Kafka:ZK+Kafka+Spark Streaming集群环境搭建(六)针对spark2.2.1以yarn方式启动spark-shell抛出异常:ERROR cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Sending RequestExecutors(0,0,Map(),Set()) to AM was unsuccessful
Spark以yarn方式运行时抛出异常:
[spark@master bin]$ cd /opt/spark-2.2.-bin-hadoop2./bin
[spark@master bin]$ ./spark-shell --master yarn-client
Warning: Master yarn-client is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://192.168.0.120:4040
Spark context available as 'sc' (master = yarn, app id = application_1530369937777_0003).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.
/_/ Using Scala version 2.11. (Java HotSpot(TM) -Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information. scala> // :: ERROR cluster.YarnClientSchedulerBackend: Yarn application has already exited with state FAILED!
// :: ERROR client.TransportClient: Failed to send RPC to /192.168.0.121:: java.nio.channels.ClosedChannelException
java.nio.channels.ClosedChannelException
at io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source)
// :: ERROR cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Sending RequestExecutors(,,Map(),Set()) to AM was unsuccessful
java.io.IOException: Failed to send RPC to /192.168.0.121:: java.nio.channels.ClosedChannelException
at org.apache.spark.network.client.TransportClient.lambda$sendRpc$(TransportClient.java:)
at io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:)
at io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:)
at io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:)
at io.netty.util.concurrent.DefaultPromise.tryFailure(DefaultPromise.java:)
at io.netty.channel.AbstractChannel$AbstractUnsafe.safeSetFailure(AbstractChannel.java:)
at io.netty.channel.AbstractChannel$AbstractUnsafe.write(AbstractChannel.java:)
at io.netty.channel.DefaultChannelPipeline$HeadContext.write(DefaultChannelPipeline.java:)
at io.netty.channel.AbstractChannelHandlerContext.invokeWrite0(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext.invokeWrite(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext.access$(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.write(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext$WriteAndFlushTask.write(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.run(AbstractChannelHandlerContext.java:)
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:)
at io.netty.util.concurrent.SingleThreadEventExecutor$.run(SingleThreadEventExecutor.java:)
at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.nio.channels.ClosedChannelException
at io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source)
// :: ERROR util.Utils: Uncaught exception in thread Yarn application state monitor
org.apache.spark.SparkException: Exception thrown in awaitResult:
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:)
at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.requestTotalExecutors(CoarseGrainedSchedulerBackend.scala:)
at org.apache.spark.scheduler.cluster.YarnSchedulerBackend.stop(YarnSchedulerBackend.scala:)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.stop(YarnClientSchedulerBackend.scala:)
at org.apache.spark.scheduler.TaskSchedulerImpl.stop(TaskSchedulerImpl.scala:)
at org.apache.spark.scheduler.DAGScheduler.stop(DAGScheduler.scala:)
at org.apache.spark.SparkContext$$anonfun$stop$.apply$mcV$sp(SparkContext.scala:)
at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:)
at org.apache.spark.SparkContext.stop(SparkContext.scala:)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend$MonitorThread.run(YarnClientSchedulerBackend.scala:)
Caused by: java.io.IOException: Failed to send RPC to /192.168.0.121:: java.nio.channels.ClosedChannelException
at org.apache.spark.network.client.TransportClient.lambda$sendRpc$(TransportClient.java:)
at io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:)
at io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:)
at io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:)
at io.netty.util.concurrent.DefaultPromise.tryFailure(DefaultPromise.java:)
at io.netty.channel.AbstractChannel$AbstractUnsafe.safeSetFailure(AbstractChannel.java:)
at io.netty.channel.AbstractChannel$AbstractUnsafe.write(AbstractChannel.java:)
at io.netty.channel.DefaultChannelPipeline$HeadContext.write(DefaultChannelPipeline.java:)
at io.netty.channel.AbstractChannelHandlerContext.invokeWrite0(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext.invokeWrite(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext.access$(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.write(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext$WriteAndFlushTask.write(AbstractChannelHandlerContext.java:)
at io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.run(AbstractChannelHandlerContext.java:)
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:)
at io.netty.util.concurrent.SingleThreadEventExecutor$.run(SingleThreadEventExecutor.java:)
at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.nio.channels.ClosedChannelException
at io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source)
解决方案:
主要是给节点分配的内存少,yarn kill了spark application。
给yarn-site.xml增加配置:
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
重启hadoop。然后再重新执行./spark-shell --master yarn-client即可。
问题解决过程记录:
1)在master上将hadoop,spark服务停掉
[spark@master hadoop]$ cd /opt/hadoop-2.9.
