【3】Decision tree(决策树)
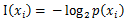
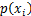 是选择该分类的概率。
是选择该分类的概率。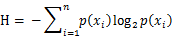
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#基于最后一列的分类标签,计算给定数据集的香农熵def calcShannonEnt(dataset): num_of_entries = len(dataset) label_counts = {} for feat_vec in dataset: current_lebel = feat_vec[-1] if current_lebel not in label_counts.keys(): label_counts[current_lebel] = 0 label_counts[current_lebel] += 1 shannonEnt = 0.0 for value in label_counts.values(): prob = float(value)/num_of_entries shannonEnt -= prob*log(prob, 2) return shannonEnt |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# =================================# 按照给定特征划分数据集# 输入:dataset数据集;# axis指定特征,用下标表示;# value需要返回的特征的值# 返回:数据集中特征值等于value的子集# =================================def splitDataset(dataset, axis, value): retDataset = [] for featVec in dataset: if featVec[axis] == value: reducedFeatVec = featVec[0:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataset.append(reducedFeatVec) return retDataset |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# ===============================================# 输入:# dataSet: 数据集# 输出:# bestFeature: 和原数据集熵差最大划分对应的特征的列号# ===============================================def chooseBestFeatureToSplit(dataSet): # 最后一列用于标签,剩下的才是特征 numFeatures = len(dataSet[0]) - 1 # 根据标签计算的熵 baseEntropy = calcShannonEnt(dataSet) bestInfoGain = 0.0; bestFeature = -1 # iterate over all the features for i in range(numFeatures): # 取出某个特征列的所有值 featList = [example[i] for example in dataSet] # 去重 uniqueVals = set(featList) newEntropy = 0.0 for value in uniqueVals: subDataSet = splitDataset(dataSet, i, value) prob = len(subDataSet)/float(len(dataSet)) newEntropy += prob * calcShannonEnt(subDataSet) # calculate the info gain,计算信息增益 infoGain = baseEntropy - newEntropy # 和目前最佳信息增益比较,如果更大则替换掉 if (infoGain > bestInfoGain): bestInfoGain = infoGain bestFeature = i # 返回代表某个特征的下标 return bestFeature |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#用于生成数据集,测试计算熵的函数def testDataset(): dataset1 = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] labels = ['no surfacing', 'flippers'] return dataset1, labels# 用于测试的函数def test(): mydata, labels = testDataset() print chooseBestFeatureToSplit(mydata) |
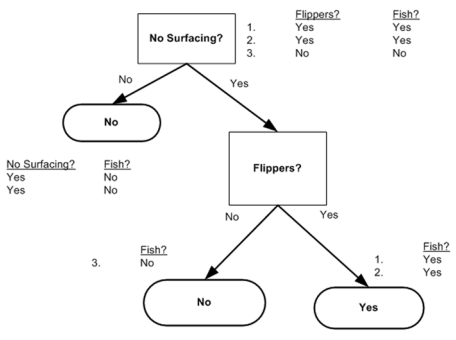
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# 传入分类名称组成的列表,返回出现次数最多的分类名称import operatordef majorityCnt(class_list): classCount = {} for vote in class_list: if vote not in classCount: classCount[vote] = 0 classCount[vote] += 1 sorted_class_list = sorted(classCount.iteritems(), key = operator.itemgetter(1), reverse=True) return sorted_class_list[0][0] |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
# ===============================================# 本函数用于创建决策树# 输入:# dataSet: 数据集# labels: 划分特征标签集# 输出:# myTree: 生成的决策树# ===============================================def createTree(dataSet, labels): # 获得类别标签列表 classList = [example[-1] for example in dataSet] # 递归终止条件一:如果数据集内所有分类一致 if classList.count(classList[0]) == len(classList): return classList[0] # 递归终止条件二:如果所有特征都划分完毕,任然不能将数据集划分成仅仅包含唯一类别的分组 if len(dataSet[0]) == 1: # 只剩下一列为类别列 return majorityCnt(classList) # 返回出现次数最多的类别 # 选择最佳划分特征,返回的时候特征的下标 best_feature = chooseBestFeatureToSplit(dataSet) best_feat_label = labels[best_feature] # 创建空树 myTree = {best_feat_label:{}} # 删除划分后的特征标签 del(labels[best_feature]) # 获取最佳划分特征中全部的特征值 featValues = [example[best_feature] for example in dataSet] # 去重 uniqueVals = set(featValues) for value in uniqueVals: subLabels = labels[:] # 保存用于下一次递归 myTree[best_feat_label][value] = createTree(splitDataset(dataSet, best_feature, value), subLabels) return myTree |

|
1
2
3
4
5
6
7
8
9
10
11
12
|
# 把传入的树序列化之后存入文件def storeTree(inputTree, filename): import pickle # 用于序列化的模块 fw = open(filename, 'w') pickle.dump(inputTree, fw) fw.close()# 从文件中把存好的树反序列化出来def grabTree(filename): import pickle fr = open(filename) return pickle.load(filename) |
【3】Decision tree(决策树)的更多相关文章
- Decision tree(决策树)算法初探
0. 算法概述 决策树(decision tree)是一种基本的分类与回归方法.决策树模型呈树形结构(二分类思想的算法模型往往都是树形结构) 0x1:决策树模型的不同角度理解 在分类问题中,表示基于特 ...
