Java的Fork/Join任务
当我们需要执行大量的小任务时,有经验的Java开发人员都会采用线程池来高效执行这些小任务。然而,有一种任务,例如,对超过1000万个元素的数组进行排序,这种任务本身可以并发执行,但如何拆解成小任务需要在任务执行的过程中动态拆分。这样,大任务可以拆成小任务,小任务还可以继续拆成更小的任务,最后把任务的结果汇总合并,得到最终结果,这种模型就是Fork/Join模型。
Java7引入了Fork/Join框架,我们通过RecursiveTask这个类就可以方便地实现Fork/Join模式。
例如,对一个大数组进行并行求和的RecursiveTask,就可以这样编写:
public class SumTask extends RecursiveTask<Long> {
static final int THRESHOLD = 100;
long[] array;
int start;
int end;
SumTask(long[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
if (end - start <= THRESHOLD) {
// 如果任务足够小,直接计算:
long sum = 0;
for (int i = start; i < end; i++) {
sum += array[i];
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
System.out.println(String.format("compute %d~%d = %d", start, end, sum));
return sum;
}
// 任务太大,一分为二:
int middle = (end + start) / 2;
System.out.println(String.format("split %d~%d ==> %d~%d, %d~%d", start, end, start, middle, middle, end));
SumTask subtask1 = new SumTask(this.array, start, middle);
SumTask subtask2 = new SumTask(this.array, middle, end);
invokeAll(subtask1, subtask2);
Long subresult1 = subtask1.join();
Long subresult2 = subtask2.join();
Long result = subresult1 + subresult2;
System.out.println("result = " + subresult1 + " + " + subresult2 + " ==> " + result);
return result;
}
public static void main(String[] args) {
// 创建随机数组成的数组:
long[] array = new long[400];
fillRandom(array);
// fork/join task:
ForkJoinPool fjp = new ForkJoinPool(4); // 最大并发数4
ForkJoinTask<Long> task = new SumTask(array, 0, array.length);
long startTime = System.currentTimeMillis();
Long result = fjp.invoke(task);
long endTime = System.currentTimeMillis();
System.out.println("Fork/join sum: " + result + " in " + (endTime - startTime) + " ms.");
}
private static void fillRandom(long[] array) {
for(int i=0; i<array.length; i++){
Random random = new Random();
int i1 = random.nextInt(10);
array[i] = i1;
}
}
}
编写这个Fork/Join任务的关键在于,在执行任务的compute()方法内部,先判断任务是不是足够小,如果足够小,就直接计算并返回结果(注意模拟了1秒延时),否则,把自身任务一拆为二,分别计算两个子任务,再返回两个子任务的结果之和。
main方法中的关键代码是fjp.invoke(task)来提交一个Fork/Join任务并发执行,然后获得异步执行的结果。
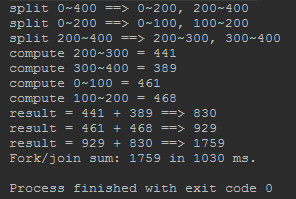
我们设置任务的最小阀值是100,当提交一个400大小的任务时,在4核CPU上执行,会一分为二,再二分为四,每个最小子任务的执行时间是1秒,由于是并发4个子任务执行,整个任务最终执行时间大约为1秒。
新手在编写Fork/Join任务时,往往用搜索引擎搜到一个例子,然后就照着例子写出了下面的代码:
protected Long compute() {
if (任务足够小?) {
return computeDirect();
}
// 任务太大,一分为二:
SumTask subtask1 = new SumTask(...);
SumTask subtask2 = new SumTask(...);
// 分别对子任务调用fork():
subtask1.fork();
subtask2.fork();
// 合并结果:
Long subresult1 = subtask1.join();
Long subresult2 = subtask2.join();
return subresult1 + subresult2;
}
很遗憾,这种写法是错!误!的!这样写没有正确理解Fork/Join模型的任务执行逻辑。
JDK用来执行Fork/Join任务的工作线程池大小等于CPU核心数。在一个4核CPU上,最多可以同时执行4个子任务。对400个元素的数组求和,执行时间应该为1秒。但是,换成上面的代码,执行时间却是两秒。
这是因为执行compute()方法的线程本身也是一个Worker线程,当对两个子任务调用fork()时,这个Worker线程就会把任务分配给另外两个Worker,但是它自己却停下来等待不干活了!这样就白白浪费了Fork/Join线程池中的一个Worker线程,导致了4个子任务至少需要7个线程才能并发执行。
打个比方,假设一个酒店有400个房间,一共有4名清洁工,每个工人每天可以打扫100个房间,这样,4个工人满负荷工作时,400个房间全部打扫完正好需要1天。
Fork/Join的工作模式就像这样:首先,工人甲被分配了400个房间的任务,他一看任务太多了自己一个人不行,所以先把400个房间拆成两个200,然后叫来乙,把其中一个200分给乙。
紧接着,甲和乙再发现200也是个大任务,于是甲继续把200分成两个100,并把其中一个100分给丙,类似的,乙会把其中一个100分给丁,这样,最终4个人每人分到100个房间,并发执行正好是1天。
如果换一种写法:
// 分别对子任务调用fork():
subtask1.fork();
subtask2.fork();
这个任务就分!错!了!