[spark@master hadoop]$ sbin/stop-all.sh
[spark@master hadoop]$ cd /opt/spark-2.2.-bin-hadoop2.
[spark@master hadoop]$ sbin/stop-all.sh
2)在master上修改yarn-site.xml
[spark@master hadoop]$ cd /opt/hadoop-2.9./etc/hadoop
[spark@master hadoop]$ ls
capacity-scheduler.xml hadoop-env.cmd hadoop-policy.xml httpfs-signature.secret kms-log4j.properties mapred-env.sh slaves yarn-env.sh
configuration.xsl hadoop-env.sh hdfs-site.xml httpfs-site.xml kms-site.xml mapred-queues.xml.template ssl-client.xml.example yarn-site.xml
container-executor.cfg hadoop-metrics2.properties httpfs-env.sh kms-acls.xml log4j.properties mapred-site.xml ssl-server.xml.example
core-site.xml hadoop-metrics.properties httpfs-log4j.properties kms-env.sh mapred-env.cmd mapred-site.xml.template yarn-env.cmd
[spark@master hadoop]$ vi yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value></value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value></value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
</configuration>
~
~
~
"yarn-site.xml" 66L, 2285C written
3)将master上将l修改后的yarn-site.xm文件覆盖到各个slaves节点
[spark@master hadoop]$ scp -r /opt/hadoop-2.9./etc/hadoop/yarn-site.xml spark@slave1:/opt/hadoop-2.9./etc/hadoop/
yarn-site.xml % .6KB/s :
[spark@master hadoop]$ scp -r /opt/hadoop-2.9./etc/hadoop/yarn-site.xml spark@slave2:/opt/hadoop-2.9./etc/hadoop/
yarn-site.xml % .3KB/s :
[spark@master hadoop]$ scp -r /opt/hadoop-2.9./etc/hadoop/yarn-site.xml spark@slave3:/opt/hadoop-2.9./etc/hadoop/
yarn-site.xml % .5MB/s :
4)重新启动hadoop,spark服务
[spark@master hadoop]$ cd /opt/hadoop-2.9.
[spark@master hadoop]$ sbin/start-all.sh
[spark@master hadoop]$ cd /opt/spark-2.2.-bin-hadoop2.
[spark@master spark-2.2.-bin-hadoop2.]$ sbin/start-all.sh
[spark@master spark-2.2.-bin-hadoop2.]$ jps
ResourceManager
Master
SecondaryNameNode
Jps
NameNode
5)验证spark on yarn是否正常运行
[spark@master spark-2.2.-bin-hadoop2.]$ cd /opt/spark-2.2.-bin-hadoop2./bin
[spark@master bin]$ ./spark-shell --master yarn-client
Warning: Master yarn-client is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://192.168.0.120:4040
Spark context available as 'sc' (master = yarn, app id = application_1530373644791_0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.
/_/ Using Scala version 2.11. (Java HotSpot(TM) -Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information. scala>
[spark@master bin]$ ./spark-shell --master yarn
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://192.168.0.120:4040
Spark context available as 'sc' (master = yarn, app id = application_1530373644791_0002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.
