jTessBoxEditor训练识别库
1、背景
前文已经简要介绍tesseract ocr引擎的安装及基本使用,其中提到使用-l eng参数来限定语言库,可以提高识别准确率及识别效率。
本文将针对某个网站的验证码进行样本训练,形成自己的语言库,来提高验证码识别率。
2、准备工具
tesseract样本训练有一个官方流程说明,https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract#run-tesseract-for-training,不过都是英文的,个人认为这个地址适合于查找细节问题,全程看E文对大众还是有一定的困难。
具体的方法有两种:1-利用三方工具,2-完全命令行操作,三方工具主要在https://github.com/tesseract-ocr/tesseract/wiki/AddOns下载,本文将用到jTessBoxEditor这个工具,我们先给他下载到本地。
需要特别说明,这个工具是基于java虚拟机运行的,所以我们还要下载并安装一个java虚拟机,下载地址:http://download.oracle.com/otn-pub/java/jdk/8u91-b14/jdk-8u91-windows-x64.exe?AuthParam=1463733597_1161f2d895aa7606ed260b43b83d5f86。
总结一下:
1、工具2 java虚拟机 Ver 1.8.0_91 64位版本 (oracle官网)
2、工具1 jtessboxeditor Ver 1.5版本 (jtessboxeditor官网),运行界面如下:
3、使用实例
1)、准备样本图片
手动刷新某网站验证码 ,手动或者写程序,保存了101个验证码样本文件,分别命名成:1.png,2.png,……,101.png。
,手动或者写程序,保存了101个验证码样本文件,分别命名成:1.png,2.png,……,101.png。
该验证码有几个特点:a、定长4位,b、都是数字,c、有背景干扰,但比较简单,d、字体为红色。
为了提高识别率,首先做了一个工作就是灰度化处理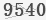 ,并全部转换成tif文件,分别命名成:1.tif,2.tif,……,101.tif,统一存放在d:\python\lnypcg下。
,并全部转换成tif文件,分别命名成:1.tif,2.tif,……,101.tif,统一存放在d:\python\lnypcg下。
2)、合并样本图片
打开jtessboxeditor,点击Tools->Merge Tiff ,按住shift键选择前文提到的101个tif文件,并把生成的tif合并到新目录d:\python\lnypcg\new下,命名为langyp.fontyp.exp0.tif。
注意:langyp 是本人定义的语言名称,fontyp是本人定义的字体名称,后续都会用到,你可以修改成你喜欢的名字。
3)、生成box文件
执行命令生成langyp.fontyp.exp0.box文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l eng -psm 7 batch.nochop makebox

D:\python\lnypcg\new>tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l eng -psm 7 batch.nochop makebox
Tesseract Open Source OCR Engine v3.02 with Leptonica
Page 1 of 101
Page 2 of 101
Page 3 of 101
……
Page 101 of 101
D:\python\lnypcg\new>dir
驱动器 D 中的卷没有标签。
卷的序列号是 36D9-CDC7
D:\python\lnypcg\new 的目录
2016-06-03 14:37 <DIR> .
2016-06-03 14:37 <DIR> ..
2016-06-03 14:30 6,327 langyp.fontyp.exp0.box
2016-06-03 13:07 126,056 langyp.fontyp.exp0.tif
2 个文件 132,383 字节
2 个目录 24,869,994,496 可用字节
4)、修改box文件
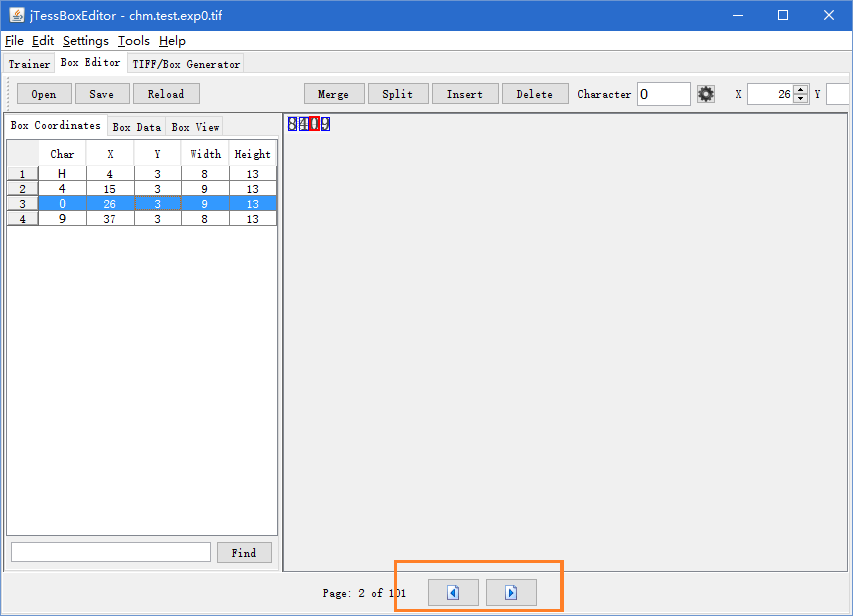
切换到jTessBoxEditor工具的Box Editor页,点击open,打开前面的tiff文件langyp.fontyp.exp0.tif,工具会自动加载对应的box文件。
检查box数据,如下图所示,数字8被误认成字母H,手工修改H成8,并保存。
点击下图红色框的按钮,逐个核对tif文件的box数据,全部检查结束并保存。
5)、生成font_properties
执行echo命令生成font_properties。
echo fontyp 0 0 0 0 0 >font_properties
也可以手工新建一个名为font_properties的文本文件(注意该文件没有扩展名),内容为字体名fontyp,后面带5个0,分别代表字体的粗体、斜体等属性,这里全部是0
D:\python\lnypcg\new>echo fontyp 0 0 0 0 0 >font_properties
D:\python\lnypcg\new>type font_properties
fontyp 0 0 0 0 0
6)、生成训练文件
执行命令,生成langyp.fontyp.exp0.tr训练文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l eng -psm 7 nobatch box.train
D:\python\lnypcg\new>tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l eng -psm 7 nobatch box.train
