Flink 学习(一)
摘自Flink官网https://flink.apache.org/
最近看到公司有Flink平台,正好做过storm和spark streaming上的业务,借着这个机会把flink也学了。正好比较下他们之间的优缺点。
一、流式处理平台
1.Storm
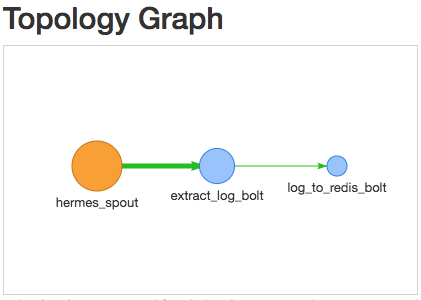
Topology为处理拓扑图
组成:
(1)Spout. 数据分发中心。
(2)Bolt. 数据处理中心
数据单元为Tuple。在Bolt处理完的数据可以发射给下一个Bolt。此时接收到的为Tuple。
缺点:
(1)消息传输保证为At least once. 但是可能出现重复发消息的情况。对每一条数据都做ack,所以容错的开销很大。
(2)延迟比flink大。
(3)吞吐量不如flink
(4)不支持批处理
2.Spark Streaming
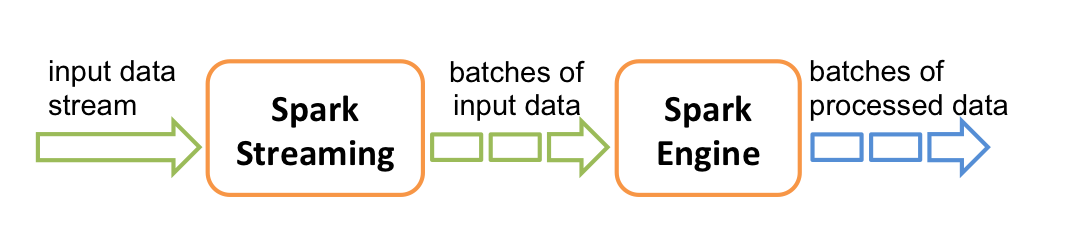
(1)比较主流的实时计算引擎。但是是居于micro batch处理,并不是纯正的流式处理。
(2)支持处理时间,Structured streaming 支持处理时间和事件时间,同时支持 watermark 机制处理滞后数据。
(3)与Hadoop家族组件交互良好,例如Hbase等。
(4)容错机制,checkpoint。
(5)Spark Streaming 跟 kafka 结合是存在背压机制的,目标是根据当前 job 的处理情况来调节后续批次的获取 kafka 消息的条数.
(6)数据单元是RDD,新增了Dstream.直接度kafka获得。
(7)处理过程大致是transformation和action。
3.Flink
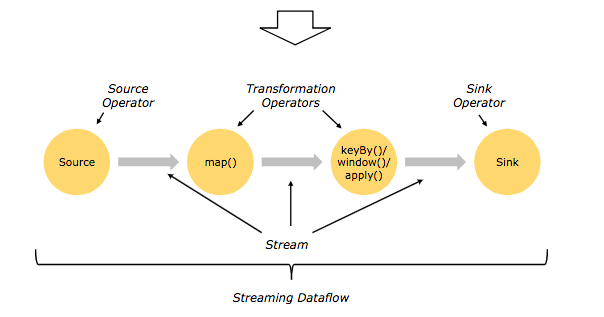
(1)数据形式DataStream(Streaming),DataSet(Batch)。
(2)处理过程是Source,Transformation 和 sink。
(3)时间。创建时间EventTime, 进入Flink DataFlow的时间。IngestionTime,对事件进行处理的本地系统时间Processing Time。
(4)窗口。按分割标准划分:timeWindow、countWindow。按窗口行为划分:Tumbling Window、Sliding Window、自定义窗口。
(5)轻量级容错机制。保证Execatly once执行。使用stream replay 和 checkpointing容错。
二、各个组件的介绍
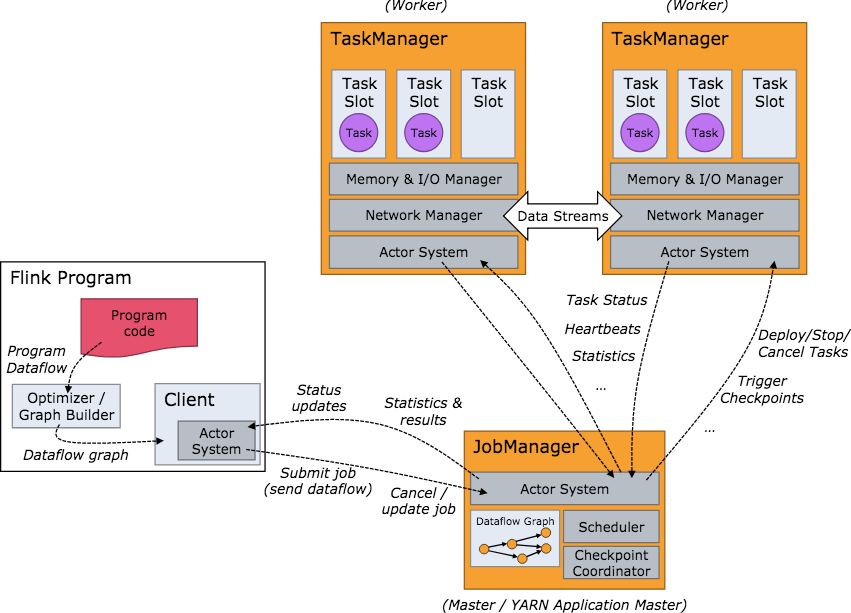
1.JobManager用来分配任务,也就是常说的master
2.TaskManager用来分发task,缓存和交换数据流
3.Slot,把TaskManager根据task把内存抽象很多个slot,用来执行task。
三、Mac系统下安装Flink
Mac下很方便,mac装东西确实是方便。------brew install apache-flink
四、启动
1.启动本地集群环境,很快就能启动起来。在/usr/local/Cellar/apache-flink/1.7.0/libexec目录下。
./bin/start-cluster.sh
2.然后在 http://localhost:8081/#/overview 就可以看见Flink的监控平台。

可以看到Task Managers是1个。Slots也是一个。
下面还有好几个选项,可以看到你的集群配置环境。
五、Example
WordCount
(1)Code分析
