tensorflow学习笔记——图像数据处理
喜欢摄影的盆友都知道图像的亮度,对比度等属性对图像的影响是非常大的,相同物体在不同亮度,对比度下差别非常大。然而在很多图像识别问题中,这些因素都不应该影响最后的结果。所以本文将学习如何对图像数据进行预处理使训练得到的神经网络模型尽可能小地被无关因素所影响。但与此同时,复杂的预处理过程可能导致训练效率的下降。为了减少预处理对于训练速度的影响,后面也学习多线程处理输入数据的解决方案。
在大部分图像识别问题中,通过图像预处理过程可以提高模型的准确率。为了获取更多的数据,我们只需要对现有数据集进行微小改动,轻微改动,例如翻转或翻译或轮换。无论如何,我们的神经网络会认为这些是不同的图像。卷积神经网络CNN对放置在不同方向的对象,也能进行稳健的分类,即具有不变性的属性。更具体的,CNN对平移,不同视角,尺寸大小或光照等可以是不变的。这基本上是数据增加的前提。
下图是图像增强的一张表,盗图,侵删(https://blog.csdn.net/Eastmount/article/details/82216380)
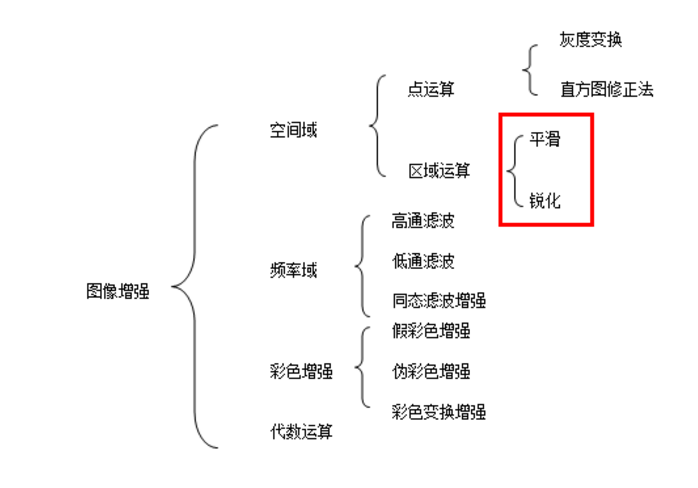
在实际场景中,我们可能会有一组有限的条件下获取图像数据集。但是我们的目标应用可能存在于各种条件下,例如不同的方向,位置,比例,亮度等。我们通过使用额外的合成对数据进行修改,并训练我们的神经网络来解释这些情况。下面我们学习一些常用而且基本功能强大的增强技术。当然在TensorFlow中提供了几类图像处理函数,下面一一学习。
1,图像编码处理
我们知道一张RGB色彩模式的图像可以看成一个三维矩阵,矩阵中的每个数表示了图像上不同位置,不同颜色的亮度。然而图像在存储时并不是直接记录这些矩阵中的数字,而是记录经过压缩编码之后的结果。所以要将一张图像还原成一个三维矩阵,需要解码的过程。TensorFlow提供了对JPEG和png格式图像的编码/解码函数。以下代码示范了如何使用TensorFlow中对 JPEG 格式图像的编码/解码函数。
#_*_coding:utf-8_*_
# matplotlib.pyplot 是一个python 的画图工具。下面用这个来可视化
import matplotlib.pyplot as plt
import tensorflow as tf # 读取图像的原始数据
picture_path = 'kd.jpg'
image_raw_data = tf.gfile.FastGFile(picture_path, 'rb').read() with tf.Session() as sess:
# 将图像使用JPEG的格式解码从而得到图像对应的三维矩阵
# TensorFlow提供了 tf.image.decode_png 函数对png格式的图像进行解码
# 解码之后的结果为一个张量,在使用它的取值之前需要明确调用运行的过程
img_data = tf.image.decode_jpeg(image_raw_data) # 输出解码之后的三维矩阵
# print(img_data.eval())
'''
# 输出解码之后的三维矩阵如下:
[[[4 6 5]
[4 6 5]
[4 6 5]
...
