Q-Learning
一、Q-Learning:
例子:https://www.zhihu.com/question/26408259/answer/123230350
http://ml.cs.tsinghua.edu.cn:5000/demos/flappybird/

以上为Q-Learning的伪代码
Q(S,A)可以是一个查找表,也可以是一个神经网络。
其中最重要的公式是: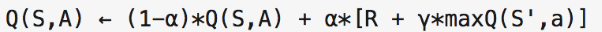
其中1-alpha是保留多少以前的经验,gamma是对最长期reward进行discount
(这个公式有四个好处:1、不需要知道状态之间的transition probaility(model free) 2、不需要等到episode结束后才更新Q值(相比于MCTS) 3、收敛到最优解 4、off-policy)
二、神经网络的加入:
当输入状态比较大的时候,Q值表就非常的大,所以就只能使用神经网络了。
这时候,就设计Q值网络训练的问题。为了对神经网络进行训练,可以把Q值网络的损失函数设为一个回归问题。
回归问题和神经网络的优势有两点:
1、可以进行神经网络训练,使得庞大的state空间进行压缩。
2、对原始经验的保存变成了网络参数的保存。
三、探索:
一般情况下,Q-Learning对自己经常经历的一段路径估计比较准,对于没经常经历的估计不那么准。所以,会出现一种情况就是:在前期Q值估计不准的情况下,对某一本质上很好的决策进行了错误估计,认为这段路径会很差,导致以后选择了一个错误的决策,然后就会一直在这个错误的方向下一直走下去,不会回过头来探索本质上很好的那个决策。
所以,一般在前期的时候,我们会进行随机的探索不同的路径,获得一个比较好的初始Q值。
四、利用
但是由于状态空间过大,完全随机探索可能出现一个问题:状态空间大,采样不够,Q值估计不准。
而且,其实我们最终关心的只是表现好好的状态及其周边状态的Q值。所以,在随机探索初始化Q值后,我们通过Q值来选取我们关心的状态,加大对我们关心状态的训练。
五、replay-memory
我们如果在线训练,可能模拟器非常慢,RL训练需要等待模拟器准备数据。所以我们可以把数据存到replay-memory里面,然后用来训练。
另一个好处就是,在线训练的数据和当前神经网络的参数有很大的联系,导致数据自产自销,数据不够客观,可能最终处于某种恶性循环。
六、一个变态的RL任务
有这样一种RL任务:
1、你只要随机探索,基本上就到不了你最终关心的状态,采样出来的数据对最终关心状态无关。
2、当你不随机探索,由于神经网络没见过好的状态,对好的状态的估值并不好,也不会进入好的状态。
3、很难或者没法进行仿真模拟、回溯等,也就是出现好状态时,很难加大对好状态的采样。
所以,agent会一直无法进入最终关心的状态,也就不会进行相应的数据采样,导致agent收敛到局部最优解,当然这种局部最优解可能是我们完全没法忍受的。我们对于这种任务,我们应该怎么解决?
有人提出了对状态进行reconstruction,就是当状态没怎么见过时,给个较大的reward,这样去帮助agent去进入没见过的状态。
但是,个人觉得这种方法有两个问题:一个是reconstruction的loss是否可靠,能否代表对未见过状态的表示,这个是没办法很好回答的。二个是我们本质上只是想加大进入好状态的概率,而不是进入未知状态的概率,所以这种方法可能最终对实际任务没有太大帮助。
那么有什么解决办法呢?主要有一下几点:
1、人为先验知识:对于一个封闭系统来说,如果内部因素全都考虑到了,还是存在问题,就只能依靠外部力量进行解决。
a、人为选择好的action。对于在某些状态下,如果人类很明确知道某个action会更好,那么我们可以帮助agent进行选择action,以便更多地进入关心的状态。这里不是简单的帮助agent进行人为选择action,真正目的是为了加大好数据的采样量。
b、监督训练获得更好的feature表示。对于状态空间大的情况,我们通过神经网络对状态进行压缩,希望对坏状态有个相似的feature表示,但是,rl任务并没有很明确的监督信息,feature的表示能力和泛化能力可能很弱,加入监督信号,对feature学习进行一个很好的表示,以便对于好坏状态有更好的表示,同时提高泛化能力。
2、期望于内部pattern:作为机器学习的人员,我们希望找到所有内部系统的自身pattern,所有我们寄希望于这个rl系统还隐藏着未被发现的pattern。
a、rewards:一个rl任务可能有多种reward,特别是对于复杂的任务,一般都有很多的评价指标,这些评价指标可能隐藏着某种pattern,如何利用其中的pattern?
