ASCII、Unicode、UTF-8以及Python3编码问题
编码问题,其实的确是个很烦人的问题,一开始觉得不需要看,到后来出现问题,真的是抓狂,
而像我们这些刚刚涉及到这些问题的小白来说,更是无从下手,所以查阅资料,总结理解下各个概念以及Python3的编码问题。
ASCII码
首先,我们大概都理解的是目前我们所见到的文本都是计算机处理过显示出来的,实际上计算机只能存储的是数字,要处理文本,就必须将文本与数字进行转换处理。而我们都知道,在计算机中,8个计算机能识别的0/1位(bit)组成了了一个字节(byte),而一个字节即可表示255个数字,提供255个不同的标识。
最早的时候计算机是美国发明的,而自然而然的他们将127个大小写字母、数字以及一些基本符号一一编号,也就形成了我们最为熟知的ASCII码,
|
00110000
|
60
|
48
|
30
|
0
|
数字0 |
|
00110001
|
61
|
49
|
31
|
1
|
数字1 |
|
00110010
|
62
|
50
|
32
|
2
|
数字2 |
|
00110011
|
63
|
51
|
33
|
3
|
数字3 |
Unicode
那么很明显的,随着计算机的普及,这仅仅的127个字符甚至255个字符肯定也无法满足大家的需求了,比如我们中文,那么就有了Unicode。
Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
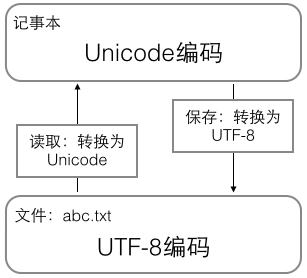
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码
Python的编码问题
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:

>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'
如果知道字符的整数编码,还可以用十六进制这么写str
'\u4e2d\u6587' // 中文
byte
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
要计算str包含多少个字符,可以用len()函数
>>> len('ABC')
3
>>> len('中文')
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
格式化:
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
format % (...params)
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,%x表示16进制整数,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
>>> '%2d-%02d' % (3, 1)
' 3-01'
>>> '%.2f' % 3.1415926
'3.14'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'
ASCII、Unicode、UTF-8以及Python3编码问题的更多相关文章
- ASCII UNICODE UTF "口水文"
最近接了一个单是需要把非 UTF-8 (No BOM)编码的文件转换成 UTF-8 (No BOM),若此文件是 UTF-8 但带有 BOM ,需要转换成不带 BOM 的.于是开启了一天的阅读.首先花 ...
- ascii、unicode、utf、gb等编码详解
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们看到8个开关状态是好的,于是他们把这称为"字节".再后来,他们又做了一些可以处理这 ...
- 【转】【编码】ANSI,ASCII,Unicode,UTF8之一
不同的国家和地区制定了不同的标准,由此产生了 GB2312.GBK.GB18030.Big5.Shift_JIS 等各自的编码标准.这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称 ...
- ASCII,unicode, utf8 ,big5 ,gb2312,gbk,gb18030等几种常用编码区别(转载)
原文出处:http://www.blogjava.net/xcp/archive/2009/10/29/coding2.html 最近老为编码问题而烦燥,下定决心一定要将其弄明白!本文主要总结网上一些 ...
- ASCII、Unicode、UTF-8 字符串和编码
字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特 ...
- 字符编码 ASCII,Unicode和UTF-8的关系
转自:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143166410626 ...
- 字符编码 ASCII unicode UTF-8
字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(b ...
- 35 编码 ASCII Unicode UTF-8 ,字符串的编码、io流的编码
* 编码表: * 信息在计算机上是用二进制表示的,这种表示法让人理解就很困难.为保证人类和设备,设备和计算机之间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表 *ASCII ...
- python3编码问题
继续收集python3编码问题相关资料 资料来源 鹏程的新浪博客(转载)http://blog.sina.com.cn/s/blog_6d7cf9e50102vo90.html 这篇鹏程老师写的关 ...
随机推荐
- FileProvider的使用及应用更新时提示:解析包出错、失败等问题
Android 7.0以上的版本更新采用系统自带的DownloadManager更新 DOWNLOADPATH ="/download/" https://www.jianshu. ...
- CHROME浏览器清缓存
- 使用WebClient调用第三方接口
需要调用一个第三方接口,传参返回数据 本来是很简单的一个需求,搞了一天没整好 首先在POSTMAN中测试没有问题,但是使用jquery ajax在前台就会涉及到跨域 虽然设置了 无论怎么写都会报错 C ...
- ucos中需要注意的全局变量
首先聊一聊全局变量: 在慕课上学习浙大老师的C语言课程的时候,翁恺老师一直在强调在程序中我们要避免使用全局变量,C语言的程序员(尤其像我这样的野生程序员)为了方便,经常会不顾这个编码规范.全局变量有一 ...
- Python Selenium系列学习
以下记录刚接触Python Selenium操作Web UI的学习问题: 1.python selenium三种等待方式: ①强制等待:time.sleep(value):设置等待最简单的方法就是强制 ...
- 20175126《Java程序设计》第三学习总结
# 20175126 2016-2017-2 <Java程序设计>第三周学习总结 ##课余收获——利用JAVA编写最简单的斗地主程序 -由于最近身边的朋友都在玩手机上的斗地主小游戏,我也就 ...
- Ubuntu 16.04 安装Kinect V2驱动
1.下载源代码 git clone https://github.com/OpenKinect/libfreenect2.git 2.依赖项安装 sudo apt-get install build- ...
- 记录下本地修改php版本的过程, 本地PHP目录位置,PHP-FPM目录位置
由于我在Cellar下安装了多个PHP版本,所以这里记录下如何修改本地的PHP版本 cd /usr/local/bin cp php71 php cp php71-fpm php-fpm vscode ...
- WebService关于Unable to find required classes (javax.activation.DataHandler and javax.mail.internet.MimeMultipart)问题解决
错误原因:需要mail.jar和activation.jar. Solution:Web Services Required Jars Download Instructions http://www ...
- 51单片机学习笔记(清翔版)(13)——LED点阵、74HC595
如图3,点阵屏分单色和彩色,点阵屏是由许多点组成的,在一个点上,只有一颗一种颜色的灯珠,这就是单色点阵屏,彩色的在一个点上有三颗灯珠,分别是RGB三原色. 图4你可能没看出来,那么大块黄色的就是点阵屏 ...