Tesseract Open Source OCR Engine v3.02 with Leptonica
Page 1 of 101
row xheight=8.66667, but median xheight = 10
APPLY_BOXES:
Boxes read from boxfile: 4
Found 4 good blobs.
Generated training data for 1 words
……
……
……
Page 101 of 101
row xheight=8.66667, but median xheight = 10
APPLY_BOXES:
Boxes read from boxfile: 4
Found 4 good blobs.
Generated training data for 1 words
D:\python\lnypcg\new 的目录
2016-06-03 16:34 <DIR> .
2016-06-03 16:34 <DIR> ..
2016-06-03 16:05 16 font_properties
2016-06-03 14:30 6,327 langyp.fontyp.exp0.box
2016-06-03 13:07 126,056 langyp.fontyp.exp0.tif
2016-06-03 16:20 618,844 langyp.fontyp.exp0.tr
2016-06-03 16:20 202 langyp.fontyp.exp0.txt
5 个文件 751,445 字节
2 个目录 24,869,101,568 可用字节
7)、生成字符集文件
执行命令,生成名为unicharset的字符集文件。
unicharset_extractor langyp.fontyp.exp0.box
D:\python\lnypcg\new>unicharset_extractor langyp.fontyp.exp0.box
Extracting unicharset from langyp.fontyp.exp0.box
Wrote unicharset file ./unicharset.
D:\python\lnypcg\new>dir
驱动器 D 中的卷没有标签。
卷的序列号是 36D9-CDC7
D:\python\lnypcg\new 的目录
2016-06-03 16:41 <DIR> .
2016-06-03 16:41 <DIR> ..
2016-06-03 16:05 16 font_properties
2016-06-03 14:30 6,327 langyp.fontyp.exp0.box
2016-06-03 13:07 126,056 langyp.fontyp.exp0.tif
2016-06-03 16:20 618,844 langyp.fontyp.exp0.tr
2016-06-03 16:20 202 langyp.fontyp.exp0.txt
2016-06-03 16:41 712 unicharset
6 个文件 752,157 字节
2 个目录 24,869,171,200 可用字节
8)、生成shape文件
执行命令,生成shape文件
shapeclustering -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
D:\python\lnypcg\new>shapeclustering -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
Reading langyp.fontyp.exp0.tr ...
Building master shape table
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0 1 2 3 4 5 6 7 8 9 10
Stopped with 0 merged, min dist 0.057803
Master shape_table:Number of shapes = 11 max unichars = 1 number with multiple unichars = 0
D:\python\lnypcg\new>dir
驱动器 D 中的卷没有标签。
卷的序列号是 36D9-CDC7
D:\python\lnypcg\new 的目录
2016-06-03 17:24 <DIR> .
2016-06-03 17:24 <DIR> ..
2016-06-03 17:20 19 font_properties
2016-06-03 14:30 6,327 langyp.fontyp.exp0.box
2016-06-03 13:07 126,056 langyp.fontyp.exp0.tif
2016-06-03 17:23 618,844 langyp.fontyp.exp0.tr
2016-06-03 17:23 202 langyp.fontyp.exp0.txt
2016-06-03 17:24 723 langyp.unicharset
2016-06-03 17:24 202 shapetable
2016-06-03 17:24 712 unicharset
8 个文件 753,085 字节
2 个目录 24,868,278,272 可用字节
9)、生成聚集字符特征文件
执行命令,生成3个特征字符文件,unicharset、inttemp、pffmtable
mftraining -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
D:\python\lnypcg\new>mftraining -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
Read shape table shapetable of 11 shapes
Reading langyp.fontyp.exp0.tr ...
