【大数据系列】节点的退役和服役[datanode,yarn]
一、datanode添加新节点
1 在dfs.include文件中包含新节点名称,该文件在名称节点的本地目录下
[白名单]
[s201:/soft/hadoop/etc/hadoop/dfs.include]
2 在hdfs-site.xml文件中添加属性
<property>
<name>dfs.hosts</name>
<value>/soft/hadoop/etc/dfs.include.txt</value>
</property>
3 在nn上刷新节点
Hdfs dfsadmin -refreshNodes
4 在slaves文件中添加新节点ip(主机名)
5 单独启动新节点中的datanode
Hadoop-daemon.sh start datanode
二、datanode退役旧节点
1 添加退役节点的ip到黑名单 dfs.hosts.exclude,不要更新白名单
[/soft/hadoop/etc/dfs.hosts.exclude]
2 配置hdfs-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>/soft/hadoop/etc/dfs.hosts.exclude.txt</value>
</property>
3 刷新nn的节点
hdfs dfsadmin -refreshNodes
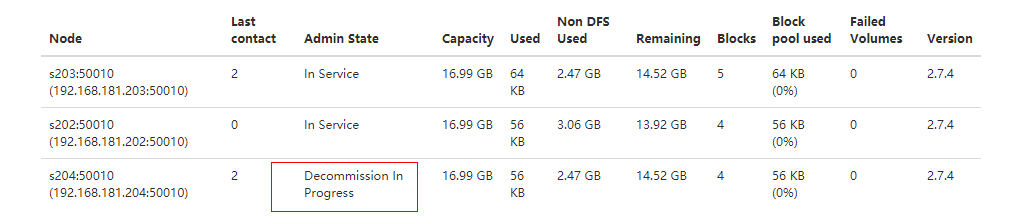
4 查看WEBUI,节点状态在Decommission In Progress
5 当所有的要退役的节点都报告为Decommissioned,数据转移工作已经完成
6 从白名单删除节点,并刷新节点
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
7 从slaves文件中删除退役的节点
8 hdfs-site.xml文件内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/soft/hadoop/name/</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/soft/hadoop/data</value>
</property>
<property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value>1024</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/soft/hadoop/etc/dfs.hosts.exclude.txt</value>
</property>
</configuration>
三、黑白名单组合结构
Include //dfs.hosts
Exclude //dfs.hosts.exclude
| 白名单 | 黑名单 | 组合结构 |
| No | No | Node may not connect |
| No | Yes | Node may not connect |
| Yes | No | Node may connect |
| Yes | Yes | Node may connect and will be decommissioned |
四、图文
黑名单文件

刷新节点信息

退役中
五、yarn添加新节点
1 在dfs.include文件中包含新节点名称,该文件在名称节点的本地目录下
[白名单]
[s201:/soft/hadoop/etc/hadoop/dfs.include]
2 在yarn-site.xml文件中添加属性
<property>
<name>yarn.resourcemanager.nodes.include-path</name>
<value>/soft/hadoop/etc/dfs.include.txt</value>
</property>
3 在rm上刷新节点
yarn rmadmin-refreshNodes
4 在slaves文件中添加新节点ip(主机名)
5 单独启动新节点中的资源管理器
yarn-daemon.sh start nodemanager
六、yarn退役新节点
1 添加退役节点的ip到黑名单 dfs.hosts.exclude,不要更新白名单
[/soft/hadoop/etc/dfs.hosts.exclude]
2 配置yarn-site.xml
<property>
<name>yarn-resourcemanager.nodes.exclude-path</name>
<value>/soft/hadoop/etc/dfs.hosts.exclude.txt</value>
</property>
3 刷新rm的节点
yarn rmadmin -refreshNodes
4 查看WEBUI,节点状态在Decommission In Progress
5 当所有的要退役的节点都报告为Decommissioned,数据转移工作已经完成
6 从白名单删除节点,并刷新节点
yarn rmadmin -refreshNodes
7 从slaves文件中删除退役的节点
注意:因为退役的时候副本数没有改变。所以要在退役的时候增加新的节点,只是做退役的话,因为不满足最小副本数要求,一直会停留在退役中,如果想更快的退役的话要使得退役后的副本数仍然达到最小副本数要求。
【大数据系列】节点的退役和服役[datanode,yarn]的更多相关文章
- 12.Linux软件安装 (一步一步学习大数据系列之 Linux)
1.如何上传安装包到服务器 有三种方式: 1.1使用图形化工具,如: filezilla 如何使用FileZilla上传和下载文件 1.2使用 sftp 工具: 在 windows下使用CRT 软件 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践
之前介绍过关于HBase 0.9.8版本的部署及使用,本篇介绍下最新版本HBase1.2.4的部署及使用,有部分区别,详见如下: 1. 环境准备: 1.需要在Hadoop[hadoop-2.7.3] ...
