ETL hive update 之 deltamerge 优化
- full join 横向join ,不能map join 走shuffle
- row_number() over ( partition by 主键 order by $flag desc) rank ... where rank =1 ,走shufle
select
id,
order_datekey,
f_procurement_order,
from
(
select
id,
order_datekey,
f_procurement_order,
row_number() over (
partition by id
order by
b_flag_i desc
) rank
from
(
select
id,
order_datekey,
f_procurement_order,
0 b_flag_i
from
ods_pms_procurement_order_item_hm old
WHERE
c_t >= 1479916800
or u_t >= 1479916800
union all
select
id,
order_datekey,
f_procurement_order,
1 b_flag_i
from
ods_pms_procurement_order_item_hm_delta_64124FEADBFA9720 new
) t
) st
where
rank = 1;
- 差集 + 并集方式 效率最高 前提是增量数据较少,要不也要走shuffle
# semi_1 数据 id , name
1 jx
2 gj
# semi_2数据id, age
1 28
3 30
select a.id,a.name from semi_1 a left anti join semi_2 b on a.id = b.id;
left anti join 是以左表为主,如果join上就返回null,否则返回左表数据。
2 gj
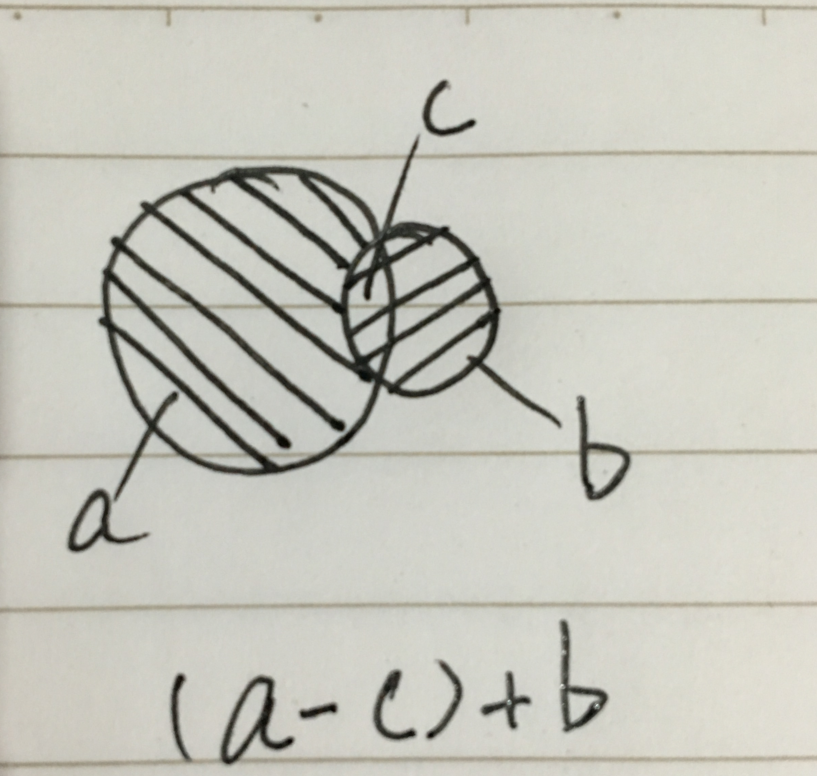
下图a代表完整old 全集,b代表完整new全集,c代表a与b join 上的交集部分(比如id相等的部分)所以思路就是(a-c)+b实现hive 的update
SET hive.mapred.mode=nonstrict;
INSERT overwrite TABLE $target.table
SELECT
$stream.format
FROM
$target.table old left anti
join ($delta) new on $stream.unique_keys
UNION ALL
SELECT
$stream.format
FROM
$target.table ;
fields = 'id,name'
new = 'new'
old = 'old'
and_str = ' AND '
cmd = []
for field in fields.split(','):
str = old + '.' + field + ' = ' + new + '.' + field
cmd.append(str)
print and_str.join(cmd)
ETL hive update 之 deltamerge 优化的更多相关文章
- 写好Hive 程序的若干优化技巧和实际案例
使用Hive可以高效而又快速地编写复杂的MapReduce查询逻辑.但是一个”好”的Hive程序需要对Hive运行机制有深入的了解,像理解mapreduce作业一样理解Hive QL才能写出正确.高效 ...
