大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~
大数据系列之数据仓库Hive原理
大数据系列之数据仓库Hive安装
大数据系列之数据仓库Hive中分区Partition如何使用
大数据系列之数据仓库Hive命令使用及JDBC连接

Hive主要分为以下几个部分
⽤户接口
1.包括CLI,JDBC/ODBC,WebUI
元数据存储(metastore)
1.默认存储在⾃带的数据库derby中,线上使⽤时⼀般换为MySQL
驱动器(Driver)
1.解释器、编译器、优化器、执⾏器
Hadoop
1.⽤MapReduce 进⾏计算,⽤HDFS 进⾏存储
前提部分:Hive的安装需要在Hadoop已经成功安装且成功启动的基础上进行安装。若没有安装请移步至大数据系列之Hadoop分布式集群部署。
使用包: apache-hive-2.1.1-bin.tar.gz, mysql-connector-java-5.1.27-bin.jar
云盘,密码:seni
本文将Hive安装在Hadoop Master节点上,以下操作仅在master服务器上进行操作。
1. 切换至普通用户 su mfz
2. 将gz包上传至目录下
/home/mfz
3.解压
tar -xzvf apache-hive-2.1.1-bin.tar.gz
4.目录:

5.创建hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>ThriftURIfor theremotemetastore. Usedbymetastoreclientto connectto remotemetastore.