8 NLP-自然语言处理Demo
1 NLP(自然语言处理)
1.1相似度
相似度和距离之间关系:
- 1、文本相似度:
- 1) 语义相似、但字面不相似:
- 老王的个人简介
- 铁王人物介绍
- 2) 字面相似、但是语义不相似:
- 我吃饱饭了
- 我吃不饱饭
- 2、方案:
- 1) 语义相似:依靠用户行为,最基本的方法:(1)基于共点击的行为(协同过滤),(2)借助回归算法
- 歌神 -> 张学友
- 2) 字面相似:(1) LCS最大公共子序列 (2) 利用中文分词
- 老王的个人简介 => 老王 / 的 / 个人 / 简介
- token
- 3 字面相似的问题解决:
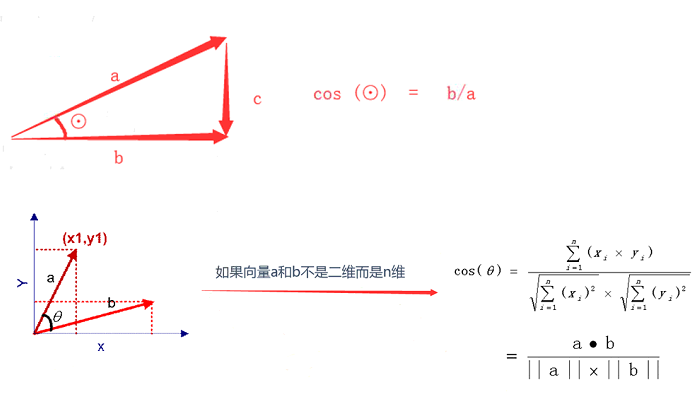
- 余弦相似度 cosine
- 举例:A(1,2,3) B(2,3,4)
- cosine(A,B) = 分子 / 分母 - 分子:A * B = 1 * 2+2 *
3+3 * 4 = 20
- 分母:|A| * |B| = 20.12
- |A| = sqrt(1 * 1+2 * 2+3 * 3) = 3.74 - |B| = sqrt(2 * 2+3
* 3+4 * 4) = 5.38
1.2 常用方法
• 相似度度量:计算个体间相似程度
• 相似度值越小,距离越大,相似度值越大,距离越小
• 最常用——余弦相似度
- 一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小
- 余弦值接近1,夹角趋于0,表明两个向量越相似

得到了文本相似度计算的处理流程是:
– 找出两篇文章的关键词; – 每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频 – 生成两篇文章各自的词频向量; – 计算两个向量的余弦相似度,值越大就表示越相似
1.3 关键词
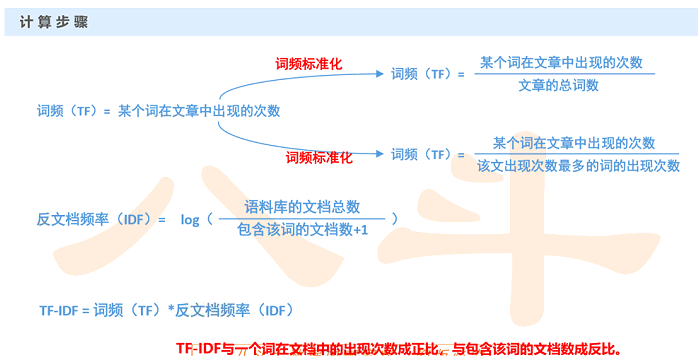
TF/IDF
- 1) TF:词频
- 假设:如果一个词很重要,应该会在文章中多次出现
- 词频——TF(Term Frequency):一个词在文章中出现的次数
- 也不是绝对的!出现次数最多的是“的”“是”“在”,这类最常用的词, 叫做停用词(stop words)
- 停用词对结果毫无帮助,必须过滤掉的词
- 过滤掉停用词后就一定能接近问题么?