package flinkjob; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector; /**
* Created by adrian.wu on 2018/12/17.
*/
public class SocketWindowWordCount {
public static class WordWithCount { public String word;
public long count; public WordWithCount() {} public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
} @Override
public String toString() {
return word + " : " + count;
}
} public static void main(String[] args) throws Exception{
final int port;
try {
//得到提交时候的参数
final ParameterTool params = ParameterTool.fromArgs(args);
//得到端口号,因为这个例子是监听9000端口的例子
port = params.getInt("port");
} catch (Exception e) {
System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'");
return;
}
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //数据单元 DataStream
DataStream<String> text = env.socketTextStream("localhost", port, "\n");
DataStream<WordWithCount> windowCounts = text
.flatMap(new FlatMapFunction<String, WordWithCount>() { //map
@Override
public void flatMap(String value, Collector<WordWithCount> out) {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1)) //Window function, 5秒一个window,间隔1
.reduce(new ReduceFunction<WordWithCount>() {
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount b) { //reduce
return new WordWithCount(a.word, a.count + b.count);
}
});
windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount"); }
}
(2)打包提交代码
./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000 #提交job
nc -l 9000 #监听端口
tail -f log/flink-*-taskexecutor-*.out #查看log
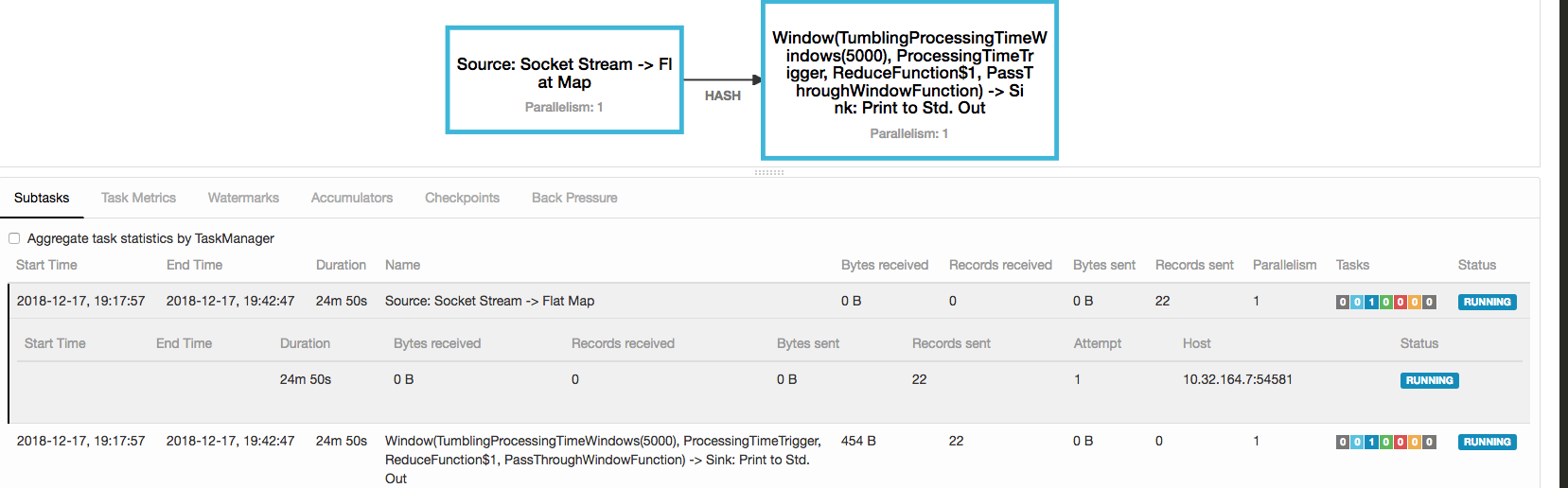
(3)在监控平台可以看到你的job情况
Flink 学习(一)的更多相关文章