[35 29 31]
[26 20 24]
[25 20 26]]]
''' # 使用 pyplot工具可视化得到的图像
plt.imshow(img_data.eval())
plt.show() # 将数据的类型转化成实数方便下面的样例程序对图像进行处理
# img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32) # 将表示一张图像的三维矩阵重新按照JPEG格式编码并存入文件中
# 打开这种图片可以得到和原始图像一样的图像
encoded_image = tf.image.encode_jpeg(img_data)
with tf.gfile.GFile('output.jpg', 'wb') as f:
f.write(encoded_image.eval())
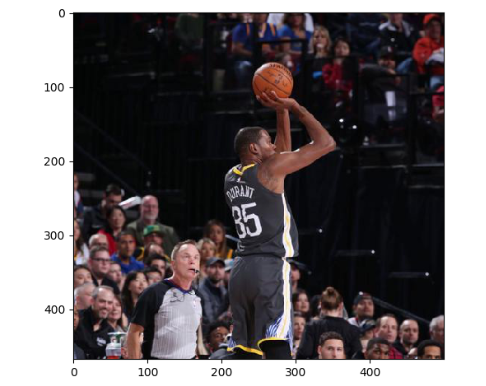
下图显示了上面代码可视化出来的一张图像:
2,图像大小调整
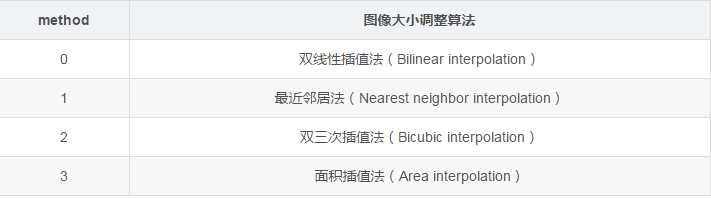
一般来说,网络上获取的图像大小是不固定的,但神经网络输入节点的个数是固定的。所以在将图像的像素作为输入提供给神经网络之前,需要先将图像的大小统一。这就是图像大小调整需要完成的任务。图像大小调整有两种方式,第一种是通过算法使得新的图像尽量保存原始图像上的所有信息。TensorFlow提供了四种不同的方法,并且将他们封装到了 tf.image.resize_images 函数,下面代码示范了如何使用这个函数。
# 加载原始图像
# 读取图像的原始数据,然后解码
picture_path = 'kd.jpg'
image_raw_data = tf.gfile.FastGFile(picture_path, 'rb').read() with tf.Session() as sess:
# 将图像使用JPEG的格式解码从而得到图像对应的三维矩阵
# TensorFlow提供了 tf.image.decode_png 函数对png格式的图像进行解码
# 解码之后的结果为一个张量,在使用它的取值之前需要明确调用运行的过程
img_data = tf.image.decode_jpeg(image_raw_data) # 通过tf.image.resize_images函数调整图像的大小
# 这个函数第一个参数为原始图像,第二个和第三个参数为调整后图像的大小
# method 参数给出了调整图像大小的算法
resized = tf.image.resize_images(img_data, 300, 300, method=0) # 输出调整后图像的大小,此处的结果为(300, 300, ?)表示图像的大小为300*300
# 但是在图像的深度还没有明确设置之前会是问号
print(img_data.get_shape)
下图给出了 tf.image.resize_images 函数的 method 参数取值对应的图像大小调整算法
实例代码如下:
#_*_coding:utf-8_*_
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np # 读取图像的原始数据
picture_path = 'kd.jpg'
image_raw_data = tf.gfile.FastGFile(picture_path, 'rb').read() with tf.Session() as sess:
# 将图像使用JPEG的格式解码从而得到图像对应的三维矩阵
# TensorFlow提供了 tf.image.decode_png 函数对png格式的图像进行解码
# 解码之后的结果为一个张量,在使用它的取值之前需要明确调用运行的过程
img_data = tf.image.decode_jpeg(image_raw_data) img_data.set_shape([300, 300, 3])
print(img_data.get_shape()) # (300, 300, 3) # 重新调整图片的大小
resized = tf.image.resize_images(img_data, [260, 260], method=0) # TensorFlow的函数处理图片后存储的数据是float32格式的,
# 需要转换成uint8才能正确打印图片。
resized_photo = np.asarray(resized.eval(), dtype='uint8')
# tf.image.convert_image_dtype(rgb_image, tf.float32)
plt.imshow(resized_photo)