- 进一步调整假设:如果某个词比较少见,但是它在这篇文章中多次出现,那 么它很可能反映了这篇文章的特性,正是我们所需要的关键词
- 2) IDF:反文档频率
- 在词频的基础上,赋予每一个词的权重,进一步体现该词的重要性,
- 最常见的词(“的”、“是”、“在”)给予最小的权重
- 较常见的词(“国内”、“中国”、“报道”)给予较小的权重
- 较少见的词(“养殖”、“维基”、“涨停”)给予较小的权重
(关键词:在当前文章出现较多,但在其他文章中出现较少)
(将TF和IDF进行相乘,就得到了一个词的TF-IDF值,某个词对文章重要性越高,该值越大, 于是排在前面的几个词,就是这篇文章的关键词。)
1.4 关键词方法 : 自动摘要
- 1) 确定关键词集合(两种方法(a)top-10 (b)阈值截断 > 0.8 ) (阈值截断针对TFIDF的值进行截断取值操作)
- 2)哪些句子包含关键词,把这些句子取出来
- 3) 对关键词排序,对句子做等级划分
- 4)把等级高的句子取出来,就是摘要
1.5 NLP总结
• 优点:简单快速,结果比较符合实际情况
• 缺点:单纯以“词频”做衡量标准,不够全面,有时重要的词可能出现的次数并不多
这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
1.6 TFIDF实践实践:

这个下面放了508篇文章
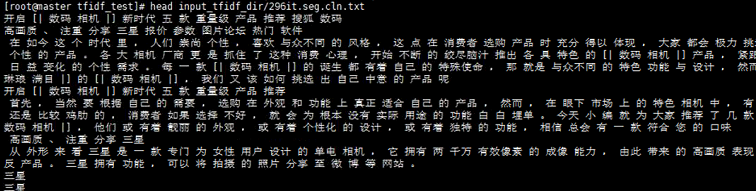
发现这些文章已经进行分词(已空格分隔)
如果每篇文章都打开那么会非常的慢,所以需要对文章进行预处理
(1)数据预处理:把所有文章的内容,全部收集到一个文件中
convert.py
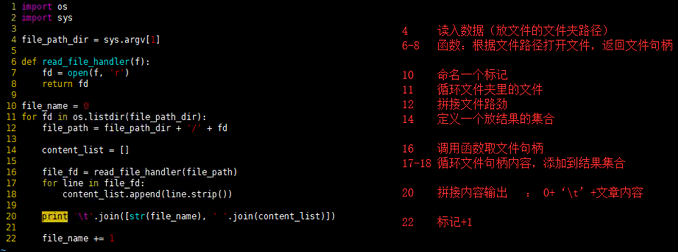
import os
import sys
file_path_dir = sys.argv[1]
def read_file_handler(f):
fd = open(f, 'r')
return fd
file_name = 0
for fd in os.listdir(file_path_dir):
file_path = file_path_dir + '/' + fd
content_list = []
file_fd = read_file_handler(file_path)
for line in file_fd:
content_list.append(line.strip())
print '\t'.join([str(file_name), ' '.join(content_list)])
file_name += 1

python convert.py input_tfidf_dir/ > idf_input.data

一共508行 有数字标记
(2)计算IDF:通过MapReduce批量计算IDF
map.py
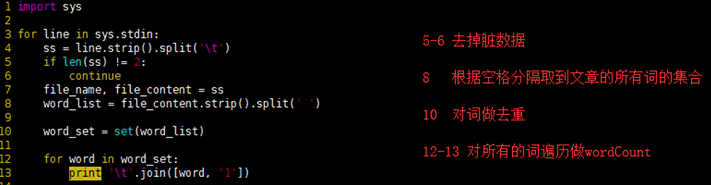
import sys
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
file_name, file_content = ss
word_list = file_content.strip().split(' ')
word_set = set(word_list)
for word in word_set:
print '\t'.join([word, ''])
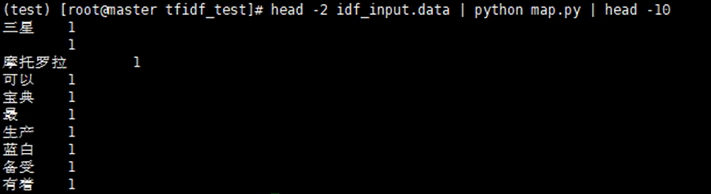
head -2 idf_input.data | python map.py | head -10
测试没有问题继续reduce
red.py
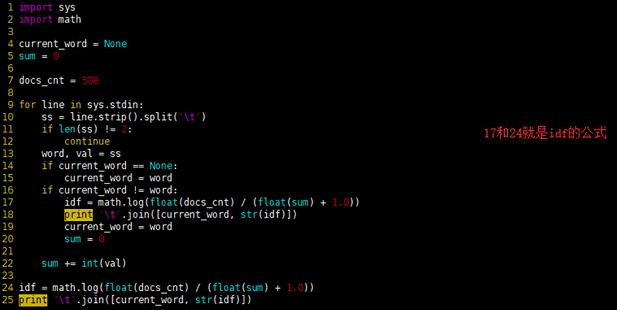
import sys
import math
current_word = None
