python 皮尔森相关系数
皮尔森理解
皮尔森相关系数(Pearson correlation coefficient)也称皮尔森积矩相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关程度的统计量。相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的绝对值越大表明相关性越强。
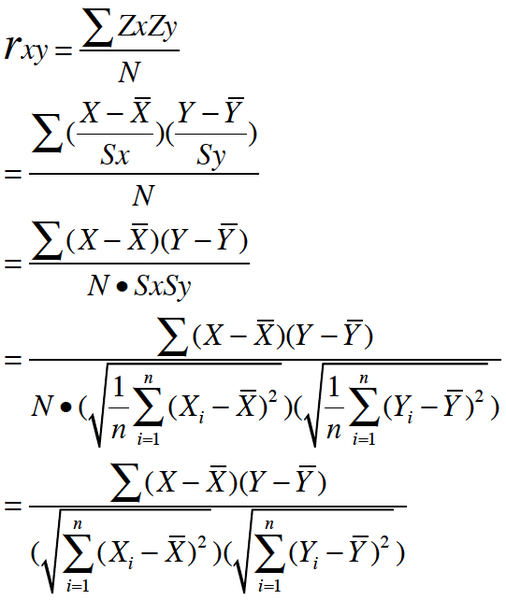
简单的相关系数的分类
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
r描述的是两个变量间线性相关强弱的程度。r的取值在-1与+1之间,若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。r 的绝对值越大表明相关性越强,要注意的是这里并不存在因果关系。
python 实现
# encoding:utf-8
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plot
import math
#target_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data")
#rockVMines = pd.read_csv(target_url ,header=None,prefix="V") #prefix前缀
rockVMines = pd.read_csv('../rockdata.txt',header=None,prefix="V") #prefix前缀
row2 = rockVMines.iloc[1,0:60]
row3 = rockVMines.iloc[2,0:60]
n = len(row2)
mean2 = row2.mean()
mean3 = row3.mean()
t2=0 ; t3=0;t1=0
for i in range(n):
t2 += (row2[i] - mean2) * (row2[i] - mean2) / n
t3 += (row3[i] - mean3) * (row3[i] - mean3) / n
r23=0
for i in range(n):
r23 += (row2[i] - mean2)*(row3[i] - mean3)/(n* math.sqrt(t2 * t3))
print r23
corMat = DataFrame(rockVMines.corr()) #corr 求相关系数矩阵
print corMat
plot.pcolor(corMat)
plot.show()
python 皮尔森相关系数的更多相关文章
- Spearman秩相关系数和Pearson皮尔森相关系数
1.Pearson皮尔森相关系数 皮尔森相关系数也叫皮尔森积差相关系数,用来反映两个变量之间相似程度的统计量.或者说用来表示两个向量的相似度. 皮尔森相关系数计算公式如下:
- 【ML基础】皮尔森相关系数(Pearson correlation coefficient)
前言 参考 1. 皮尔森相关系数(Pearson correlation coefficient): 完
- spark MLlib 概念 1:相关系数( PPMCC or PCC or Pearson's r皮尔森相关系数) and Spearman's correlation(史匹曼等级相关系数)
皮尔森相关系数定义: 协方差与标准差乘积的商. Pearson's correlation coefficient when applied to a population is commonly r ...
- 相关性系数及其python实现
参考文献: 1.python 皮尔森相关系数 https://www.cnblogs.com/lxnz/p/7098954.html 2.统计学之三大相关性系数(pearson.spearman.ke ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (二)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- python 推荐算法
每个人都会有这样的经历:当你在电商网站购物时,你会看到天猫给你弹出的“和你买了同样物品的人还买了XXX”的信息:当你在SNS社交网站闲逛时,也会看到弹出的“你可能认识XXX“的信息:你在微博添加关注人 ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (四)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (三)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- Python金融量化
Python股票数据分析 最近在学习基于python的股票数据分析,其中主要用到了tushare和seaborn.tushare是一款财经类数据接口包,国内的股票数据还是比较全的 官网地址:http: ...
随机推荐
- 0R的电阻以及NC的意义
0欧电阻的作用: 0欧的电阻大概有以下几个功能:①做为跳线使用.这样既美观,安装也方便.②在数字和模拟等混合电路中,往往要求两个地分开,并且单点连接.我们可以用一个0欧的电阻来连接这两个地,而不是直接 ...
- slice 定义和用法
定义和用法 slice() 方法可从已有的数组中返回选定的元素. 语法 arrayObject.slice(start,end) 参数 描述 start 必需.规定从何处开始选取.如果是负数,那么它规 ...
- Android.mk (1) 函数
https://www.jianshu.com/p/46224d15fc5f 从函数说起 大家都习惯看从头,从构建目标讲起的,导致每篇文档熟的都是前面的部分.很多教程也都是想办法能够观其大略,从整体上 ...
- MyBatis学习之SpringMvc和MyBatis整合
1. 整合流程 Dao层: 1. SqlMapConfig.xml,空文件即可,需要文件头. 2. applicationContext-dao.xml. a) 数据库连接池 b) SqlSessio ...
- sencha touch 常见问题解答(1-25)
欢迎留言补充,持续更新中... 1.sencha touch 是什么? 答:Sencha touch框架是世界上第一个基于HTML 5的移动应用框架.它可以让你的Web应用看起来像网络应用.美丽的用户 ...
- NET中的设计模式---单件模式
如众所知,单件模式做为<Gof 23中设计模式>之一,其意图仅允许单件类的一个实例存在(扩展单件模式不在此文范围内),并提供全局的访问方法.UML类图如下. http://csharpin ...
- iOS 循环引用 委托 (实例说明)
如何避免循环引用造成的内存泄漏呢: 以delegate模式为例(viewcontroller和view之间就是代理模式,viewcontroller有view的使用权,viewcontroller同时 ...
- python WEB UI自动化在日期框中动态输入当前日期
要在日期框中输入当前日期,如下图 代码为 本想用最简单的方法,直接用sendkeys发送当前日期,如下: current_time=time.strftime('%Y-%m-%d',time.loca ...
- Jmeter TCP取样器配置及发送图解
最近在通过Jmeter测试TCP发送请求时,遇到相关问题,现记录 查看管方文档,TCP发送有三种启用方式: TCPClientImpl:文本数据,默认为这种 BinaryTCPClientImpl:传 ...
- oracle如何设置表空间autoextensible自动扩容
SELECT a.tablespace_name "表空间名", total / 1024 / 1024 "表空间大小单位M", free / 1024 / 1 ...