plt.show()
结果如下:
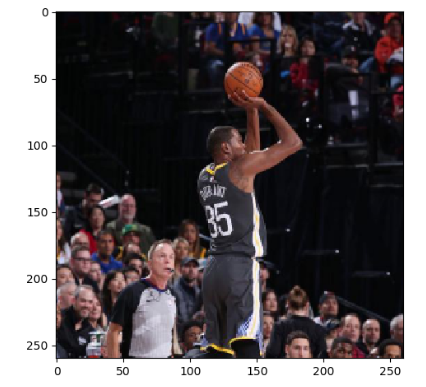
当然,我们也可以进行双三插值法,面积插值法,最近邻插值法进行处理。不同算法调整处理的结果会有细微差别,但不会相差太远。
3,裁剪和填充
除了把整张图像信息完整保存,TensorFlow还提供了API对图像进行裁剪或者填充。TensorFlow提供了 tf.image.crop_to_bounding_box 函数 和 tf.image.pad_to_bounding_box 函数来剪裁或者填充给定区域的图像。这两个函数都要求给出的尺寸满足一定的要求,否则程序会报错。比如在使用 tf.image.crop_to_bounding_box 函数时候,TensorFlow要求提供的图像尺寸要大于目标尺寸,也就是要求原始图像能够裁剪出目标图像的大小。下面代码展示了通过 tf.image_resize_image_with_crop_or_pad 函数来调整图像大小的功能。
# 通过 tf.image_resize_image_with_crop_or_pad 函数调整图像的大小
# 这个函数的第一个参数为原始图像,后面两个参数是调整后的模板图像大小
# 如果原始图像的尺寸大于目标图像,那么这个函数会自动截取图像原始图像中矩阵的部分
# 如果目标图像大于原始图像,这个函数会自动在原始图像的四周填充全0的背景
# 因为我这个图片是500*468,所以第一个命令自动裁剪,第二个命名自动填充
croped = tf.image.resize_image_with_crop_or_pad(img_data, 300, 300)
padded = tf.image.resize_image_with_crop_or_pad(img_data, 600, 600)
下面示例看一下图片:
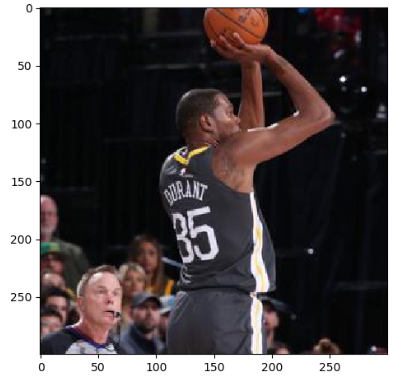
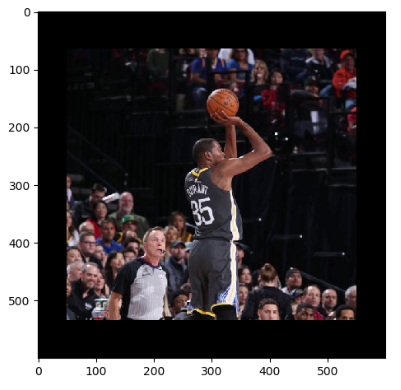
4,截取中间50%的图片
TensorFlow还支持通过比例调整图像大小,函数如下:
# 通过 tf.image.central_crop() 函数可以按比例裁剪图像
# 函数第一个参数为原始图像,第二个为调整比例 这个比例是需要在(0, 1] 的实数
# 下面意思是截取中间百分之五十
central_cropped = tf.image.central_crop(img_data, 0.5)
截取中间50%的结果展示如下:

5,翻转图片
TensorFlow提供了一些函数来支持对图像的翻转,下面代码实现了将图像上下反转,左右反转,以及沿对角线翻转的功能。
# 上下翻转
flipped1 = tf.image.flip_up_down(img_data)
plt.imshow(flipped1.eval())
plt.show() # 左右翻转
flipped2 = tf.image.flip_left_right(img_data)
plt.imshow(flipped2.eval())
plt.show() #对角线翻转
transposed = tf.image.transpose_image(img_data)
plt.imshow(transposed.eval())
plt.show() # 以一定概率上下翻转图片。
#flipped = tf.image.random_flip_up_down(img_data)
# 以一定概率左右翻转图片。
#flipped = tf.image.random_flip_left_right(img_data)
结果展示如下:



在很多图像识别问题中,图像的翻转不会影响识别的结果。于是在训练图像识别的神经网络模型时,可以随机地翻转训练图像。这样训练得到的模型可以识别不同角度的实体。比如假设在训练数据中所有的猫头都是向右的,那么训练出来的模型就无法很好的识别猫头向左向右的猫。虽然这个问题可以通过收集更多的训练数据来解决,但是通过随机翻转训练图像的方式可以在零成本的情况下很大的缓解该问题。所以随机翻转训练图像是一种很常见的图像预处理方式。
6,图像色彩调整
和图像翻转类似,调整图像的亮度,对比度,饱和度和色相在很多图像识别应用中都不会影响识别结果。所以在训练神经网络模型时,可以随机调整训练图像的这些属性,从而使得训练得到的模型尽可能小的受到无关因素的影响。Tensorflow提供了调整这些色彩相关属性的API,以下代码显示了如何修改图像的亮度:
# 将图片的亮度-0.5。
#adjusted = tf.image.adjust_brightness(img_data, -0.5) # 将图片的亮度-0.5
#adjusted = tf.image.adjust_brightness(img_data, 0.5) # 在[-max_delta, max_delta)的范围随机调整图片的亮度。
adjusted = tf.image.random_brightness(img_data, max_delta=0.5) # 将图片的对比度-5
#adjusted = tf.image.adjust_contrast(img_data, -5) # 将图片的对比度+5
#adjusted = tf.image.adjust_contrast(img_data, 5) # 在[lower, upper]的范围随机调整图的对比度。
#adjusted = tf.image.random_contrast(img_data, lower, upper) plt.imshow(adjusted.eval())
plt.show()
结果展示如下:
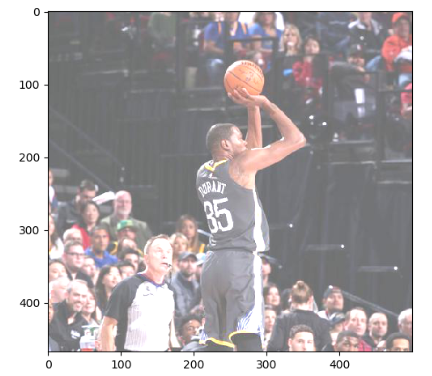
7,图像色相调整
下面代码显示了如何调整图像的色相:
# 下面四条命令分别将色相加0.1 0.3 0.6 0.9
adjusted = tf.image.adjust_hue(img_data, 0.1)
#adjusted = tf.image.adjust_hue(img_data, 0.3)
#adjusted = tf.image.adjust_hue(img_data, 0.6)
#adjusted = tf.image.adjust_hue(img_data, 0.9) # 在[-max_delta, max_delta]的范围随机调整图片的色相。max_delta的取值在[0, 0.5]之间。
#adjusted = tf.image.random_hue(image, max_delta) # 将图片的饱和度-5。
#adjusted = tf.image.adjust_saturation(img_data, -5)
# 将图片的饱和度+5。
#adjusted = tf.image.adjust_saturation(img_data, 5)
# 在[lower, upper]的范围随机调整图的饱和度。
#adjusted = tf.image.random_saturation(img_data, lower, upper) # 将代表一张图片的三维矩阵中的数字均值变为0,方差变为1。
#adjusted = tf.image.per_image_whitening(img_data) plt.imshow(adjusted.eval())
plt.show()
结果展示一个调整色相0.1的图片:
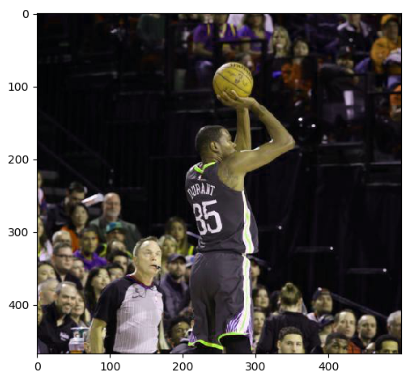
8,图像标准化
图像标准化的过程,其实就是将图像上的亮度均值变为0, 方差变为1,下面代码实现了这个功能:
# 图像标准化
# 将代表一张图像的三维矩阵中的数字均值变为0, 方差变为1
adjusted = tf.image.per_image_standardization(img_data)
plt.imshow(adjusted.eval())
plt.show()
结果如下:
9,处理标注框
在很多图像识别的数据集中,图像中需要关注的物体通常会被标注圈出来,TensorFlow提供了一些工具来处理标注框。下面代码展示了如何通过tf.image.draw_bounding_boxes函数在图像中加入标注框。
# 将图像缩小一些,这样可视化能让标注框更加清楚
img_data = tf.image.resize_images(img_data, 180, 267, method=1)
# tf.image.draw_bounding_boxes 函数要求图像矩阵中的数字为实数
# 所以需要先将图像矩阵转化为实数类型,次函数输入的是一个batch的数据
#也就是多张图像组成的四维矩阵,所以需要将解码之后的图像矩阵加一维
batched = tf.expand_dims(tf.image.convert_image_dtype(img_data,
tf.float32), 0)