/_/ Using Scala version 2.11. (Java HotSpot(TM) -Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information. scala>
spark on yarn启动spark-shell后,可以在yarn管理界面看到一个Runing Application
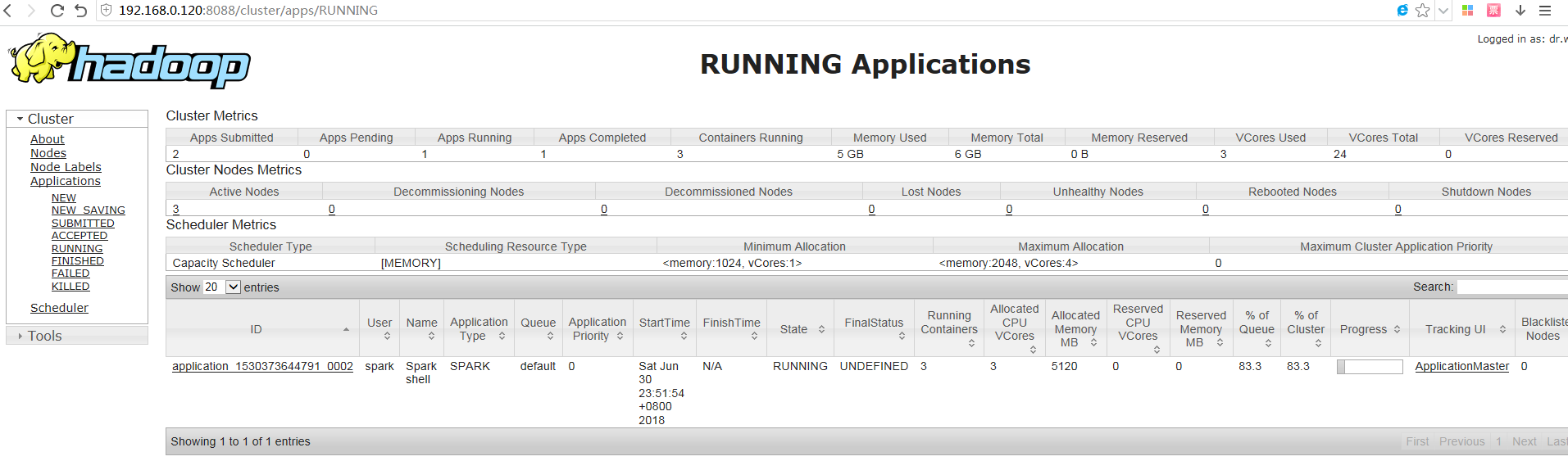
6)继续验证:以yarn-cluster方式运行一个spark任务测试是否正常
[spark@master bin]$ cd /opt/spark-2.2.-bin-hadoop2./
[spark@master spark-2.2.-bin-hadoop2.]$ ./bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master yarn \
> /opt/spark-2.2.-bin-hadoop2./examples/jars/spark-examples_2.-2.2..jar \
>
// :: INFO spark.SparkContext: Running Spark version 2.2.
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO spark.SparkContext: Submitted application: Spark Pi
// :: INFO spark.SecurityManager: Changing view acls to: spark
// :: INFO spark.SecurityManager: Changing modify acls to: spark
// :: INFO spark.SecurityManager: Changing view acls groups to:
// :: INFO spark.SecurityManager: Changing modify acls groups to:
// :: INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); groups with view permissions: Set(); users with modify permissions: Set(spark); groups with modify permissions: Set()
// :: INFO util.Utils: Successfully started service 'sparkDriver' on port .
// :: INFO spark.SparkEnv: Registering MapOutputTracker
// :: INFO spark.SparkEnv: Registering BlockManagerMaster
// :: INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
// :: INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
// :: INFO storage.DiskBlockManager: Created local directory at /opt/spark-2.2.-bin-hadoop2./blockmgr-121559e6-2f03-4f68--faf513bca0ac
// :: INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MB
// :: INFO spark.SparkEnv: Registering OutputCommitCoordinator
// :: INFO util.log: Logging initialized @1288ms
// :: INFO server.Server: jetty-9.3.z-SNAPSHOT
// :: INFO server.Server: Started @1345ms
// :: INFO server.AbstractConnector: Started ServerConnector@596df867{HTTP/1.1,[http/1.1]}{0.0.0.0:}
// :: INFO util.Utils: Successfully started service 'SparkUI' on port .