Done!
10)、生成字符正常化特征文件
执行命令,生成正常化特征文件normproto。
cntraining langyp.fontyp.exp0.tr
D:\python\lnypcg\new>cntraining langyp.fontyp.exp0.tr
Reading langyp.fontyp.exp0.tr ...
Clustering ...
11)、更名
执行命令,把步骤9,步骤10生成的特征文件进行更名。
rename normproto fontyp.normprotorename inttemp fontyp.inttemprename pffmtable fontyp.pffmtable rename unicharset fontyp.unicharsetrename shapetable fontyp.shapetable
D:\python\lnypcg\new>rename normproto fontyp.normproto
D:\python\lnypcg\new>rename inttemp fontyp.inttemp
D:\python\lnypcg\new>rename pffmtable fontyp.pffmtable
D:\python\lnypcg\new>rename unicharset fontyp.unicharset
D:\python\lnypcg\new>rename shapetable fontyp.shapetable
12)、合并训练文件
执行命令,生成fontyp.traineddata文件。
combine_tessdata fontyp.
注意:
a、fontyp.traineddata文件最终要拷贝tesseract安装目录的tessdata目录下,才能被tesseract找到。
b、命令行最后必须带一个点。
c、执行结果中,1,3,4,5,13这几行必须有数值,才代表命令执行成功。
D:\python\lnypcg\new>combine_tessdata fontyp.
Combining tessdata files
TessdataManager combined tesseract data files.
Offset for type 0 is -1
Offset for type 1 is 140
Offset for type 2 is -1
Offset for type 3 is 852
Offset for type 4 is 137760
Offset for type 5 is 137850
Offset for type 6 is -1
Offset for type 7 is -1
Offset for type 8 is -1
Offset for type 9 is -1
Offset for type 10 is -1
Offset for type 11 is -1
Offset for type 12 is -1
Offset for type 13 is 139352
Offset for type 14 is -1
Offset for type 15 is -1
Offset for type 16 is -1
13)测试使用
譬如前文的28.tif 中8被误认为字母S,用新的字体看是否还出错。
中8被误认为字母S,用新的字体看是否还出错。
D:\python\lnypcg>tesseract 28.tif output -l eng -psm 7
Tesseract Open Source OCR Engine v3.02 with Leptonica
D:\python\lnypcg>type output.txt
S094
#1调用默认的eng语言,8被识别成S
D:\python\lnypcg>tesseract 28.tif output -l fontyp -psm 7
Error opening data file C:\Program Files (x86)\Tesseract-OCR\tessdata/fontyp.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory.
Failed loading language 'fontyp'
Tesseract couldn't load any languages!
Could not initialize tesseract.
#2条用新的fontyp语言,tesseract找不到fontyp语言。
D:\python\lnypcg>copy .\new\fontyp.traineddata "C:\Program Files (x86)\Tesseract-OCR\tessdata"
已复制 1 个文件。
#3复制fontyp.traineddata到tesseract的安装目录的tessdata子目录下
D:\python\lnypcg>tesseract 28.tif output -l fontyp -psm 7
Tesseract Open Source OCR Engine v3.02 with Leptonica
D:\python\lnypcg>type output.txt
8094
#使用fontyp语言成功识别8094
4、总结:
Anyway,jtessboxeditor 工具其实是一个基本成型的三方样本训练工具,它的功能就是自动执行上述脚本命令,但是在实际使用中,还存在不够完善的地方,譬如不能加psm参数,生成shape时经常程序异常崩溃,所以本文操作还是以命令行为主。
tesseract是一个非常强大的ocr引擎,尤其是做了针对性训练之后,验证码识别率几乎可以达到95%以上,再在程序中增加一些判断机制,基本上可以满足爬虫自动登陆需求了,回头写一个某东的自动识别验证码的爬虫程序。
把前文提的简化一下,综合成如下步骤列表:
1、合并图片
2、生成box文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l eng -psm 7 batch.nochop makebox
3、修改box文件
4、生成font_properties
echo fontyp 0 0 0 0 0 >font_properties
5、生成训练文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l eng -psm 7 nobatch box.train
6、生成字符集文件
unicharset_extractor langyp.fontyp.exp0.box
7、生成shape文件
shapeclustering -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
8、生成聚集字符特征文件
mftraining -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
9、生成字符正常化特征文件
cntraining langyp.fontyp.exp0.tr
10、更名
rename normproto fontyp.normproto
rename inttemp fontyp.inttemp
rename pffmtable fontyp.pffmtable
rename unicharset fontyp.unicharset
rename shapetable fontyp.shapetable
11、合并训练文件,生成fontyp.traineddata
combine_tessdata fontyp.