# 给出每一张图像的所有标注框,一个标注框有四个数字,分别代表[ymin, xmin, ymax, xmax]
# 注意这里给出的数字都是图像的相对位置,比如在180*267的图像中
# [0.35, 0.47, 0.5, 0.56] 代表了从(63, 125) 到 (90, 150)的图像
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]])
result = tf.image.draw_bounding_boxes(batched, boxes)
plt.imshow(result.eval())
plt.show()
和随机翻转图像,随机调整颜色类似,随机截取图像上有信息含量的部分也是一个提高模型健壮性(robustness)的一种方式。这样可以使训练得到的模型不受被识别物体大小的影响。下面程式展示了如何通过 tf.image.sample_distorted_bounding_box 函数来完成随机截取图像的过程。
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]]) # 可以通过提供标注框的方式来告诉随机截取图像的算法那些部分是有信息量的
begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box(
tf.shape(img_data), bounding_boxes=boxes) # 通过标注框可视化随机截取得到的图像
batched = tf.expand_dims(
tf.image.convert_image_dtype(img_data, tf.float32), 0)
image_with_box = tf.image.draw_bounding_boxes(batched, bbox_for_draw) # 截取随机出来的图像,因为算法带有随机成分,所以每次得到的结果会有所不同
distorted_image = tf.slice(img_data, begin, size)
plt.imshow(distorted_image.eval())
plt.show()
结果如下:
10,Rotation
关于此操作需要注意的一件事是旋转后图像尺寸可能无法保留。如果你的图像是正方形,则以直角旋转它将保留图像大小,如果他是一个矩阵,旋转180度将保持大小,以更精细的角度旋转图像也会改变最终的图像尺寸。
你可以使用你喜欢的包中的任何以下命令执行旋转。数据增强因子 = 2到4倍。
# Placeholders: 'x' = A single image, 'y' = A batch of images
# 'k' denotes the number of 90 degree anticlockwise rotations
shape = [height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = shape)
rot_90 = tf.image.rot90(img, k=1)
rot_180 = tf.image.rot90(img, k=2)
# To rotate in any angle. In the example below, 'angles' is in radians
shape = [batch, height, width, 3]
y = tf.placeholder(dtype = tf.float32, shape = shape)
rot_tf_180 = tf.contrib.image.rotate(y, angles=3.1415)
# Scikit-Image. 'angle' = Degrees. 'img' = Input Image
# For details about 'mode', checkout the interpolation section below.
rot = skimage.transform.rotate(img, angle=45, mode='reflect')
11,Gaussion Noise
当你的神经网络试图学习可能无用的高频特征(大量出现的模式)时,通常会出现过度拟合。具有零均值的高斯噪声基本上在所有频率中具有数据点,从而有效地扭曲高频特征。这也意味着较低频率的组件(通常是我们的与其数据)也会失真,但您的神经网络可以学会超越他。添加适量的噪音可以增强学习能力。一个色调较低的版本是盐和胡椒噪音,它表现为随机的黑白像素在图像中传播。这类似于通过向图像添加高斯噪声而产生的效果,但可能具有较低的信息失真水平。
你可以在TensorFlow上使用以下命令为图像添加高斯噪声。数据增强因子 = 2X
#TensorFlow. 'x' = A placeholder for an image.