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@425357dd{/jobs,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@52eacb4b{/jobs/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2a551a63{/jobs/job,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@ec2bf82{/jobs/job/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6cc0bcf6{/stages,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@32f61a31{/stages/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@669253b7{/stages/stage,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@49a64d82{/stages/stage/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@66d23e4a{/stages/pool,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4d9d1b69{/stages/pool/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@251f7d26{/storage,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@52d10fb8{/storage/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1fe8d51b{/storage/rdd,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@22680f52{/storage/rdd/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@39c11e6c{/environment,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@503d56b5{/environment/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@433ffad1{/executors,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2575f671{/executors/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@ecf9fb3{/executors/threadDump,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@27f9e982{/executors/threadDump/json,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@37d3d232{/static,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@{/,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@c8b96ec{/api,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@58a55449{/jobs/job/kill,null,AVAILABLE,@Spark}
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6e0ff644{/stages/stage/kill,null,AVAILABLE,@Spark}
// :: INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.0.120:4040
// :: INFO spark.SparkContext: Added JAR file:/opt/spark-2.2.-bin-hadoop2./examples/jars/spark-examples_2.-2.2..jar at spark://192.168.0.120:41922/jars/spark-examples_2.11-2.2.1.jar with timestamp 1530375071834
// :: INFO client.RMProxy: Connecting to ResourceManager at master/192.168.0.120:
// :: INFO yarn.Client: Requesting a new application from cluster with NodeManagers
// :: INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster ( MB per container)
// :: INFO yarn.Client: Will allocate AM container, with MB memory including MB overhead
// :: INFO yarn.Client: Setting up container launch context for our AM
// :: INFO yarn.Client: Setting up the launch environment for our AM container
// :: INFO yarn.Client: Preparing resources for our AM container
// :: WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
// :: INFO yarn.Client: Uploading resource file:/opt/spark-2.2.-bin-hadoop2./spark-c4987503--4e4c-b170-301856a36773/__spark_libs__7066117465738289067.zip -> hdfs://master:9000/user/spark/.sparkStaging/application_1530373644791_0003/__spark_libs__7066117465738289067.zip
// :: INFO yarn.Client: Uploading resource file:/opt/spark-2.2.-bin-hadoop2./spark-c4987503--4e4c-b170-301856a36773/__spark_conf__2688610535686541958.zip -> hdfs://master:9000/user/spark/.sparkStaging/application_1530373644791_0003/__spark_conf__.zip
// :: INFO spark.SecurityManager: Changing view acls to: spark
// :: INFO spark.SecurityManager: Changing modify acls to: spark
// :: INFO spark.SecurityManager: Changing view acls groups to:
// :: INFO spark.SecurityManager: Changing modify acls groups to:
// :: INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); groups with view permissions: Set(); users with modify permissions: Set(spark); groups with modify permissions: Set()
// :: INFO yarn.Client: Submitting application application_1530373644791_0003 to ResourceManager
// :: INFO impl.YarnClientImpl: Submitted application application_1530373644791_0003
// :: INFO cluster.SchedulerExtensionServices: Starting Yarn extension services with app application_1530373644791_0003 and attemptId None
// :: INFO yarn.Client: Application report for application_1530373644791_0003 (state: ACCEPTED)
// :: INFO yarn.Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -
queue: default
start time:
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1530373644791_0003/
user: spark
// :: INFO yarn.Client: Application report for application_1530373644791_0003 (state: ACCEPTED)
// :: INFO yarn.Client: Application report for application_1530373644791_0003 (state: ACCEPTED)
// :: INFO yarn.Client: Application report for application_1530373644791_0003 (state: ACCEPTED)
// :: INFO yarn.Client: Application report for application_1530373644791_0003 (state: ACCEPTED)
// :: INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
// :: INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> master, PROXY_URI_BASES -> http://master:8088/proxy/application_1530373644791_0003), /proxy/application_1530373644791_0003
// :: INFO ui.JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
// :: INFO yarn.Client: Application report for application_1530373644791_0003 (state: RUNNING)
// :: INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.0.121
ApplicationMaster RPC port:
queue: default
start time:
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1530373644791_0003/
user: spark
// :: INFO cluster.YarnClientSchedulerBackend: Application application_1530373644791_0003 has started running.
// :: INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port .