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- 准备数据集用于flink学习
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Time的故事
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators之CoGroup及Join操作
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- Hello Object Oriented!
继计组之后,北航计算机学院又一大神课! 希望能以此为契机,和更多热爱技术的朋友们交流.让我们一起,共同进步~ [2019.4.27更新] 建立博客园的最初目的,是为了北航计算机学院OO课程设计的需要. ...
- 区块链使用Java,以太坊 Ethereum, web3j, Spring Boot
Blockchain is one of the buzzwords in IT world during some last months. This term is related to cryp ...
- js jquery 数组的合并 对象的合并
转载自:http://www.cnblogs.com/xingxiangyi/p/6416468.html 1 数组合并 1.1 concat 方法 1 2 3 4 var a=[1,2,3],b=[ ...
- 前端JS Excel解析导入
本文转载自:https://www.cnblogs.com/yinqingvip/p/6743213.html 需要用到js-xlsx:下载地址:js-xlsx <!DOCTYPE html&g ...
- 在 vue.js 中动态绑定 v-model
在最近的项目中(基于vue),有一个需求就是通过 v-for 动态生成 input.在正常情况下,页面中的input数量是固定的,而且每个input绑定的v-model也是固定的,我们可以在 data ...
- 【洛谷P1226 【模板】快速幂||取余运算】
题目描述 输入b,p,k的值,求b^p mod k的值.其中b,p,k*k为长整型数. 输入输出格式 输入格式: 三个整数b,p,k. 输出格式: 输出“b^p mod k=s” s为运算结果 作为初 ...
- ImageMagick: 6.8.3 升级到 6.8.9 遇到的问题
最终还是决定升级到目前最新版:6.8.9,不知何时才真正明白为什么现在都是java8,但还是有很多软件系统使用在java5上. 虽然新版本能带来各种好处,但现实中不能忽略一个问题:原来的代码很可能无法 ...
- Runtime.getRuntime().exec(...),当参数中有空格时!
原以为不会有什么问题,但在测试时发现,问题大了. 如果想调用f:\mp3\i love you.mp3时, 我原以为正确的写法是: //在文件名前后加个双引号来解决文件名中有空格的情况 String ...
- 跟我一起用node-express搭建一个小项目(mongodb)[二]
我的小项目主要是会用到MongoDB. 呵呵,我也是现学现卖. 都说小公司十八般武艺样样稀疏,没有办法啊! 兵来兵挡,将来将挡!自己是个兵呢?还是一个将呢! 没有公司培养,就自己培养自己呗.差的远一点 ...
- Druid 配置及内置监控,Web页面查看监控内容 【我改】
转: Druid 配置及内置监控,Web页面查看监控内容 1.配置Druid的内置监控 首先在Maven项目的pom.xml中引入包 1 2 3 4 5 <dependency> ...