python机器学习-sklearn挖掘乳腺癌细胞(三)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制,包含catboost实战代码)
网易云观看地址
乳腺癌细胞和正常细胞是有显著区别的
癌细胞半径更大,形状更加不规则,凹凸不平。我们可以用科学手段来区分正常细胞和癌细胞吗?答案是可以的,通过机器学习算法,建立分类器,解决二分类问题。

乳腺癌细胞分类器建模
现在我们要用机器学习算法建立分类器,区分细胞为良性细胞或癌细胞。分类器就是解决二分类或多分类问题。
建立分类器算法很多,包括逻辑回归,xgboost,svm,神经网络等等。
今天我要介绍目前开源领域里最新的算法catboost。
catboost起源于俄罗斯搜索巨头yandex,准确率高,速度快,调参少,性价比高于xgboost
今天的CatBoost版本是第一个版本,以后将持续更新迭代。catboost三个特点:(1)“减少过度拟合”:这可以帮助你在训练计划中取得更好的成果。它基于一种构建模型的专有算法,这种算法与标准的梯度提升方案不同。(2)“类别特征支持”:这将改善你的训练结果,同时允许你使用非数字因素,“而不必预先处理数据,或花费时间和精力将其转化为数字。”(3)支持Python或R的API接口来使用CatBoost,包括公式分析和训练可视化工具。(4)有很多机器学习库的代码质量比较差,需要做大量的调优工作,”他说,“而CatBoost只需少量调试,就可以实现良好的性能。这是一个关键性的区别
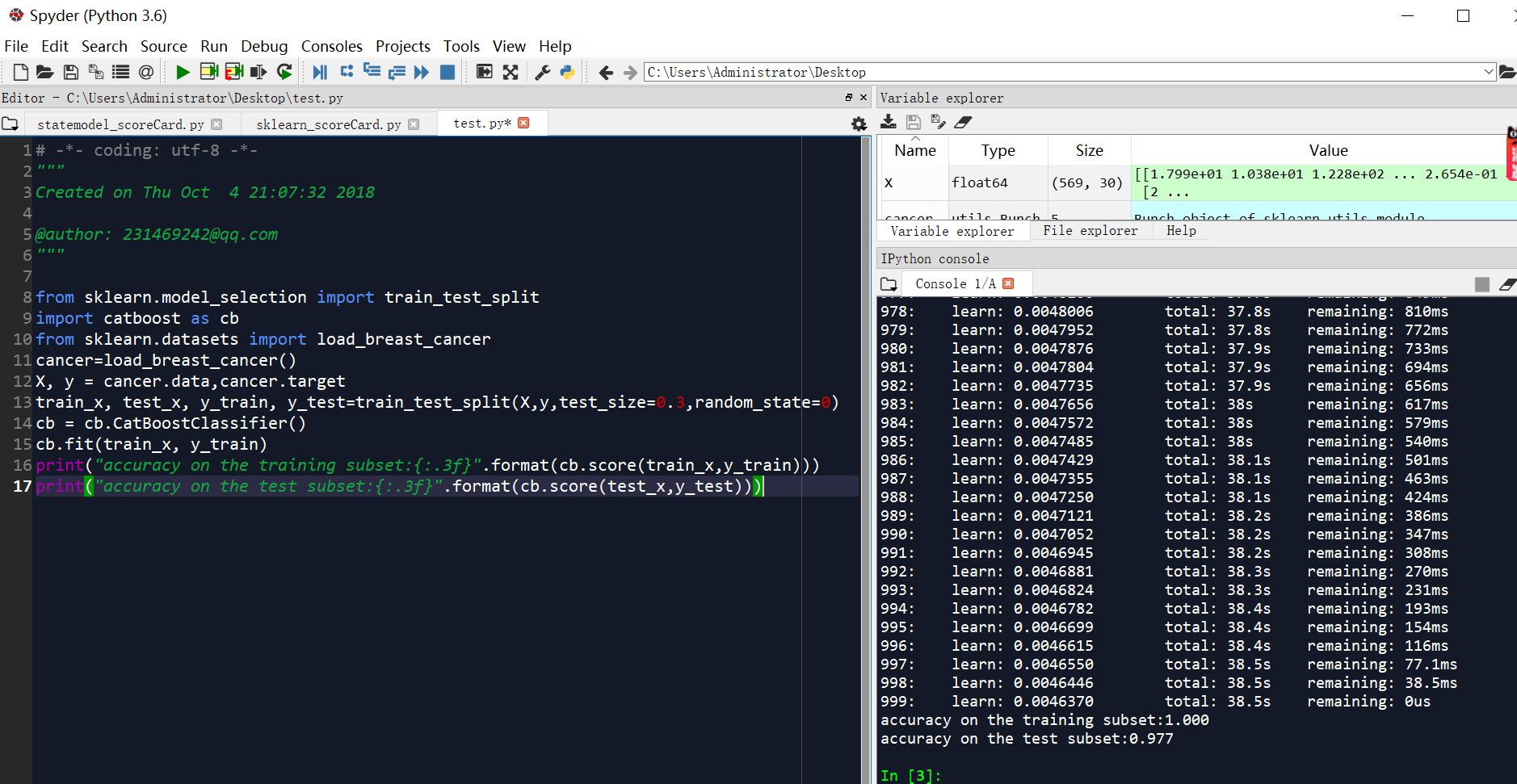
catboost建立乳腺癌分类器代码
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 4 21:07:32 2018 @author: 231469242@qq.com
""" from sklearn.model_selection import train_test_split
import catboost as cb
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
X, y = cancer.data,cancer.target
train_x, test_x, y_train, y_test=train_test_split(X,y,test_size=0.3,random_state=0)
cb = cb.CatBoostClassifier()
cb.fit(train_x, y_train)
print("accuracy on the training subset:{:.3f}".format(cb.score(train_x,y_train)))
print("accuracy on the test subset:{:.3f}".format(cb.score(test_x,y_test)))
大家可以看到catboost预测准确率非常高,训练集100%,测试集97.7%
https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149( 欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章)

机器学习项目合作QQ:231469242
python机器学习-sklearn挖掘乳腺癌细胞(三)的更多相关文章
- python机器学习-sklearn挖掘乳腺癌细胞(五)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- python机器学习-sklearn挖掘乳腺癌细胞(四)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- python机器学习-sklearn挖掘乳腺癌细胞(二)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- python机器学习-sklearn挖掘乳腺癌细胞(一)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- python机器学习sklearn 岭回归(Ridge、RidgeCV)