// :: INFO netty.NettyBlockTransferService: Server created on 192.168.0.120:
// :: INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
// :: INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.0.120, , None)
// :: INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.0.120: with 366.3 MB RAM, BlockManagerId(driver, 192.168.0.120, , None)
// :: INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.0.120, , None)
// :: INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.0.120, , None)
// :: INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@58aa1d72{/metrics/json,null,AVAILABLE,@Spark}
// :: INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.0.123:59710) with ID 1
// :: INFO storage.BlockManagerMasterEndpoint: Registering block manager slave3: with 366.3 MB RAM, BlockManagerId(, slave3, , None)
// :: INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.0.122:36090) with ID 2
// :: INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
// :: INFO storage.BlockManagerMasterEndpoint: Registering block manager slave2: with 366.3 MB RAM, BlockManagerId(, slave2, , None)
// :: INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:
// :: INFO scheduler.DAGScheduler: Got job (reduce at SparkPi.scala:) with output partitions
// :: INFO scheduler.DAGScheduler: Final stage: ResultStage (reduce at SparkPi.scala:)
// :: INFO scheduler.DAGScheduler: Parents of final stage: List()
// :: INFO scheduler.DAGScheduler: Missing parents: List()
// :: INFO scheduler.DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at map at SparkPi.scala:), which has no missing parents
// :: INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1832.0 B, free 366.3 MB)
// :: INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1172.0 B, free 366.3 MB)
// :: INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.0.120: (size: 1172.0 B, free: 366.3 MB)
// :: INFO spark.SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO scheduler.DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at map at SparkPi.scala:) (first tasks are for partitions Vector(, , , , , , , , , ))
// :: INFO cluster.YarnScheduler: Adding task set 0.0 with tasks
// :: INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID , slave2, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID , slave3, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on slave3: (size: 1172.0 B, free: 366.3 MB)
// :: INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on slave2: (size: 1172.0 B, free: 366.3 MB)
// :: INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID , slave3, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID ) in ms on slave3 (executor ) (/)
// :: INFO scheduler.TaskSetManager: Starting task 3.0 in stage 0.0 (TID , slave3, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID ) in ms on slave3 (executor ) (/)
// :: INFO scheduler.TaskSetManager: Starting task 4.0 in stage 0.0 (TID , slave3, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO scheduler.TaskSetManager: Finished task 3.0 in stage 0.0 (TID ) in ms on slave3 (executor ) (/)
// :: INFO scheduler.TaskSetManager: Starting task 5.0 in stage 0.0 (TID , slave3, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO scheduler.TaskSetManager: Finished task 4.0 in stage 0.0 (TID ) in ms on slave3 (executor ) (/)
// :: INFO scheduler.TaskSetManager: Starting task 6.0 in stage 0.0 (TID , slave2, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID ) in ms on slave2 (executor ) (/)
// :: INFO scheduler.TaskSetManager: Starting task 7.0 in stage 0.0 (TID , slave3, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO scheduler.TaskSetManager: Finished task 5.0 in stage 0.0 (TID ) in ms on slave3 (executor ) (/)
// :: INFO scheduler.TaskSetManager: Starting task 8.0 in stage 0.0 (TID , slave2, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO scheduler.TaskSetManager: Finished task 6.0 in stage 0.0 (TID ) in ms on slave2 (executor ) (/)