shape = [height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = shape)
# Adding Gaussian noise
noise = tf.random_normal(shape=tf.shape(x), mean=0.0, stddev=1.0,
dtype=tf.float32)
output = tf.add(x, noise)
12,图像预处理完整样例
上面学习了TensorFlow提供的主要图像处理函数,在解决真实的图像识别问题时,一般会同时使用多种处理方法,下面学习一个完整的样例程序展示如何将不同的图像处理函数结合成一个完整的图像预处理流程。以下TensorFlow程序完成了从图像片段截取,到图像大小调整再到图像翻转及色彩调整的整个图像预处理过程。
#_*_coding:utf-8_*_
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt def distort_color(image, color_ordering=0):
'''
随机调整图片的色彩,定义两种顺序
下面将给定一张图像,随机调整图像的色彩,因为点赞亮度,对比度,饱和度和色相的
顺序将会影响最后得到的结果,所以可以定义多种不同的顺序,具体使用哪一种顺序可以
在训练数据预处理时随机的选择一种,这样可以进一步降低无关元素对模型的影响
:param image:
:param color_ordering:
:return:
'''
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32./255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
else:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32./255.)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
#还可以elif 去设置其他的排列,但是这里就不再一一列出了。 return tf.clip_by_value(image, 0.0, 1.0) def preprocess_for_train(image, height, width, bbox):
'''
对图片进行预处理,将图片转化成神经网络的输入层数据
给定一张解码后的图像,目标图像的尺寸以及图像上的标注框
次函数可以对给出的额图像进行预处理,这个函数的输入图像是图像识别问题中
原始的训练图像,而输出则是神经网络模型的输入层,注意这里只处理模型的训练数据
# 对于预测的数据,一般不需要使用随机变换的步骤
:param image:
:param height:
:param width:
:param bbox:
:return:
'''
# 查看是否存在标注框。如果没有提供标注框,则认为整个图像就是需要关注的部分
if bbox is None:
bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32, shape=[1, 1, 4])
# 转换图像张量的类型
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32) # 随机的截取图片中一个块。减少需要关注的物体大小对图像识别算法ade影响
bbox_begin, bbox_size, _ = tf.image.sample_distorted_bounding_box(
tf.shape(image), bounding_boxes=bbox)
bbox_begin, bbox_size, _ = tf.image.sample_distorted_bounding_box(
tf.shape(image), bounding_boxes=bbox)
distorted_image = tf.slice(image, bbox_begin, bbox_size) # 将随机截取的图片调整为神经网络输入层的大小。大小调整的算法是随机选择的
distorted_image = tf.image.resize_images(distorted_image, [height, width], method=np.random.randint(4))
# 随机左右反转图像
distorted_image = tf.image.random_flip_left_right(distorted_image)
# 使用一种随机的顺序调整图像色彩
distorted_image = distort_color(distorted_image, np.random.randint(2))
return distorted_image # 读取图像
image_raw_data = tf.gfile.FastGFile("kd.jpg", "rb").read()
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data)
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]])
for i in range(9):
result = preprocess_for_train(img_data, 299, 299, boxes)
plt.imshow(result.eval())
plt.show()
运行上面的diam,可以得到下图9张不同的图像,因为运行6次图像预处理。这样就可以通过一张训练图像衍生出很多训练样本,通过将训练图像进行预处理,训练得到的神经网络模型可以识别不同大小,方位,色彩等方面的实例。
原图如下:
处理之后的图片如下:
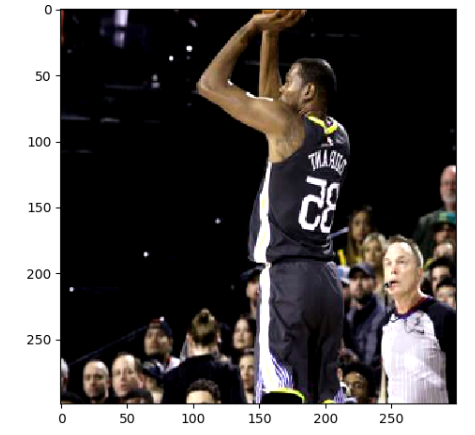



13,python glob.glob的使用
函数功能:匹配所有的符合条件的问卷,并将其以 list的形式返回
示例,当前文件夹中有如下文件:

import glob list = glob.glob(‘*g’)
print(list)
结果如下:
['dog.1012.jpg', 'dog.1013.jpg', 'dog.1014.jpg', 'dog.1015.jpg', 'dog.1016.jpg']
14,tensorflow tf.gfile的使用
