【3】Decision tree(决策树)
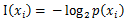
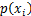 是选择该分类的概率。
是选择该分类的概率。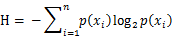
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#基于最后一列的分类标签,计算给定数据集的香农熵def calcShannonEnt(dataset): num_of_entries = len(dataset) label_counts = {} for feat_vec in dataset: current_lebel = feat_vec[-1] if current_lebel not in label_counts.keys(): label_counts[current_lebel] = 0 label_counts[current_lebel] += 1 shannonEnt = 0.0 for value in label_counts.values(): prob = float(value)/num_of_entries shannonEnt -= prob*log(prob, 2) return shannonEnt |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# =================================# 按照给定特征划分数据集# 输入:dataset数据集;# axis指定特征,用下标表示;# value需要返回的特征的值# 返回:数据集中特征值等于value的子集# =================================def splitDataset(dataset, axis, value): retDataset = [] for featVec in dataset: if featVec[axis] == value: reducedFeatVec = featVec[0:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataset.append(reducedFeatVec) return retDataset |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# ===============================================# 输入:# dataSet: 数据集# 输出:# bestFeature: 和原数据集熵差最大划分对应的特征的列号# ===============================================def chooseBestFeatureToSplit(dataSet): # 最后一列用于标签,剩下的才是特征 numFeatures = len(dataSet[0]) - 1 # 根据标签计算的熵 baseEntropy = calcShannonEnt(dataSet) bestInfoGain = 0.0; bestFeature = -1 # iterate over all the features for i in range(numFeatures): # 取出某个特征列的所有值 featList = [example[i] for example in dataSet] # 去重 uniqueVals = set(featList) newEntropy = 0.0 for value in uniqueVals: subDataSet = splitDataset(dataSet, i, value) prob = len(subDataSet)/float(len(dataSet)) newEntropy += prob * calcShannonEnt(subDataSet) # calculate the info gain,计算信息增益 infoGain = baseEntropy - newEntropy # 和目前最佳信息增益比较,如果更大则替换掉 if (infoGain > bestInfoGain): bestInfoGain = infoGain bestFeature = i # 返回代表某个特征的下标 return bestFeature |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#用于生成数据集,测试计算熵的函数def testDataset(): dataset1 = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] labels = ['no surfacing', 'flippers'] return dataset1, labels# 用于测试的函数def test(): mydata, labels = testDataset() print chooseBestFeatureToSplit(mydata) |
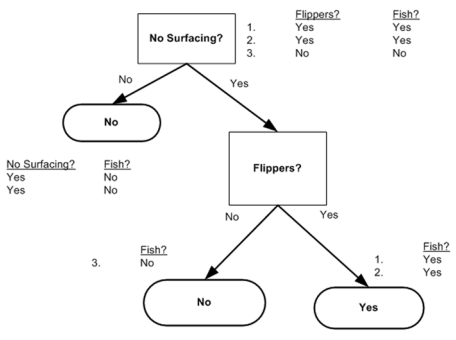
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# 传入分类名称组成的列表,返回出现次数最多的分类名称import operatordef majorityCnt(class_list): classCount = {} for vote in class_list: if vote not in classCount: classCount[vote] = 0 classCount[vote] += 1 sorted_class_list = sorted(classCount.iteritems(), key = operator.itemgetter(1), reverse=True) return sorted_class_list[0][0] |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
# ===============================================# 本函数用于创建决策树# 输入:# dataSet: 数据集# labels: 划分特征标签集# 输出:# myTree: 生成的决策树# ===============================================def createTree(dataSet, labels): # 获得类别标签列表 classList = [example[-1] for example in dataSet] # 递归终止条件一:如果数据集内所有分类一致 if classList.count(classList[0]) == len(classList): return classList[0] # 递归终止条件二:如果所有特征都划分完毕,任然不能将数据集划分成仅仅包含唯一类别的分组 if len(dataSet[0]) == 1: # 只剩下一列为类别列 return majorityCnt(classList) # 返回出现次数最多的类别 # 选择最佳划分特征,返回的时候特征的下标 best_feature = chooseBestFeatureToSplit(dataSet) best_feat_label = labels[best_feature] # 创建空树 myTree = {best_feat_label:{}} # 删除划分后的特征标签 del(labels[best_feature]) # 获取最佳划分特征中全部的特征值 featValues = [example[best_feature] for example in dataSet] # 去重 uniqueVals = set(featValues) for value in uniqueVals: subLabels = labels[:] # 保存用于下一次递归 myTree[best_feat_label][value] = createTree(splitDataset(dataSet, best_feature, value), subLabels) return myTree |

|
1
2
3
4
5
6
7
8
9
10
11
12
|
# 把传入的树序列化之后存入文件def storeTree(inputTree, filename): import pickle # 用于序列化的模块 fw = open(filename, 'w') pickle.dump(inputTree, fw) fw.close()# 从文件中把存好的树反序列化出来def grabTree(filename): import pickle fr = open(filename) return pickle.load(filename) |
【3】Decision tree(决策树)的更多相关文章
- Decision tree(决策树)算法初探
0. 算法概述 决策树(decision tree)是一种基本的分类与回归方法.决策树模型呈树形结构(二分类思想的算法模型往往都是树形结构) 0x1:决策树模型的不同角度理解 在分类问题中,表示基于特 ...
