Hadoop原生搭建
版本:(centos7.6)
在开始搭建平台前我已经预装了MySQL
ps:MySQL创建用户并授权:
grant all privileges on *.* to 'root'@'localhost' identified by '' with grant option
好了,不多说,开始配置:
我采用了master,slave1,slave2三个节点,我自己是利用kvm化的虚拟机。
对应IP地址:
master:172.16.90.145
slave1:172.16.90.147
slave2:172.16.90.148
1、为了方便,加上自己在虚拟机上搭建,关闭Selinux,firewalld
2、更改hosts,即配置主机映射,更改完成scp拷贝
echo '172.16.90.145 master' >> /etc/hosts
echo '172.16.90.147 slave1' >> /etc/hosts
echo '172.16.90.148 slave2' >> /etc/hosts scp /etc/hosts slave1:/etc/hosts
scp /etc/hosts slave2:/etc/hosts
3、配置ssh免密:(这里为了方便我设置的空密码,并做的三方免密)
ssh-keygen ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
4、安装jdk(即Java)
导入jdk后解压,创建软连接,加入环境变量,source环境变量文件,最后查看版本号
tar zxvf jdk-8u111-linux-x64.tar.gz ln -s /usr/local/jdk1..0_111 /usr/local/java echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
echo 'JAVA_HOME=/usr/local/jdk1.8.0_111' >> /etc/profile source /etc/profile java -version
5、安装Hadoop:
解压
tar zxvf hadoop-2.9..tar.gz
创建软连接
ln -s /usr/local/hadoop-2.9./ /usr/local/hadoop
加入环境变量并使之生效
echo 'HADOOP_HOME=/usr/local/hadoop-2.9.0/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin,sbin' >> /etc/profile
source /etc/profile
修改配置文件
在master主机上建立namenode本地数据目录
mkdir -p /data/nn
在slave1,slave2中建立datanode本地数据目录
mkdir -p /data/dn
在master中编辑core-site.xml,在 <configuration> 节点中增加如下内容
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value></value>
</property>
在master中编辑 hdfs-site.xml,在 <configuration> 节点中增加如下内容
<property>
<name>dfs.nameslave.name.dir</name>