</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_13?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>locationofdefault databasefor thewarehouse</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>SchemaTable</value>
</property>
<property>
<name>datanucleus.schema.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>beeline.hs2.connection.user</name>
<value>mfz</value>
</property>
<property>
<name>beeline.hs2.connection.password</name>
<value>111111</value>
</property>
</configuration>
5.1由配置文件可看出,我们需要mysql的数据库hive_13,数据库用户名为hadoop,数据库密码为hadoop.
6.安装mysql
6.1 安装参考文章:Linux学习之CentOS(十三)--CentOS6.4下Mysql数据库的安装与配置
6.2 建立mysql数据库、用户、权限 参考文章:使用MySQL命令行新建用户并授予权限的方法
7.启动验证Mysql是否安装配置成功 :使用hadoop用户登录
mysql -u hadoop -p

8.配置hive环境变量:
vi /home/mfz/.bash_profile
#Hive CONFIG
export HIVE_HOME=/home/mfz/apache-hive-2.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin #wq .bash_profile
#生效配置
source /home/mfz/.bash_profile
#验证是否生效
echo $HIVE_HOME [mfz@master apache-hive-2.1.1-bin]$ echo $HIVE_HOME
/home/mfz/apache-hive-2.1.1-bin
9. 将mysql的java connector复制到依赖库中
cp resources/msyql/mysql-connector-java-5.1.27-bin.jar apache-hive-2.1.1-bin/bin/
10.启动hive,命令: hive; 若出现如下几种错误请参照对应解决方案;
错误1:
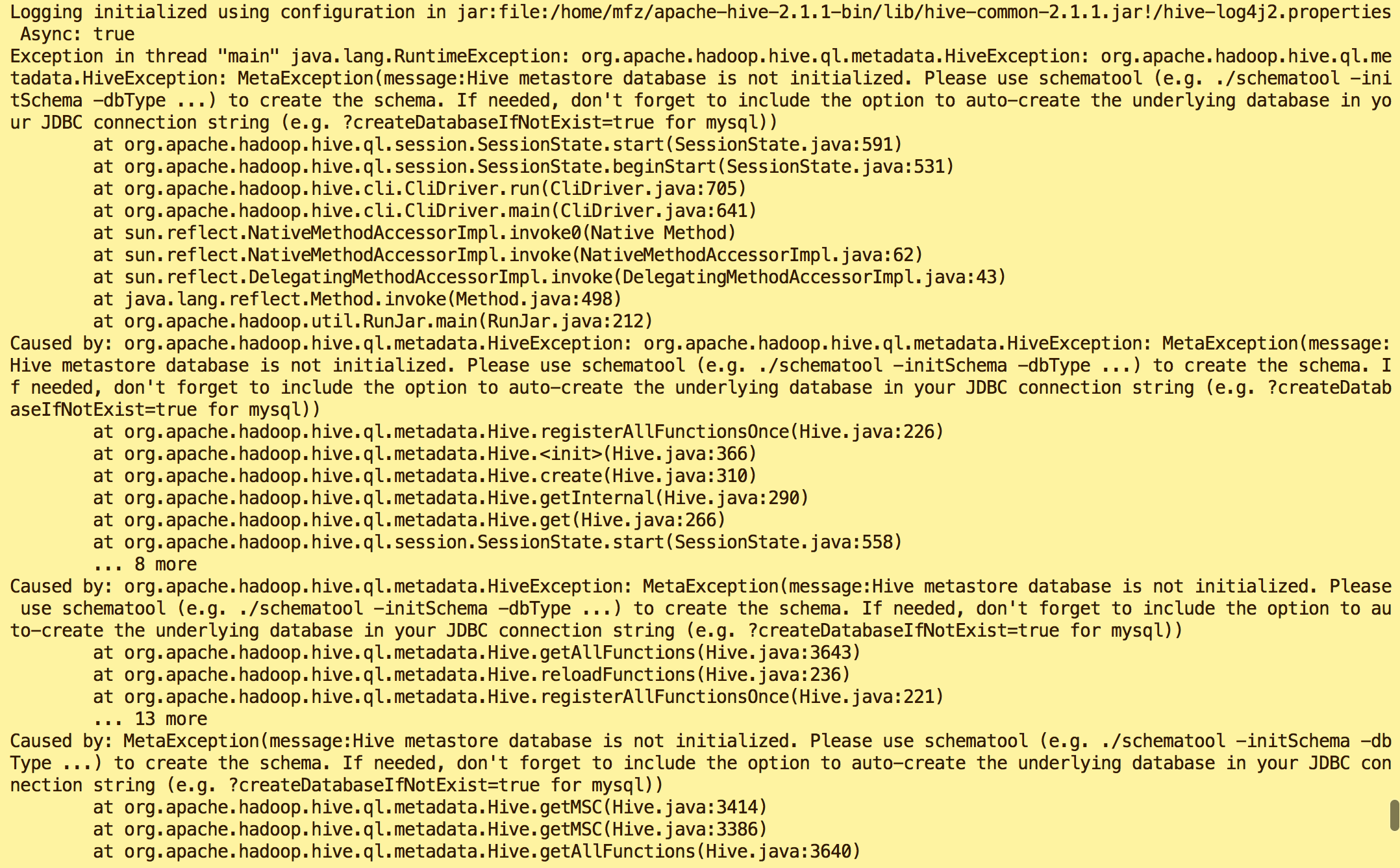
原因:Hive metastore database is not initialized
解决方案:执行命令
schematool -dbType mysql -initSchema
错误2:
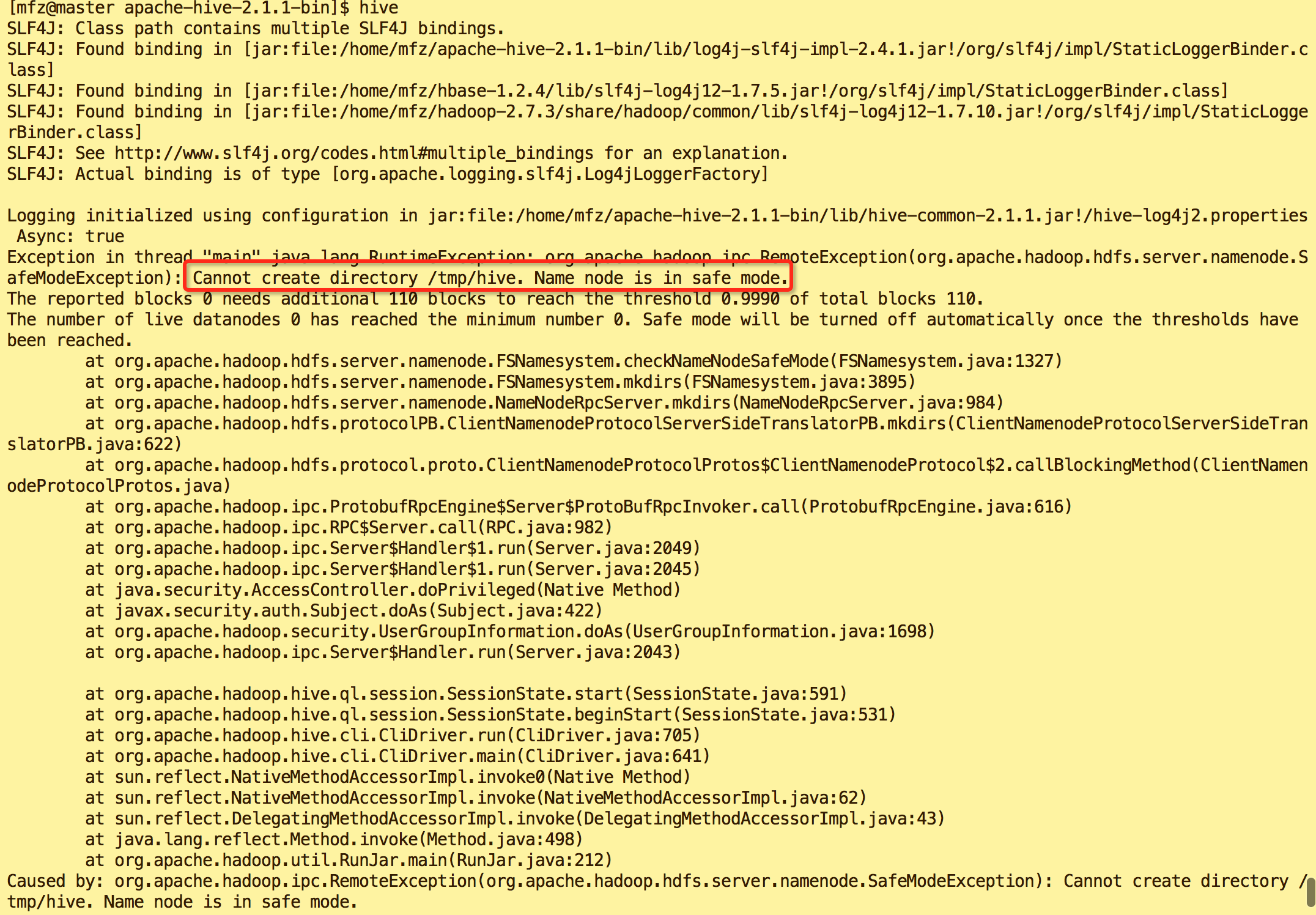
原因:hadoop 安全模式打开导致
解决方案:执行命令
#关闭hadoop安全模式
hadoop dfsadmin -safemode leave
11.启动hive.