tf.gfile()函数和python中os模块非常的相似,一般都可以使用os模块代替。
此函数的作用是读写文件,句柄具有 .read() 方法
'''
本代码也是加载图pb文件并获取节点张量句柄的标准流程,
feed_dict输入节点 & sess.run(输出节点)就可以使用模型了
'''
# 使用tf.gfile.FastGFile()函数的方法
# with tf.gfile.FastGFile(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f:
with open(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f: # 使用open()函数的方法
graph_def = tf.GraphDef() # 生成图
graph_def.ParseFromString(f.read()) # 图加载模型
# 从图上读取张量,同时把图设为默认图
bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def(
graph_def,
return_elements=[BOTTLENECK_TENSOR_NAME, JPEG_DATA_TENSOR_NAME]) print(gfile.FastGFile(image_path, 'rb').read() == open(image_path, 'rb').read())
# True
15,python np.squeeze()的使用
函数的作用:从数组的形状中删除单维条目,即把shape 中为1 的维度去掉。
#_*_coding:utf-8_*_
import numpy as np a = np.array([[1], [2], [3]])
print(a)
print(a.shape)
'''
输出结果如下:
[[1]
[2]
[3]]
(3, 1)
'''
# 应用squeeze() 后
a1 = np.squeeze(a)
print(a1)
print(a1.shape)
'''
输出结果如下:
[1 2 3]
(3,)
'''
应用:在预测分析中用于处理预测数组和真实数组以方便计算预测值和真实值之间的误差。
predictions = np.array(predictions).squeeze() labels = np.array(labels).squeeze() rmse = np.sqrt(((predictions - labels) ** 2).mean(axis=O))
16,tf.global_variables_initializer() 函数与tf.local_variables_initializer() 函数的区别
当我们训练自己的神经网络的时候,无一例外的就是都会加上一句sess.run(tf.global_variables_initializer() ),这行代码的官方解释是 初始化模型的参数。
tf.global_variables_initializer() 添加节点用于初始化全局的变量(GraphKeys.VARIABLES)。返回一个初始化所有全局变量的操作(Op)。在我们构建完整个模型并在会话中加载模型后运行这个节点,能够将所有的变量一步到位的初始化,非常的方便。通过 feed_dict,我们也可以将指定的列表传递给它,只初始化列表中的变量。
示例代码如下:
sess.run(tf.global_variables_initializer(),
feed_dict={x: val_x,
y: val_y,
keep_prob: 1.0}
tf.local_variables_initializer() 添加节点用于初始化局部的变量(GraphKeys.LOCAL_VARIABLE), 返回一个初始化所有局部变量的操作(Op)。GraphKeys.LOCAL_VARIABLE 中的变量指的是被添加如图中,但是未被存储的变量。示例代码与上面的类似。
注意:在使用局部变量时必须使用 tf.local_variables_initializer() 初始化器,在使用全局变量时必须使用 tf.global_variables_initializer() 初始化器,不然会报错,报错代码类似下面:
tensorflow.python.framework.errors_impl.FailedPreconditionError:
Attempting to use uninitialized value matching_filenames [[Node:
_retval_matching_filenames_0_0 = _Retval[T=DT_STRING, index=0,
_device="/job:localhost/replica:0/task:0/cpu:0"](matching_filenames)]]
此文是自己的学习笔记总结,学习于《TensorFlow深度学习框架》,俗话说,好记性不如烂笔头,写写总是好的,所以若侵权,请联系我,谢谢。
tensorflow学习笔记——图像数据处理的更多相关文章
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
- 深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版 这是tf入门的第一个例子.minst应该是内置的数据集. 前置知识在学习笔记(1)里面讲过了 这里直接上代码 # -*- ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
- tensorflow学习笔记——VGGNet
2014年,牛津大学计算机视觉组(Visual Geometry Group)和 Google DeepMind 公司的研究员一起研发了新的深度卷积神经网络:VGGNet ,并取得了ILSVRC201 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记——使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
- TensorFlow学习笔记10-卷积网络
卷积网络 卷积神经网络(Convolutional Neural Network,CNN)专门处理具有类似网格结构的数据的神经网络.如: 时间序列数据(在时间轴上有规律地采样形成的一维网格): 图像数 ...