1.介绍 Ridge 回归通过对系数的大小施加惩罚来解决 普通最小二乘法 的一些问题. 岭系数最小化的是带罚项的残差平方和, 其中,α≥0α≥0 是控制系数收缩量的复杂性参数: αα 的值越大,收缩量 ...
- 机器学习Sklearn系列:(三)决策树
决策树 熵的定义 如果一个随机变量X的可能取值为X={x1,x2,..,xk},其概率分布为P(X=x)=pi(i=1,2,...,n),则随机变量X的熵定义为\(H(x) = -\sum{p(x)l ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- python机器学习实战(三)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7277205.html 前言 这篇notebook是关于机器 ...
- Python机器学习库sklearn的安装
Python机器学习库sklearn的安装 scikit-learn是Python的一个开源机器学习模块,它建立在NumPy,SciPy和matplotlib模块之上能够为用户提供各种机器学习算法接口 ...
随机推荐
- poj2739(尺取法+质数筛)
题意:给你一个数,问这个数能否等于一系列连续的质数的和: 解题思路:质数筛打出质数表:然后就是尺取法解决: 代码: #include<iostream> #include<algor ...
- sql练习题及经典题
https://blog.csdn.net/mrbcy/article/details/68965271 经典例题 19.查询选修“3-105”课程的成绩高于“109”号同学成绩的所有同学的记录. S ...
- github-share报错无法读取远程仓库
报错:github Could not read from remote repository 1.github创建仓库成功,而push报告此错误 2.考虑远程仓库名与本地项目名/文件夹名不匹配 3. ...
- HDU5773-The All-purpose Zero-多校#41010-最长上升子序列问题
只想到了朴素的n^2做法,然后发现可以用splay维护.于是调了几个小时的splay... splay的元素是从第二个开始的!第一个是之前插入的头节点! #include <cstdio> ...
- BZOJ1012 最大数maxnumber
单调栈的妙处!! 刚看到这题差点写个splay..但是后来看到询问范围的只是后L个数,因为当有一个数新进来且大于之前的数时,那之前的数全都没有用了,满足这种性质的序列可用单调栈维护 栈维护下标(因为要 ...
- appium 原理解析(转载雷子老师博客)
appium 原理解析 原博客地址:https://www.cnblogs.com/leiziv5/p/6427609.html Appium是 c/s模式的appium是基于 webdriver 协 ...
- sublime3添加verilog自动补全代码段
前言 sublime默认的verilog自动补全十分垃圾,不过提供了代码段这个功能,你可以自己写个重用率高的代码段减轻工作量.写个模板当tb也很爽啦. 流程 1.打开user文件夹,创建verilog ...
- 反射中Class.forName()和classLoader的区别
搞清楚两者之间区别前,我们来了解下类加载过程. 一.类加载过程 1.加载 通过一个类的全限定名来获取定义此类的二进制字节流. 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构. 在内存中生 ...
- luogu1608 路径统计 (spfa)
题意:给一个有向图(无零边),要求找出最短路的数量(重边只计算一次) 做spfa的时候,记一个cnt对于u-w->v如果dis[u]+w=dis[v],cnt[v]+=cnt[u] 如果dis[ ...
- [WC2005]双面棋盘(并查集+分治)
题目描述 题解 唉,还是码力不行,写了一个多小时发现想错了又重构了一个多小时. 这道题意图很显然,动态维护联通块,有一个经典做法就是用LCT维护按照删除时间维护的最大生成树. 网上还有一种神奇的做法, ...