七、RL工作方向
1、并行化,加速采(A3C)
2、multi-reward,处理隐藏的rewards pattern
3、训练方式变化,解决神经网络欠拟合,过拟合,不稳定等问题。(进化策略)
4、连续action?
Q-Learning的更多相关文章
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- 如何用简单例子讲解 Q - learning 的具体过程?
作者:牛阿链接:https://www.zhihu.com/question/26408259/answer/123230350来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- 增强学习(五)----- 时间差分学习(Q learning, Sarsa learning)
接下来我们回顾一下动态规划算法(DP)和蒙特卡罗方法(MC)的特点,对于动态规划算法有如下特性: 需要环境模型,即状态转移概率\(P_{sa}\) 状态值函数的估计是自举的(bootstrapping ...
- deep Q learning小笔记
1.loss 是什么 2. Q-Table的更新问题变成一个函数拟合问题,相近的状态得到相近的输出动作.如下式,通过更新参数 θθ 使Q函数逼近最优Q值 深度神经网络可以自动提取复杂特征,因此,面对高 ...
- To discount or not to discount in reinforcement learning: A case study comparing R learning and Q learning
https://www.cs.cmu.edu/afs/cs/project/jair/pub/volume4/kaelbling96a-html/node26.html [平均-打折奖励] Schwa ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- Top Deep Learning Projects in github
Top Deep Learning Projects A list of popular github projects related to deep learning (ranked by sta ...
- Open source packages on Deep Reinforcement Learning
智能车 self driving car + 强化学习 reinforcement learning + 神经网络 模拟 https://github.com/MorvanZhou/my_resear ...
- Teaching Your Computer To Play Super Mario Bros. – A Fork of the Google DeepMind Atari Machine Learning Project
Teaching Your Computer To Play Super Mario Bros. – A Fork of the Google DeepMind Atari Machine Learn ...
随机推荐
- [Windows Azure] Data Management and Business Analytics
http://www.windowsazure.com/en-us/develop/net/fundamentals/cloud-storage/ Managing and analyzing dat ...
- (原创)拨开迷雾见月明-剖析asio中的proactor模式(一)
使用asio之前要先对它的设计思想有所了解,了解设计思想将有助于我们理解和应用asio.asio是基于proactor模式的,asio的proactor模式隐藏于大量的细节当中,要找到它的踪迹,往往有 ...
- (转)CTP: 平昨仓与平今仓,log轻轻告诉你.......
转自:http://blog.csdn.net/wowotuo/article/details/43242663 CTP的相关文档告诉我们,中金所和三大商品交易所中,只有上期所区分平今仓和平昨仓.也就 ...
- 图解zookeeper FastLeader选举算法【转】
转自:http://codemacro.com/2014/10/19/zk-fastleaderelection/ zookeeper配置为集群模式时,在启动或异常情况时会选举出一个实例作为Leade ...
- 【Android】事件处理系统
linux输入子系统 Android是linux内核的,所以它的事件处理系统也在linux的基础上完成的. Linux内核提供了一个Input子系统来实现的,Input子系统会在/dev/input/ ...
- Docker 构建网络服务后本机不能访问
Docker 构建网络服务后本机不能访问 起因 使用tornado构建了一个服务,测试都没有问题 使用docker构建镜像,使用docker run image_name启动服务 使用浏览器访问 12 ...
- muduo源码分析:组成结构
muduo整体由许多类组成: 这些类之间有一些依赖关系,如下:
- Python实现二叉树的左中右序遍历
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/3/18 12:31 # @Author : baoshan # @Site ...
- 【Ubuntu】任务管理器loadruner
linux1 准备工作 可以通过两种方法验证服务器上是否配置了rstatd守护程序: ①使用rup命令,它用于报告计算机的各种统计信息,其中就包括rstatd的配置信息.使用命令rup 10 ...
- eclipse Maven 使用记录 ------ 建立app项目
maven 项目构建工具 , 如今已逐渐取代ant的笨拙配置方式 ,使项目管理更加简单,规范,结构更加清晰,这里记录跟eclipse集成的一些步骤 1.从apache maven项目下下载maven ...