A.方式1: hive命令

B.方式2(重要):
beeline
!connect jdbc:hive2://master:10000/default mfz 111111
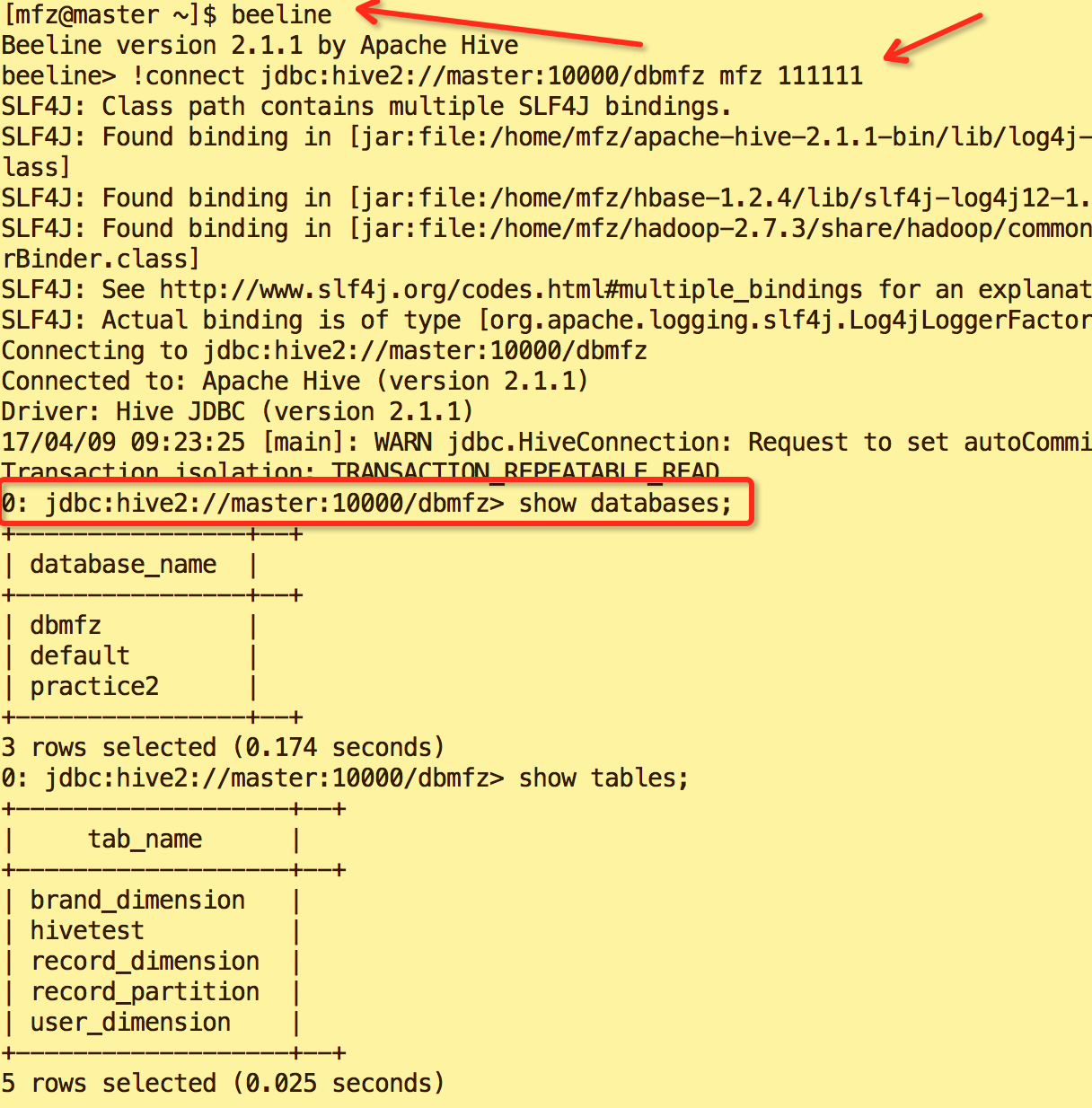
说明default是database名称,mfz是master服务器用户,111111是用户的登录密码.
因为beeline是取代hive客户端的新客户端,它访问HS2来发起hive操作,但是别急着敲下命令,继续往下看:这里涉及一个hadoop.proxy的概念:默认HS2是以user=anonymous身份访问Hdfs的,我们称HS2是hadoop的一个代理服务。但是,我们实际上希望以mfz身份去访问hdfs,因为此前创建的hive数据目录都是属于mfz用户的,anonymous是无法访问的,那么此时就需要给hadoop配置一个proxyuser,意思是HS2代理可以支持用户以mfz身份访问hdfs,而不是anonymous用户。
为了实现这个能力,需要修改hadoop项目的core-site.xml配置来实现(记得重启namenode和datanode):
<property>
<name>hadoop.proxyuser.mfz.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.mfz.hosts</name>
<value>*</value>
</property>
10.hive 使用命令.