- Tensorflow学习笔记No.5
tf.data卷积神经网络综合应用实例 使用tf.data建立自己的数据集,并使用CNN卷积神经网络实现对卫星图像的二分类问题. 数据下载链接:https://pan.baidu.com/s/141z ...
随机推荐
- 包教包会之Open Live Writer设置代码样式
Open Live Writer(以下简称OLW),作为一个在本地写博文,然后发布到各个博客网站的客户端,在使用上个人觉得还是比较好用的.但是其对IT博文中代码部分的内容样式支持不是很友好.下面是本人 ...
- 手动启动log4j|nginx实现http https共存
手动加载log4j.xml文件 DOMConfigurator.configure("src/main/resources/log4j.xml"); log4j.propertie ...
- 和朱晔一起复习Java并发(二):队列
和朱晔一起复习Java并发(二):队列 老样子,我们还是从一些例子开始慢慢熟悉各种并发队列.以看小说看故事的心态来学习不会显得那么枯燥而且更容易记忆深刻. 阻塞队列的等待? 阻塞队列最适合做的事情就是 ...
- 20141209-基本概念-BlogEngine.NET(1)-笔记
最近在读BlogEngine.NET3.1源代码,希望能坚持到底吧. 刚接触源代码,没有思路,于是读了14篇关于BlogEngine.Net1.4.5的系列博客,地址:http://www.cnblo ...
- Java用Xom生成XML文档
这个总结源于Java编程思想第四版18.13节的案例: 完整代码地址: Java编程思想:XML 相关Api地址: Attribute Element Document Serializer 由于案例 ...
- Java用Zip进行压缩
这个总结源于Java编程思想第四版18.11节的案例: 完整代码地址: Java编程思想:压缩 相关Api地址: ZipStream ZipEntry ZipFile 进行压缩时: 1.创建Check ...
- Excel催化剂开源第34波-SM.MS图床API调用(用POST上传multipart/form-data内容)
日常做网抓数据,都是以GET请求为主,偶尔遇到需要POST请求的,一般POST的参数只是一串字符串就可以了,通过构造字符串也很容易完成,但此次SM.MS的API接口要求是Content-Type: m ...
- 基于 Github 存储附件的 wordpress 插件
前言 插件名称 wp-github-gos, 本插件核心功能使用了 GitHub API 设置页面和核心业务逻辑主要参考插件 wordpress-qcloud-cos 的实现,替换了其中 腾讯云 CO ...
- 【halcon教程资料】全网汇总如何快速、高效率学习机器视觉从入门到精通
我以八年的视觉工程师开发的工作经验告诉你,你不要再因为学习halcon发愁了,我接触过很多学习halcon的小白,并不是不愿意学,而是不知道怎么快速.高效率的学习精通,一天天的过去了,对学习halco ...
- K8S 部署 Web UI
在早期的版本中 Kubernetes可以在 Dashboard 中看到 heapster 提供的一些图表信息, 在后续的版本中会陆续移除掉 heapster,现在更加流行的监控工具是 promethe ...