- 大数据系列之分布式数据库HBase-0.9.8安装及增删改查实践
若查看HBase-1.2.4版本内容及demo代码详见 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践 1. 环境准备: 1.需要在Hadoop启动正常情况下安 ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
随机推荐
- Git -- 工作区 和 暂存区
Git和其他版本控制系统如SVN的一个不同之处就是有暂存区的概念. 先来看名词解释. 工作区(Working Directory) 就是你在电脑里能看到的目录,比如我的learngit文件夹就是一个工 ...
- MYSQL的索引类型:PRIMARY, INDEX,UNIQUE,FULLTEXT,SPAIAL 有什么区别?各适用于什么场合?
一.介绍一下索引的类型 Mysql常见索引有:主键索引.唯一索引.普通索引.全文索引.组合索引PRIMARY KEY(主键索引) ALTER TABLE `table_name` ADD PRIMAR ...
- CentOS 7 打开关闭FirewallD防火墙端口命令
CentOS 7 使用firewalld代替了原来的iptables,使用方法如下: >>>关闭防火墙 systemctl stop firewalld.service ...
- VS2012:升级Update2和Update3均告损坏,重装方法
My steps (after backing up everything before deleting it): 1. Uninstalled VS2012 Pro from Windows 8 ...
- Android OpenGL ES 离屏渲染(offscreen render)
通常在Android上使用OpenGL ES,都是希望把渲染后的结果显示在屏幕上,例如图片处理.模型显示等.这种情况下,只需要使用Android API中提供的GLSurfaceView类和Rende ...
- 黏性Session和非黏性Session
黏性Session和非黏性Session黏性Session:此模式下同一会话中的请求都被派送到同一个tomcat实例上,这样我们就无须在多台服务器之间实现session共享了,这是其好处,不好的地方就 ...
- 《HTTP权威指南》学习笔记——HTTP报文
HTTP报文 HTTP:互联网的信使 HTTP报文:信使用来搬东西的包裹 1.报文流 HTTP报文:HTTP应用程序之间发送的数据块 组成:元信息开头(文本形式,描述报文的内容和含义)+可选的数据部分 ...
- Dos命令大全(1)
MS DOS 命令大全 一.基础命令 1 dir 无参数:查看当前所在目录的文件和文件夹. /s:查看当前目录已经其所有子目录的文件和文件夹. /a:查看包括隐含文件的所有文件. /ah:只显示出隐含 ...
- geoserver PostGIS的安装和使用
PostGIS是一个非常流行并且开源的具有空间分析能力的关系型数据库,它作为PostgreSQL数据库的一个插件.PostgreSQL是一个功能非常强大并且开源的关系型数据库.目前项目使用的版本为Po ...
- VS或编译的时候不生成Release文件夹
今天在编译第三方类的时候,总是发布的时候报没有第三方类库的的Release版本 解决方案: Build=>Configuration Manager=>Release 编译=>配置管 ...