比如甲把400分成两个200后,这种写法相当于甲把一个200分给乙,把另一个200分给丙,然后,甲成了监工,不干活,等乙和丙干完了他直接汇报工作。乙和丙在把200分拆成两个100的过程中,他俩又成了监工,这样,本来只需要4个工人的活,现在需要7个工人才能1天内完成,其中有3个是不干活的。
其实,我们查看JDK的invokeAll()方法的源码就可以发现,invokeAll的N个任务中,其中N-1个任务会使用fork()交给其它线程执行,但是,它还会留一个任务自己执行,这样,就充分利用了线程池,保证没有空闲的不干活的线程。
Java的Fork/Join任务的更多相关文章
- Java 7 Fork/Join 框架
在 Java7引入的诸多新特性中,Fork/Join 框架无疑是重要的一项.JSR166旨在标准化一个实质上可扩展的框架,以将并行计算的通用工具类组织成一个类似java.util中Collection ...
- Java Concurrency - Fork/Join Framework
Normally, when you implement a simple, concurrent Java application, you implement some Runnable obje ...
- Java 7 Fork/Join 并行计算框架概览
应用程序并行计算遇到的问题 当硬件处理能力不能按摩尔定律垂直发展的时候,选择了水平发展.多核处理器已广泛应用,未来处理器的核心数将进一步发布,甚至达到上百上千的数量.而现在 很多的应用程序在运行在多核 ...
- Java并发——Fork/Join框架
为了防止无良网站的爬虫抓取文章,特此标识,转载请注明文章出处.LaplaceDemon/ShiJiaqi. http://www.cnblogs.com/shijiaqi1066/p/4631466. ...
- Java并发——Fork/Join框架与ForkJoinPool
为了防止无良网站的爬虫抓取文章,特此标识,转载请注明文章出处.LaplaceDemon/ShiJiaqi. http://www.cnblogs.com/shijiaqi1066/p/4631466. ...
- Java的Fork/Join任务,你写对了吗?
当我们需要执行大量的小任务时,有经验的Java开发人员都会采用线程池来高效执行这些小任务.然而,有一种任务,例如,对超过1000万个元素的数组进行排序,这种任务本身可以并发执行,但如何拆解成小任务需要 ...
- Java使用Fork/Join框架来并行执行任务
现代的计算机已经向多CPU方向发展,即使是普通的PC,甚至现在的智能手机.多核处理器已被广泛应用.在未来,处理器的核心数将会发展的越来越多. 虽然硬件上的多核CPU已经十分成熟,但是很多应用程序并未这 ...
- Java通过Fork/Join来优化并行计算
Java代码: package Threads; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.Recur ...
- 我的Java开发学习之旅------>Java使用Fork/Join框架来并行执行任务
现代的计算机已经向多CPU方向发展,即使是普通的PC,甚至现在的智能手机.多核处理器已被广泛应用.在未来,处理器的核心数将会发展的越来越多. 虽然硬件上的多核CPU已经十分成熟,但是很多应用程序并未这 ...
随机推荐
- Vue(基础七)_webpack使用工具(下)
一.前言 1.webpack.config文件配置 2.webpack打包css文件 ...
- phpmyadmin拿webshell
思路:就是利用mysql的一个日志文件.这个日志文件每执行一个sql语句就会将其执行的保存.我们将这个日志文件重命名为我们的shell.php然后执行一条sql带一句话木马的命令.然后执行菜刀连接之! ...
- bzoj3991 LCA + set
https://www.lydsy.com/JudgeOnline/problem.php?id=3991 小B最近正在玩一个寻宝游戏,这个游戏的地图中有N个村庄和N-1条道路,并且任何两个村庄之间有 ...
- 在linux下面解压用的zxpf是什么意思,它跟zxvf有啥区别
在linux下面解压用的zxpf是什么意思,它跟zxvf有啥区别 linux 命令中tar后跟的zxvf是什么意思:.tar.gz是一个压缩包 .tar只是打包而没有压缩 z:表示 tar 包是被 ...
- 2017-12-14python全栈9期第一天第三节之python历史
python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言 ...
- flume常见异常汇总以及解决方案
flume常见异常汇总以及解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 实际生产环境中,我用flume将kafka的数据定期的往hdfs集群中上传数据,也遇到过一系列的坑 ...
- MySql笔记一:安装MySql
MySql第一次安装之后,一定会报错,我遇到了十几种不同的错误,搜来搜去也没有搜出个结果.于是我重新卸载了MySql,卸载干净之后,下载MSI格式的MySql安装包,安装完之后,还是报错,如下图... ...
- MY服务器架设
研究了一天,终于弄出来了,进游戏耍了会,感觉不错,下面分享架设步骤给大家 分享端的大大也出了个虚拟机运行需要注意的视频,大家看看吧,我就这样弄架设成功了 链接:链接: http://pan.baidu ...
- C#下RSA算法的实现(适用于支付宝和易宝支付)
RSA算法代码: using System; using System.Collections.Generic; using System.Text; using System.IO; using S ...
- 微信小程序,错误{"errMsg":"request:fail 小程序要求的 TLS 版本必须大于等于 1.2"}
解决方法一: 开发环境,项目--->勾选不校验即可 解决办法二: 在 PowerShell中运行以下内容, 然后重启服务器 # Enables TLS R2 and Windows # Thes ...