// :: INFO scheduler.TaskSetManager: Starting task 9.0 in stage 0.0 (TID , slave2, executor , partition , PROCESS_LOCAL, bytes)
// :: INFO scheduler.TaskSetManager: Finished task 7.0 in stage 0.0 (TID ) in ms on slave3 (executor ) (/)
// :: INFO scheduler.TaskSetManager: Finished task 8.0 in stage 0.0 (TID ) in ms on slave2 (executor ) (/)
// :: INFO scheduler.TaskSetManager: Finished task 9.0 in stage 0.0 (TID ) in ms on slave2 (executor ) (/)
// :: INFO cluster.YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
// :: INFO scheduler.DAGScheduler: ResultStage (reduce at SparkPi.scala:) finished in 0.857 s
// :: INFO scheduler.DAGScheduler: Job finished: reduce at SparkPi.scala:, took 1.104223 s
Pi is roughly 3.143763143763144
// :: INFO server.AbstractConnector: Stopped Spark@596df867{HTTP/1.1,[http/1.1]}{0.0.0.0:}
// :: INFO ui.SparkUI: Stopped Spark web UI at http://192.168.0.120:4040
// :: INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
// :: INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
// :: INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
// :: INFO cluster.SchedulerExtensionServices: Stopping SchedulerExtensionServices
(serviceOption=None,
services=List(),
started=false)
// :: INFO cluster.YarnClientSchedulerBackend: Stopped
// :: INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
// :: INFO memory.MemoryStore: MemoryStore cleared
// :: INFO storage.BlockManager: BlockManager stopped
// :: INFO storage.BlockManagerMaster: BlockManagerMaster stopped
// :: INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
// :: INFO spark.SparkContext: Successfully stopped SparkContext
// :: INFO util.ShutdownHookManager: Shutdown hook called
// :: INFO util.ShutdownHookManager: Deleting directory /opt/spark-2.2.-bin-hadoop2./spark-c4987503--4e4c-b170-301856a36773
通过yarn resource manager界面查看任务运行状态:

参考《https://blog.csdn.net/rongyongfeikai2/article/details/69361333》
《https://blog.csdn.net/chengyuqiang/article/details/77864246》
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(六)针对spark2.2.1以yarn方式启动spark-shell抛出异常:ERROR cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Sending RequestExecutors(0,0,Map(),Set()) to AM was unsuccessful的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十一)定制一个arvo格式文件发送到kafka的topic,通过Structured Streaming读取kafka的数据
将arvo格式数据发送到kafka的topic 第一步:定制avro schema: { "type": "record", "name": ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- FireDAC 下的 Sqlite [5] - 数据的插入、更新、删除
先在空白窗体上添加: TFDConnection.TFDPhysSQLiteDriverLink.TFDGUIxWaitCursor.TFDQuery.TDataSource.TDBGrid(并在设计 ...
- PHP上传文件大小限制的问题(转)
在用PHP进行文件上传的操作中,需要知道怎么控制上传文件大小的设置,而文件可传大小是受到多种因素制约的,现总结如下:1.php.ini:upload_max_filesize 所上传的文件的最大大 ...
- getRequestURI,getRequestURL的区别(转)
test1.jsp======================= <a href ="test.jsp?p=fuck">跳转到test2</a> test2 ...
- android应用程序签名(转)
概述 Android系统要求,所有的程序经过数字签名后才能安装.Android系统使用这个证书来识别应用程序的作者,并且建立程序间的信任关系.证书不是用于用户控制哪些程序可以安装.证书不需要授权中心来 ...
- Android论坛
APKBUS:http://www.apkbus.com/forum.php 看雪ANDROID:http://bbs.pediy.com http://www.52pojie.cn http://w ...
- iOS 去掉UITableView风格为group时候的最顶部的空白距离
CGRect frame=CGRectMake(0, 0, 0, CGFLOAT_MIN); self.tableView.tableHeaderView=[[UIView alloc]initW ...
- Linux学习14-ab报错apr_pollset_poll: The timeout specified has expired (70007)
前言 使用ab压力测试时候出现报错apr_pollset_poll: The timeout specified has expired (70007),本篇总结了几个ab常见的报错和对应解决办法 当 ...
- 【Samza系列】实时计算Samza中文教程(一)背景
大家应该听我在前言篇里扯皮后,迫不及待要来一看Samza到底是何物了吧?先了解一下Samza的Background是不可缺少的(至少官网上是放在第一个的),我们须要从哪些技术背景去了解呢? ...
- Java 如何实现在线预览文档及修改(Office文件)
测试地址: https://sms.idxkj.cn 用户名:aa 密码:123456
- Wireshark基本用法 && 过滤规则 && 协议详解
基本使用: https://www.cnblogs.com/dragonir/p/6219541.html 协议解析: https://www.jianshu.com/p/a384b8e32b67 ( ...