sum = 0
docs_cnt = 508
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
word, val = ss
if current_word == None:
current_word = word
if current_word != word:
idf = math.log(float(docs_cnt) / (float(sum) + 1.0))
print '\t'.join([current_word, str(idf)])
current_word = word
sum = 0
sum += int(val)
idf = math.log(float(docs_cnt) / (float(sum) + 1.0))
print '\t'.join([current_word, str(idf)])
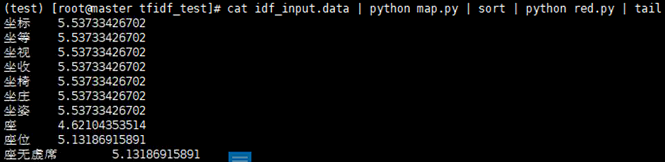
cat idf_input.data | python map.py | sort | python red.py | tail
测试一下,发现没有问题,注意数据量过大回报上面的异常
现在做mapReduce的准备工作,将我们预处理的数据提交到hdfs上

编写脚本run.sh
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH="/idf_input.data"
OUTPUT_PATH="/tfidf_output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-reducer "python red.py" \
-file ./map.py \
-file ./red.py
然后
bash run.sh hadoop fs -ls /tfidf_output hadoop fs -text /tfidf_output/part- | sort -k2 -n | head hadoop fs -text /tfidf_output/part- | sort -k2 -nr | head

8 NLP-自然语言处理Demo的更多相关文章
- flask 第六章 人工智能 百度语音合成 识别 NLP自然语言处理+simnet短文本相似度 图灵机器人
百度智能云文档链接 : https://cloud.baidu.com/doc/SPEECH/index.html 1.百度语音合成 概念: 顾名思义,就是将你输入的文字合成语音,例如: from a ...
- NLP 自然语言处理实战
前言 自然语言处理 ( Natural Language Processing, NLP) 是计算机科学领域与人工智能领域中的一个重要方向.它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和 ...
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
1. NLP 走近自然语言处理 概念 Natural Language Processing/Understanding,自然语言处理/理解 日常对话.办公写作.上网浏览 希望机器能像人一样去理解,以 ...
- NLP自然语言处理入门-- 文本预处理Pre-processing
引言 自然语言处理NLP(nature language processing),顾名思义,就是使用计算机对语言文字进行处理的相关技术以及应用.在对文本做数据分析时,我们一大半的时间都会花在文本预处理 ...
- NLP 自然语言处理
参考: 自然语言处理怎么最快入门:http://www.zhihu.com/question/ 自然语言处理简介:http://wenku.baidu.com/link?url=W6Mw1f-XN8s ...