数据定义语句DDL
Create/Drop/Alter Database
Create/Drop/Truncate Table
Alter Table/Partition/Column
Create/Drop/Alter View
Create/Drop/Alter Index
Create/Drop Function
Create/Drop/Grant/Revoke Roles and Privileges
Show
Describe
完~ 关于Hive的Nosql操作命令与Jdbc访问Hive方式见博文 大数据系列之数据仓库Hive使用
转载请注明出处:
作者:mengfanzhu
原文链接:http://www.cnblogs.com/cnmenglang/p/6661488.html
大数据系列之数据仓库Hive安装的更多相关文章
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive中分区Partition如何使用
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 【大数据系列】apache hive 官方文档翻译
GettingStarted 开始 Created by Confluence Administrator, last modified by Lefty Leverenz on Jun 15, 20 ...
- 【大数据系列】win10上安装hadoop开发环境
为了方便采用了Cygwin模拟linux环境的方法 一.安装JDK以及下载hadoop hadoop官网下载hadoop http://hadoop.apache.org/releases.html ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 12.Linux软件安装 (一步一步学习大数据系列之 Linux)
1.如何上传安装包到服务器 有三种方式: 1.1使用图形化工具,如: filezilla 如何使用FileZilla上传和下载文件 1.2使用 sftp 工具: 在 windows下使用CRT 软件 ...
随机推荐
- [转帖] 大神 Linus Torvalds 语录
My name is Linus Torvalds and I am your god.我的名字是Linus Torvalds,我是你们的上帝.(在1998 Linux大会上的自我介绍) If you ...
- Spring之jdbcTemplate:增删改
JdbcTemplate增删改数据操作步骤:1.导入jar包:2.设置数据库信息:3.设置数据源:4.调用jdbcTemplate对象中的方法实现操作 package helloworld.jdbcT ...
- 简易处理图片在div中居中铺满
原文地址:http://www.cnblogs.com/JimmyBright/p/7681089.html 经常需要在一个长宽固定的div里存放一个图片,这个图片长宽未知,所以需要图片自适应div显 ...
- STM32配置GPIO前须先打开其时钟,否则配置失败
@2018-5-9 17:11:38 STM32配置GPIO前须先打开其时钟,否则配置失败
- jq给单选框 radio添加或删除选中状态
$("#div1 :radio").removeAttr("checked");//删除目标div下所有单选框的选中状态 $("#div1 :radi ...
- Spring MVC 向页面传值-Map、Model和ModelMap
原文链接:https://www.cnblogs.com/caoyc/p/5635878.html Spring MVC 向页面传值-Map.Model和ModelMap 除了使用ModelAndVi ...
- Nginx反向代理2--配置文件配置
2.1Nginx的反向代理 什么是正向代理? 1.2 使用nginx实现反向代理 Nginx只做请求的转发,后台有多个http服务器提供服务,nginx的功能就是把请求转发给后面的服务器,决定把请 ...
- 函数和常用模块【day06】:模块特殊变量(十四)
from test import test ''' __mame__ # 当前文件为主文件是等于__main__.用于调用时不执行一些命令 __file__ # 当前文件的路径,相对路径 __cach ...
- Python字符串,整型,浮点数相互转化
Python字符串,整型,浮点数相互转化 觉得有用的话,欢迎一起讨论相互学习~Follow Me int(str) 函数将符合整数的规范的字符串转换成int型 float(str) 函数将符合浮点数的 ...
- centos内存自动清理脚本及限制tomcat内存占用
使用crontab定时每天自动清理系统内存 00 00 * * * /root/Cached.sh [root@localhost ~]# cat Cachec.sh #! /bin/bash# ca ...