- decision tree 决策树(一)
一 决策树 原理:分类决策树模型是一种描述对实例进行分类的树形结构.决策树由结点(node)和有向边(directed edge)组成.结点有两种类型:内部结点(internal node)和叶结点( ...
- Decision tree——决策树
基本流程 决策树是通过分次判断样本属性来进行划分样本类别的机器学习模型.每个树的结点选择一个最优属性来进行样本的分流,最终将样本类别划分出来. 决策树的关键就是分流时最优属性$a$的选择.使用所谓信息 ...
- OpenCV码源笔记——Decision Tree决策树
来自OpenCV2.3.1 sample/c/mushroom.cpp 1.首先读入agaricus-lepiota.data的训练样本. 样本中第一项是e或p代表有毒或无毒的标志位:其他是特征,可以 ...
- 决策树Decision Tree 及实现
Decision Tree 及实现 标签: 决策树熵信息增益分类有监督 2014-03-17 12:12 15010人阅读 评论(41) 收藏 举报 分类: Data Mining(25) Pyt ...
- 用于分类的决策树(Decision Tree)-ID3 C4.5
决策树(Decision Tree)是一种基本的分类与回归方法(ID3.C4.5和基于 Gini 的 CART 可用于分类,CART还可用于回归).决策树在分类过程中,表示的是基于特征对实例进行划分, ...
- 决策树(decision tree)
决策树是一种常见的机器学习模型.形象地说,决策树对应着我们直观上做决策的过程:经由一系列判断,得到最终决策.由此,我们引出决策树模型. 一.决策树的基本流程 决策树的跟节点包含全部样例,叶节点则对应决 ...
- (ZT)算法杂货铺——分类算法之决策树(Decision tree)
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1.摘要 在前面两篇文章中,分别介绍和讨论了朴素贝叶斯分 ...
- 决策树decision tree原理介绍_python sklearn建模_乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
随机推荐
- Angualr6表单提交验证并跳转
在Angular6中,使用NG-ZRROR作为前端开发框架,在进行表单开发时遇到了一些问题,最后解决了,在此记录. 1.表单构造: 引入forms: import { FormGroup, FormB ...
- 用命令将本地jar包导入到本地maven仓库
[**前情提要**]在日常开发过程中,我们总是不可避免的需要依赖某些不在中央仓库,同时也不在本地仓库中的jar包,这是我们就需要使用命令行将需要导入本地仓库中的jar包导入本地仓库,使得项目依赖本地仓 ...
- python多线程同步实例分析
进程之间通信与线程同步是一个历久弥新的话题,对编程稍有了解应该都知道,但是细说又说不清.一方面除了工作中可能用的比较少,另一方面就是这些概念牵涉到的东西比较多,而且相对较深.网络编程,服务端编程,并发 ...
- JavaScript循环出现的问题——用闭包来解决
在for循环中,数组长度为3,我本来是想对每个循环的元素绑定一个点击事件的,结果点击后控制台输出全部为1. for (var i = 0; i < data.data.length; i++) ...
- linux装OpenOffice后传---中文乱码的解决
上一篇的博客已经详细的介绍了linux系统上如何安装OpenOffice,安装之后使用发现转换的pdf出现中文乱码.后来发现是linux上没有中文对应的那个字体. 字体准备 在windows上的位置 ...
- 程序员修神之路--用NOSql给高并发系统加速(送书)
随着互联网大潮的到来,越来越多网站,应用系统需要海量数据的支撑,高并发.低延迟.高可用.高扩展等要求在传统的关系型数据库中已经得不到满足,或者说关系型数据库应对这些需求已经显得力不从心了.关系型数据库 ...
- 100天搞定机器学习|day38 反向传播算法推导
往期回顾 100天搞定机器学习|(Day1-36) 100天搞定机器学习|Day37无公式理解反向传播算法之精髓 上集我们学习了反向传播算法的原理,今天我们深入讲解其中的微积分理论,展示在机器学习中, ...
- tensorflow学习笔记——多线程输入数据处理框架
之前我们学习使用TensorFlow对图像数据进行预处理的方法.虽然使用这些图像数据预处理的方法可以减少无关因素对图像识别模型效果的影响,但这些复杂的预处理过程也会减慢整个训练过程.为了避免图像预处理 ...
- powerdesigner16.6版本resource的重复使用
今天早上遇到想要重复使用resource ,但是发现powerdesigner16.6版本跟16.5版本有关重复使用name的设置已经不一样了,网上找了好久没找到,软件上找了好久也没找到相应的设置. ...
- 敏捷社区--敏捷与OKR
携程敏捷总动员是由携程技术管理中心(PMO)发起的敏捷项目管理线下主题沙龙活动(每2月一次),旨在和研发管理同行分享互联网行业第一线的优秀敏捷实践. 5月10日携程敏捷总动员-OKR专场活动, ...