<value>file:///data/nn</value>
</property>
<property>
<name>dfs.dataslave.data.dir</name>
<value>file:///data/dn</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.nameslave.secondary.http-address</name>
<value>master:</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</proper
在master中,将mapred-site.xml.template 复制一份 ,变成mapred-site.xml,编辑mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master:</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
</property>
在master中,编辑yarn-site.xml,
<property>
<name>yarn.slavemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.slavemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.slavemanager.resource.memory-mb</name>
<value></value>
</property>
将 master服务器上已经完成的 hadoop 配置 复制到各个节点对应位置上,输入以下命令进行 scp 传送:
scp -r /usr/local/hadoop/* slave1: /usr/local/hadoop/
scp -r /usr/local/hadoop/* slave2: /usr/local/hadoop/
在master中,初始化hadoop的namenode
启动hadoop
hadoop-daemon.sh namenode -format
./start-all.sh
最后使用jps命令查看节点启动的服务是否正确
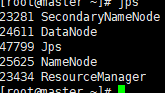
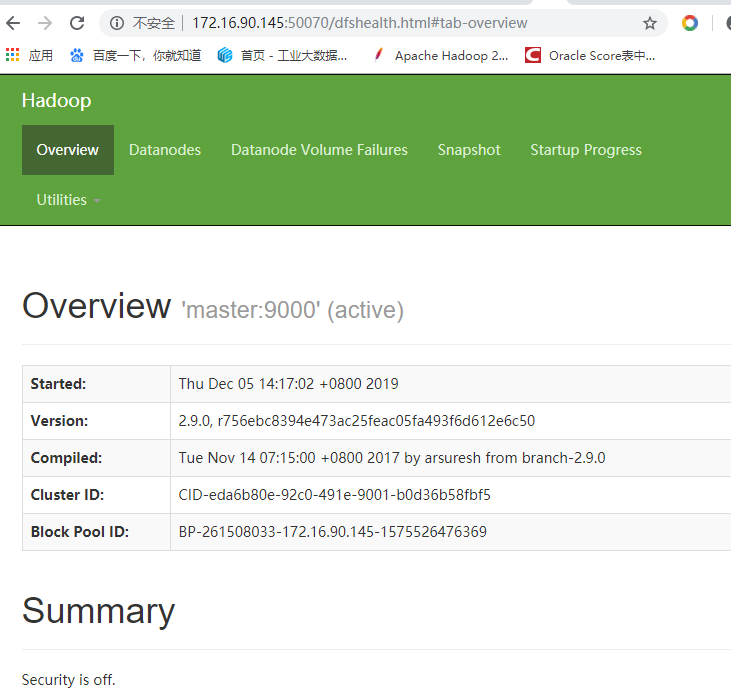
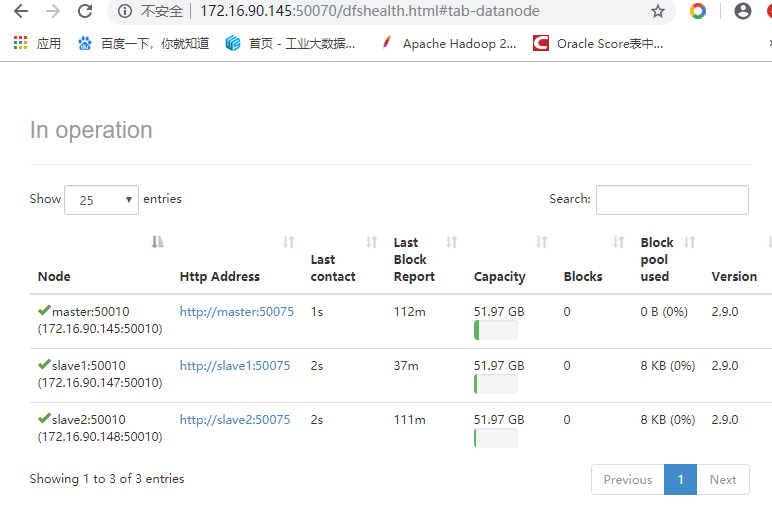
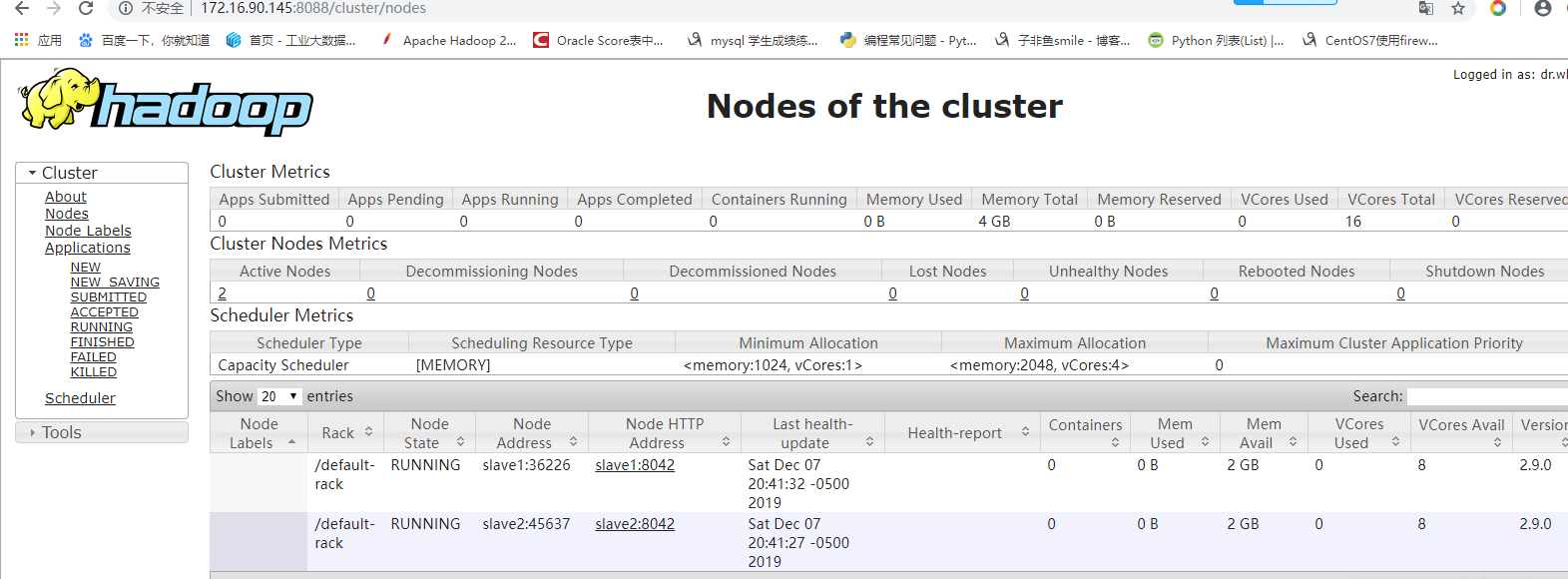
启动成功可以查看web界面了
Hadoop原生搭建的更多相关文章
- 【转】RHadoop实践系列之一:Hadoop环境搭建
RHadoop实践系列之一:Hadoop环境搭建 RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析.Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- 服务器Hadoop+Hive搭建
出于安全稳定考虑很多业务都需要服务器服务器Hadoop+Hive搭建,但经常有人问我,怎么去选择自己的配置最好,今天天气不错,我们一起来聊一下这个话题. Hadoop+Hive环境搭建 1虚拟机和系统 ...