- Hive性能分析和优化方法
Hive性能分析和优化方法 http://wenku.baidu.com/link?url=LVrnj-mD0OB69-eUH-0b2LGzc2SN76hjLVsGfCdYjV8ogyyN-BSja5 ...
- Hive使用Calcite CBO优化流程及SQL优化实战
目录 Hive SQL执行流程 Hive debug简单介绍 Hive SQL执行流程 Hive 使用Calcite优化 Hive Calcite优化流程 Hive Calcite使用细则 Hive向 ...
- hive中与hbase外部表join时内存溢出(hive处理mapjoin的优化器机制)
与hbase外部表(wizad_mdm_main)进行join出现问题: CREATE TABLE wizad_mdm_dev_lmj_edition_result as select * from ...
- hive查询注意及优化tips
Hive是将符合SQL语法的字符串解析生成可以在Hadoop上执行的MapReduce的工具.使用Hive尽量按照分布式计算的一些特点来设计sql,和传统关系型数据库有区别, 所以需要去掉原有关系型数 ...
- HIVE的几种优化
5 WAYS TO MAKE YOUR HIVE QUERIES RUN FASTER 今天看了一篇[文章] (http://zh.hortonworks.com/blog/5-ways-make-h ...
- hive 总结四(优化)
本文参考:黑泽君相关博客 本文是我总结日常工作中遇到的坑,结合黑泽君相关博客,选取.补充了部分内容. 表的优化 小表join大表.大表join小表 将key相对分散,并且数据量小的表放在join的左边 ...
- hive中笛卡尔积的优化
由于一个业务,必须要进行笛卡尔积,但是速度太慢了,left join时左表大概4万条数据,右表大概 3000多条数据,这样大概就是一亿多条数据, 这在大数据领域其实不算很大的数据量,但是hive中跑的 ...
- Hive参数层面常用优化
1.hive数据仓库权限问题: set hive.warehouse.subdir.inherit.perms=true; 2.HiveServer2的内存 连接的个数越多压力越大,可以加大内存:可以 ...
随机推荐
- 2018-2019-2 20165313 《网络对抗技术》Exp4 恶意代码分析
一.实践目标 1.监控你自己系统的运行状态,看有没有可疑的程序在运行. 2.分析一个恶意软件,就分析Exp2或Exp3中生成后门软件:分析工具尽量使用原生指令或sysinternals,systrac ...
- linux下禁用网卡的启用网卡的一些方法
第一种方法: 这种方法主要是在不重启的情况下会一直生效,适用于服务器. #禁用网卡eth0 sudo ifconfig eth0 down #启用网卡eth0 sudo ifconfig eth0 u ...
- JS制作图片切换
<!DOCTYPE html> <html> <head> <title>纯JS制作简单的图片切换</title> <meta cha ...
- .Net 一开始就不应该搞 .Net Core
.Net 一开始就不应该搞 .Net Core, java 跨平台 是 java 选择的道路, .Net 应该发挥 和 平台 紧密结合 的 优势 . 如 控件哥 所说, 微软 应该把 IIS ...
- 一台电脑支持2个git账号:gitlab+github
一.背景 1.公司使用gitlab保存代码,git已支持. 2.需要新增一个人github账户.创建study项目并提交到github上. 3.git提交时互相不混淆 二.操作流程 1.注册githu ...
- Linux基础入门-Linux下软件安装
一.在线安装: sudo apt-get install 即可安装 如果在安装完后无法用Tab键补全命令,可以执行: source ~/.zshrc APT(Advanced Packaging To ...
- react super() and super(props)
subclass: subclass is a class that extends another class. 即子类. In ES2015, to use 'this' in subclasse ...
- jdk1.8源码解析(1):HashMap源码解析
jdk1.8 HashMap数据结构 图1-HashMap类图 图2-TreeNode类图 由图1-HashMap类图可知HashMap底层数据结构是由一个Node<K,V>的数组构成.具 ...
- UITableView自定义Cell中,纯代码编程动态获取高度
在UITableView获取高度的代理方法中,经常需要根据实际的模型重新计算每个Cell的高度.直接的做法是在该代理方法中,直接根据模型来返回行高:另 [1]-(CGFloat)tableView:( ...
- Spark环境准备
Ubuntu: 1.下载spark-2.2.1-bin-hadoop2.7.tgz,解压即可使用. 2.下载jdk-8u151-linux-x64.tar.gz,解压. 3.执行spark-2.2.1 ...