- decision tree 决策树(一)
一 决策树 原理:分类决策树模型是一种描述对实例进行分类的树形结构.决策树由结点(node)和有向边(directed edge)组成.结点有两种类型:内部结点(internal node)和叶结点( ...
- Decision tree——决策树
基本流程 决策树是通过分次判断样本属性来进行划分样本类别的机器学习模型.每个树的结点选择一个最优属性来进行样本的分流,最终将样本类别划分出来. 决策树的关键就是分流时最优属性$a$的选择.使用所谓信息 ...
- OpenCV码源笔记——Decision Tree决策树
来自OpenCV2.3.1 sample/c/mushroom.cpp 1.首先读入agaricus-lepiota.data的训练样本. 样本中第一项是e或p代表有毒或无毒的标志位:其他是特征,可以 ...
- 决策树Decision Tree 及实现
Decision Tree 及实现 标签: 决策树熵信息增益分类有监督 2014-03-17 12:12 15010人阅读 评论(41) 收藏 举报 分类: Data Mining(25) Pyt ...
- 用于分类的决策树(Decision Tree)-ID3 C4.5
决策树(Decision Tree)是一种基本的分类与回归方法(ID3.C4.5和基于 Gini 的 CART 可用于分类,CART还可用于回归).决策树在分类过程中,表示的是基于特征对实例进行划分, ...
- 决策树(decision tree)
决策树是一种常见的机器学习模型.形象地说,决策树对应着我们直观上做决策的过程:经由一系列判断,得到最终决策.由此,我们引出决策树模型. 一.决策树的基本流程 决策树的跟节点包含全部样例,叶节点则对应决 ...
- (ZT)算法杂货铺——分类算法之决策树(Decision tree)
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1.摘要 在前面两篇文章中,分别介绍和讨论了朴素贝叶斯分 ...
- 决策树decision tree原理介绍_python sklearn建模_乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
随机推荐
- 编码规范 | Java函数优雅之道(上)
导读 随着软件项目代码的日积月累,系统维护成本变得越来越高,是所有软件团队面临的共同问题.持续地优化代码,提高代码的质量,是提升系统生命力的有效手段之一.软件系统思维有句话“Less coding, ...
- 对vue中nextTick()的理解及使用场景说明
异步更新队列: 首先我们要对vue的数据更新有一定理解: vue是依靠数据驱动视图更新的,该更新的过程是异步的. 即:当侦听到你的数据发生变化时, Vue将开启一个队列(该队列被Vue官方称为异步更新 ...
- 【Java例题】1.3给朋友的贺卡
3.对“Hello World”程序进行改造, 能够显示一张发给朋友的贺卡.格式如下: ****************************** 张三,你好! 祝你学习愉快! 你的好朋友:李四 2 ...
- python3学习-Queue模块
python标准库中带有一个Queue模块,顾名思义,队列.该模块也衍生出一些基本队列不具有的功能. 我们先看一下队列的方法: put 存数据 get 取数据 empty 判断队列是否为空 qsize ...
- WebSphere MQ性能调优浅谈
导读:目前随着我们在中国的WebSphere MQ(MQSeries)用户数量越来越多,越来越多的用户开始对MQ使用时的性能优化问题提出要求,我根据日常积累的经验谈一谈在MQ性能优化方面应该考虑的因素 ...
- SpringBoot操作ES进行各种高级查询
SpringBoot整合ES 创建SpringBoot项目,导入 ES 6.2.1 的 RestClient 依赖和 ES 依赖.在项目中直接引用 es-starter 的话会报容器初始化异常错误,导 ...
- 我的C语言学习1
学习是快乐的,尤其是从之前看到一个程序的一头雾水到大致懂了是怎么回事,这个过程是兴奋开心的,让我不断的前进,不能自拔,今天就要结束,总结一下. 1.1-第一个C语言 #include<stdio ...
- 2321. 【NOIP普及组T1】方程
2321. [NOIP普及组T1]方程 时间限制: 1000 ms 空间限制: 262144 KB 题目描述
- React中控制台警告
1.dll_lib.js:1 Warning: bind(): You are binding a component method to the component. React does this ...
- 基于ZooKeeper的三种分布式锁实现
[欢迎关注公众号:程序猿讲故事 (codestory),及时接收最新文章] 今天介绍基于ZooKeeper的分布式锁的简单实现,包括阻塞锁和非阻塞锁.同时增加了网上很少介绍的基于节点的非阻塞锁实现,主 ...