs.open(p);
byte[] buf = new byte[1024];
int len = -1 ; ByteArrayOutputStream baos = new ByteArrayOutputStream();
while((len = fis.read(buf)) != -1){
baos.write(buf, 0, len);
}
fis.close();
baos.close();
System.out.println(new String(baos.toByteArray()));
}
/**
* 通过hadoop API访问文件
*/
@Test
public void readFileByAPI2() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.248.129:8020/");
FileSystem fs = FileSystem.get(conf) ;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Path p = new Path("/usr/local/hadoop/core-site.xml");
FSDataInputStream fis = fs.open(p);
IOUtils.copyBytes(fis, baos, 1024);
System.out.println(new String(baos.toByteArray()));
} /**
* mkdir 创建目录
*/
@Test
public void mkdir() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.248.129:8020/");
FileSystem fs = FileSystem.get(conf) ;
fs.mkdirs(new Path("/usr/local/hadoop/myhadoop"));
} /**
* putFile 写文件
*/
@Test
public void putFile() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.248.129:8020/");
FileSystem fs = FileSystem.get(conf) ;
FSDataOutputStream out = fs.create(new Path("/usr/local/hadoop/myhadoop/a.txt"));
out.write("helloworld".getBytes());
out.close();
} /**
* removeFile 删除目录 (注意权限)
*/
@Test
public void removeFile() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.248.129:8020/");
FileSystem fs = FileSystem.get(conf) ;
Path p = new Path("/usr/local/hadoop/myhadoop");
fs.delete(p, true);
}
}
注意权限的修改
hdfs dfs -chmod 777 /usr/local/hadoop/

读到的内容
创建目录文件
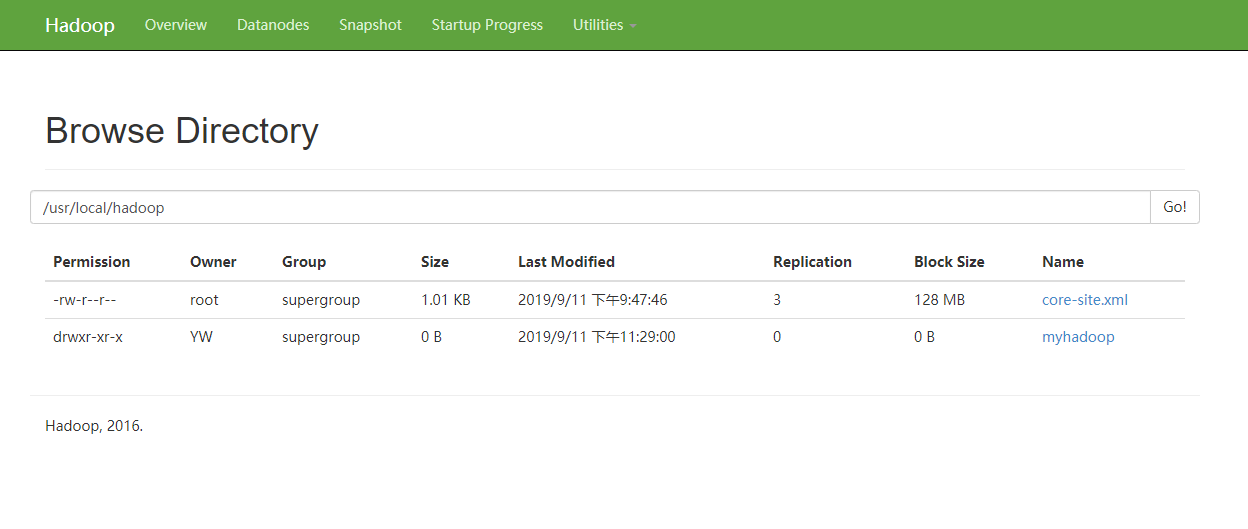
完成。。
java 简单操作HDFS的更多相关文章
- Java 简单操作hdfs API
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6632047118376780295/ 启动Hadoop出现问题:datanode的clusterID 和 name ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- Java代码操作HDFS测试类
1.Java代码操作HDFS需要用到Jar包和Java类 Jar包: hadoop-common-2.6.0.jar和hadoop-hdfs-2.6.0.jar Java类: java.net.URL ...
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
- Hadoop Java API操作HDFS文件系统(Mac)
1.下载Hadoop的压缩包 tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/ 2.关联jar包 在 ...
- 使用Java Api 操作HDFS
如题 我就是一个标题党 就是使用JavaApi操作HDFS,使用的是MAVEN,操作的环境是Linux 首先要配置好Maven环境,我使用的是已经有的仓库,如果你下载的jar包 速度慢,可以改变Ma ...
- 大数据-09-Intellij idea 开发java程序操作HDFS
主要摘自 http://dblab.xmu.edu.cn/blog/290-2/ 简介 本指南介绍Hadoop分布式文件系统HDFS,并详细指引读者对HDFS文件系统的操作实践.Hadoop分布式文件 ...
- Java代码操作HDFS(在/user/root/下面創建目錄)
1.创建HDFS目录并打成jar包 package Hdfs; import java.io.IOException; import java.net.URI; import org.apache.h ...
- hadoop 》》 django 简单操作hdfs 语句
>> from django.shortcuts import render # Create your views here. from hdfs.client import Clien ...
随机推荐
- Mysql 查看所有线程,被锁的表
查看所有MySQl相关的线程 show full processlist; 杀死线程id为2的线程 kill 2 查看服务器状态 show status like '%lock%'; 查看服务器配置参 ...
- PHP课程环境安装总结文档
phpStudy的安装 1.找一个硬盘根目录,比如这里我使用E盘,在E盘根目录创建一个php的文件夹,进入php文件夹,如下图所示 2.在步骤1的php文件夹下再建立一个文件夹php_dev,如下图所 ...
- 前端通用下载文件方法(兼容IE)
之前在网上看到一个博主写的前端通用的下载文件的方法,个人觉得很实用,所以mark一下,方便以后查阅 源文地址(源文还有上传/下载excel文件方法) 因为项目要求要兼容IE浏览器,所以完善了一下之前博 ...
- 【原创】aws s3 lambda缩略图生成
参考资料: https://github.com/sagidm/s3-resizer https://aws.amazon.com/cn/blogs/compute/resize-images-on- ...
- Remix 搭建与简单使用,并支持外部访问
Remix 搭建与简单使用,并支持外部访问 转 https://blog.csdn.net/linshenyuan1213/article/details/83444911 remix是基于浏览器的在 ...
- Flutter响应式编程 - RxDart
import 'package:flutter/material.dart'; import 'package:rxdart/rxdart.dart'; import 'dart:async'; cl ...
- Jmeter全局变量设置
背景:因为BeanShell PreProcessor制造的参数是一些随机参数,每个HTTP取样器包括其他取样器拿值得时候都是单独重新取一次,所以如果当几个取样器的值都要拿同一值时,就不满足需求了,我 ...
- Java8的时间日期API
原先的时间 api 大部分已经过时了 Date构造器 需要传入年月日 但是对时间的加减操作比较麻烦 Calenda 加减比较方便 使用 LocalDate. LocalTime. LocalDa ...
- Java socket详解
参考 https://www.jianshu.com/p/cde27461c226 刚给大家讲解Java socket通信后,好多童鞋私信我,有好多地方不理解,看不明白.特抽时间整理一下,详细讲述Ja ...
- 123457123456#0#-----com.ppGame.huaHua65--前拼后广--儿童填色-pp
com.ppGame.huaHua65--前拼后广--儿童填色-pp