- 通过hadoop + hive搭建离线式的分析系统之快速搭建一览
最近有个需求,需要整合所有店铺的数据做一个离线式分析系统,曾经都是按照店铺分库分表来给各自商家通过highchart多维度展示自家的店铺经营 数据,我们知道这是一个以店铺为维度的切分数据,非常适合目前 ...
- hadoop分布式搭建
1.新建三台机器,分别为: hadoop分布式搭建至少需要三台机器: master extension1 extension2 本文利用在VMware Workstation下安装Linux cent ...
- eclipse工具下hadoop环境搭建
eclipse工具下hadoop环境搭建: window10操作系统中搭建eclipse64开发系统,配置hadoop的eclipse插件,让eclipse可以查看Hdfs中的文件内容. ...
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- Hadoop环境搭建、启动和管理界面查看
一.hadoop环境搭建: 1. hadoop 6个核心配置文件的作用:core-site.xml:核心配置文件,主要定义了我们文件访问的格式 hdfs://hadoop-env.sh:主要配置我们的 ...
- Ubuntu中Hadoop环境搭建
Ubuntu中Hadoop环境搭建 JDK安装 方法一:通过命令行直接安装(不建议) 有两种java可以安装oracle-java8-installer以及openjdk (1)安装oracle-ja ...
随机推荐
- Python文件处理:创建、打开、追加、读、写
在Python中,不需要导入外部库来读取和写入文件.Python为创建.写入和读取文件提供了内置的函数. 在本文中,我们将学习 如何创建文本文件 如何将数据附加到文件中 如何读取文件 如何逐行读取文件 ...
- [考试反思]1104csp-s模拟测试100: 终结
这么好的整数场,就终结了我连续莫名考好的记录. 功德圆满了... 还是炸了啊.而且炸的还挺厉害(自己又上不去自己粘的榜单啦) 说实在的这场考试做的非常差劲.虽说分数不算特别低但是表现是真的特别差. T ...
- Docker 学习 | 基础命令
基本概念定义 基本组成 客户端/守护进程 C/S架构 本地/服务器 镜像 容器基石 只读文件系统 联合加载(union mount) 容器 通过镜像启动 执行 写时复制 仓库 公有 docker hu ...
- maven安装与在eclipse中配置
需要准备 eclipse maven压缩包 : http://maven.apache.org/download.cgi 1 解压maven压缩包 2 在系统变量中新建变量MAVEN_HOME,值为 ...
- Python 命令行之旅:深入 click 之选项篇
作者:HelloGitHub-Prodesire HelloGitHub 的<讲解开源项目>系列,项目地址:https://github.com/HelloGitHub-Team/Arti ...
- 区块链原理、设计与应用pdf电子版下载
链接:https://pan.baidu.com/s/1koShkDjEYOXxLOewZJU2Rw 提取码:8ycx 内容简介 · · · · · · 本书由专业区块链开发者撰写,是区块链开发起步 ...
- hdu 1530 Maximum Clique (最大包)
Maximum CliqueTime Limit: 20000/10000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)T ...
- Apache服务安装及一些基本操作
注意:安装apache服务之前记得搭建yum仓库 1.安装apache服务,输入命令“yum install httpd” 安装成功后,会这样显示 2.需要对Apache服务进行启动,输入命令“sys ...
- oracle使用parallel并行,多线程查询
insert into tmp (select /*parallel (a, 4)*/ * from plsuer.as_cdrindex_info_h partition(P_20170430) w ...
- 同时发起TCP连接
如果你的socket编程只限于创建SOCK_STREAM的socket,用connect-accept建立连接,然后就是recv,send.你就会惊奇tcp连接还可以不用accept. 上图为两个AF ...