- NLP自然语言处理学习笔记二(初试)
前言: 用Python对自然语言处理有很好的库.它叫NLTK.下面就是对NLTK的第一尝试. 安装: 1.安装Pip 比较简单,得益于CentOS7自带的easy_install.执行一行命令就可以搞 ...
- java自然语言理解demo,源码分享(基于欧拉蜜)
汇率换算自然语言理解功能JAVA DEMO >>>>>>>>>>>>>>>>>>>&g ...
- 初识NLP 自然语言处理
接下来的一段时间,要深入研究下自然语言处理这一个学科,以期能够带来工作上的提升. 学习如何实用python实现各种有关自然语言处理有关的事物,并了解一些有关自然语言处理的当下和新进的研究主题. NLP ...
- NLP 自然语言处理之综述
(1) NLP 介绍 NLP 是什么? NLP (Natural Language Processing) 自然语言处理,是计算机科学.人工智能和语言学的交叉学科,目的是让计算机处理或"理解 ...
- [NLP自然语言处理]谷歌BERT模型深度解析
我的机器学习教程「美团」算法工程师带你入门机器学习 已经开始更新了,欢迎大家订阅~ 任何关于算法.编程.AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主 ...
随机推荐
- angular2最详细的开发环境搭建过程
本文所需要的源代码,从 http://files.cnblogs.com/files/lingzhihua/angular2-quickstart.rar 下载 angular官方推荐使用quicks ...
- Ruby语言的一些杂项
Ruby是纯正血统的面向对象语言,所有的一切,一切的一切都是对象 Ruby里块(语句块)的特性非常重要,这个优美的特性贯穿整个Ruby Ruby里模块和类的概念一样重要,模块也是Ruby里的一个非常优 ...
- BZOJ 2152:聪聪可可(树上点分治)
题目链接 题意 中文题意. 思路 和上一题类似,只不过cal()函数需要发生变化. 题目中要求是3的倍数,那么可以想到 (a + b) % 3 == 0 和 (a % 3 + b % 3) % 3 = ...
- SpringMVC框架的简单理解
首先,让我们来看下下图 SpringMVC解决了View和Controller的交互问题 其中有几个重要组成部分: (1) DispatcherServlet: 前端控制器 用于接收所有请求,并负责分 ...
- while循环的初始以及编码的初始
whlie循环 why:比如要多次重复做一件事情,如歌曲列表循环,银行卡密码错误多次重复! what:whlie无限循环. how: ##基本结构while 条件: 循环体 基本原理 循环如何终 ...
- java 及 Jquery中的深复制 浅复制
发现问题:最近 遇到由于复制对象之后,改变复制后的新变量,原先被复制的对象居然会跟着变. EX:java中: //holidayConfig.getEnd_time()会随着sTime的改变而改变 s ...
- 《C#并发编程经典实例》学习笔记—2.7 避免上下文延续
避免上下文延续 在默认情况下,一个 async 方法在被 await 调用后恢复运行时,会在原来的上下文中运行. 为了避免在上下文中恢复运行,可让 await 调用 ConfigureAwait 方法 ...
- S7-1200 的运动控制
S7-1200 CPU本体集成点硬件输出点最高频率为100kHz,信号板上硬件集成点输出的最高频率为20kHz,CPU在使用PTO功能时将把集成点Qa.o,Qa.2或信号板的Q4.0作为脉冲输出点,Q ...
- 在CentOS6.5部署Redis为开机自启
2 - redis的生产启动方案 要把redis作为一个系统的daemon进程 去运行的,每次系统启动,redis进程一起启动,配置方案如下: 1. 在redis utils 目录下,有个redis_ ...
- Vue根据不同的路由文件实现打包差异化
有些时候我们经常一个项目中开发不同的功能,有可能一个前端项目中夹杂着不同系统之间的需求,最后打包发布的时候经常会将与项目不相关的代码一同打包进去,实际来讲这种操作也是不严谨的.那有没有办法可以根据某些 ...