jTessBoxEditor训练识别库的更多相关文章
- Tesseract-OCR 自动生成识别库的批处理
用Tesseract-OCR做识别库的时候,生成字典非常麻烦,就写了一个批处理,用来生成字典还是蛮方便的,希望大家有用,该批处理已经自动生成font_properties文件,各位无需手动创建 下载地 ...
- Python的开源人脸识别库:离线识别率高达99.38%
Python的开源人脸识别库:离线识别率高达99.38% github源码:https://github.com/ageitgey/face_recognition#face-recognitio ...
- Java 验证码识别库 Tess4j 学习
Java 验证码识别库 Tess4j 学习 [在用java的Jsoup做爬虫爬取数据时遇到了验证码识别的问题(基于maven),找了网上挺多的资料,发现Tess4j可以自动识别验证码,在这里简单记录下 ...
- 开源OCR识别库-Tesseract介绍
最近在github上面看到一个开源的ocr文字识别库,感觉效果还可以,所以在这里介绍一下,这个项目的原地址在:https://github.com/tesseract-ocr/tesseract. t ...
- Python的开源人脸识别库:离线识别率高达99.38%(附源码)
Python的开源人脸识别库:离线识别率高达99.38%(附源码) 转https://cloud.tencent.com/developer/article/1359073 11.11 智慧上云 ...
- face_recognition开源人脸识别库:离线识别率高达99.38%
基于Python的开源人脸识别库:离线识别率高达99.38%——新开源的用了一下感受一下 原创 2017年07月28日 21:25:28 标签: 人脸识别 / 人脸自动定位 / 人脸识别开源库 / f ...
- [深度学习工具]·极简安装Dlib人脸识别库
[深度学习工具]·极简安装Dlib人脸识别库 Dlib介绍 Dlib是一个现代化的C ++工具箱,其中包含用于在C ++中创建复杂软件以解决实际问题的机器学习算法和工具.它广泛应用于工业界和学术界,包 ...
- Tensorflow Mask-RCNN训练识别箱子的模型运行结果(练习)
Tensorflow Mask-RCNN训练识别箱子的模型
- winds dlib人脸检测与识别库
在人脸检测与人脸识别库中dlib库所谓是非常好的了.检测效果非常ok,下面我们来了解一下这个神奇的库吧! 第一步我们首先学会安装:dlib ,winds+pytho3.6.5 Windows不支持p ...
随机推荐
- Python3 中的Number
Python3 支持 int.float.bool.complex(复数). 在Python 3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long. 像大多数语言一样,数 ...
- linux 启动jar包 指定yml配置文件和输入日志文件
命令为: nohup java -jar project.jar --spring.config.location=/home/project-conf/application.yml > ...
- 检测服务器是否开启重协商功能(用于CVE-2011-1473漏洞检测)
背景 由于服务器端的重新密钥协商的开销至少是客户端的10倍,因此攻击者可利用这个过程向服务器发起拒绝服务攻击.OpenSSL 1.0.2及以前版本受影响. 方法 使用OpenSSL(linux系统基本 ...
- 千万级数据迁移工具DataX实践和geom类型扩展
## DataX快速入门参考 > 官方https://github.com/alibaba/DataX/blob/master/userGuid.md ## 环境要求 > Linux JD ...
- Spring 中的观察者模式
一.Spring 中观察者模式的四个角色 1. 事件(ApplicationEvent) ApplicationEvent 是所有事件对象的父类.ApplicationEvent 继承自 jdk 的 ...
- laravel5+ElasticSearch+go-mysql-elasticsearch MySQL数据实时导入(mac)
1. ElasticSearch安装 直接使用brew install elasticsearch 安装最新版本的es,基本没有障碍. 2.Laravel5 框架添加elasticsearch支持 在 ...
- mysql 读写分离(手动和自动方法)
使用sqlalchemy 使mysq自动读写分离: 代码如下: from flask import Flask from flask_sqlalchemy import SQLAlchemy, Sig ...
- java spring是元编程框架---使用的机制是注解+配置
java spring是元编程框架---使用的机制是注解+配置
- fsockopen反弹shell脚本
<?php error_reporting (E_ERROR); ignore_user_abort(true); ini_set('max_execution_time',0); $os = ...
- QT总结
作为一个QT(C++/linux/windows)开发工程师,把自己在工作中遇到的一些QT问题持续总结给大家,一起分享: 一.隐藏鼠标:QApplication::setOverrideCursor( ...