Spark源码解析 - Spark-shell浅析
1.准备工作
1.1 安装spark,并配置spark-env.sh
使用spark-shell前需要安装spark,详情可以参考http://www.cnblogs.com/swordfall/p/7903678.html
如果只用一个节点,可以不用配置slaves文件,spark-env.sh文件只需配置为master_ip和local_ip两个属性
spark-env.sh添加如下配置:
export SPARK_MASTER_IP=hadoop1
export SPARK_LOCAL_IP=hadoop1
注意:hadoop1是这台虚拟机的ip地址,或者用127.0.0.1代替hadoop1也行。spark-shell浅析是基于spark-2.2.0-bin-hadoop2.7版本进行的。
1.2 启动spark-shell
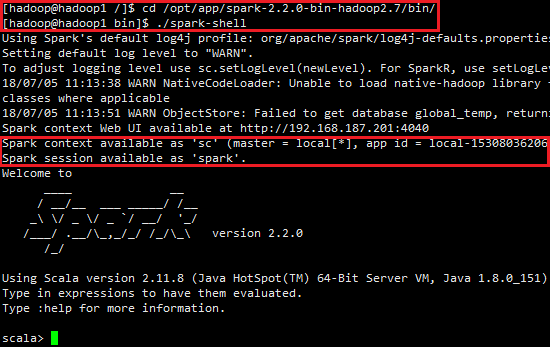
输入spark安装目录的bin下,执行spark-shell命令
cd /opt/app/spark-2.2.0-bin-hadoop2.7/bin/
./spark-shell
最后我们会看到spark启动的过程,如图所示:
2. 执行word count 范例
通过word count例子来感受下spark任务的执行过程,启动spark-shell后,会打开scala命令行,然后按照以下步骤输入脚本。
1) 输入val lines = sc.textFile("../README.md", 2)

2) 输入val words = lines.flatMap(line => line.split(" "))

3) 输入val ones = words.map(w => (w, 1))

4) 输入val counts = ones.reduceByKey(_ + _)
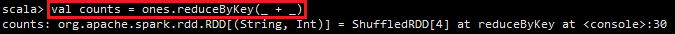
5) 输入counts.foreach(println)

3. 剖析spark-shell
通过word count在spark-shell中执行的过程,看看spark-shell做了什么。spark-shell中有以下一段脚本
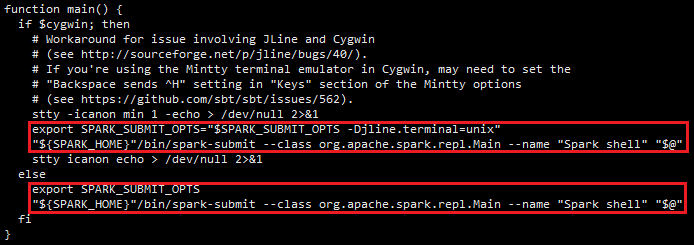
我们看到脚本spark-shell里执行了spark-submit脚本,打开spark-submit脚本,发现其中包含以下脚本:
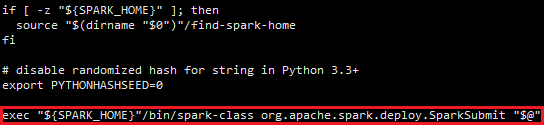
脚本spark-submit在执行spark-class脚本时,给它增加了参数SparkSubmit。打开spark-class脚本,其中包含以下脚本:


读到这里,可知spark-class里面首先加载spark-env.sh里面的配置属性,然后获取jdk的java命令,接着拿到spark_home的jars目录。至此,Spark启动了以SparkSubmit为主类的jvm进程。
为便于在本地对Spark进程使用远程监控,给SPARK_HOME目录conf/spark-defaults.conf配置文件追加以下jmx配置:
#driver端监控
spark.driver.extraJavaOptions=-XX:+UnlockCommercialFeatures -XX:+FlightRecorder -Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port= -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false #executor端监控,暂时注释
#spark.executor.extraJavaOptions=-XX:+UnlockCommercialFeatures -XX:+FlightRecorder -Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port= -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
注意:使用远程监控前,如果spark-shell在运行中需要先停止,配置好监控参数,再需要运行spark-shell命令,否则jvisualvm找不到该线程。上面的两条命令都是一行的,不是两行,两行会导致jvisualvm连接不上,报“无法使用 service:jmx:rmi:///jndi/rmi://192.168.187.201:8009/jmxrmi 连接到 192.168.187.201:8009”错误。
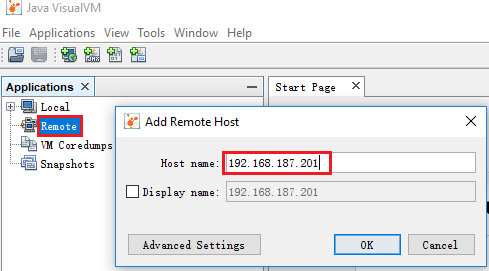
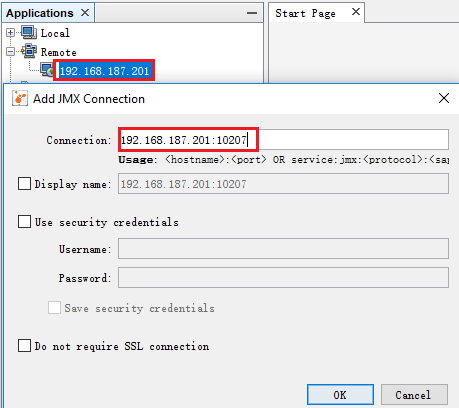
在本地JAVA_HOME/bin目录下打开jvisualvm,添加远程主机,如图;右击已添加的远程主机,添加JMX连接,如图:
单击右侧的“线程”选项卡,选择main线程,然后单击“线程Dump”按钮,如图:
从dump的内容中找到线程main的信息,如图:
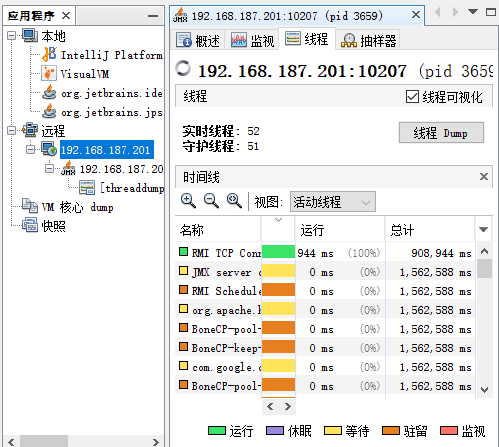
main线程dump信息

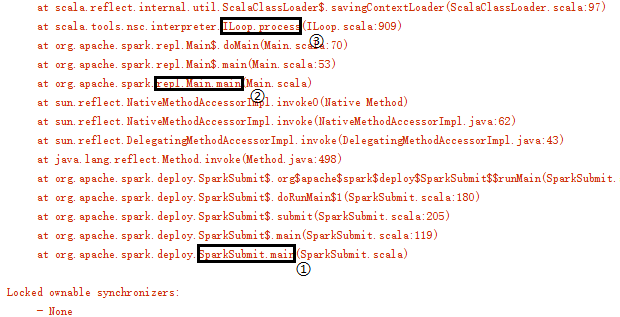
从main线程的栈信息中可以看出程序的调用顺序:SparkSubmit.main -> repl.Main -> ILoop.process。org.apache.spark.repl.SparkILoop类继承ILoop类,ILoop的process方法调用SparkILoop的loadFiles(settings)与printWelcome()方法。SparkILoop的loadFiles(settings)方法中又调用了自身的initializeSpark方法,initializeSpark的实现如下:

initializationCommands是一个命令集合,见代码:
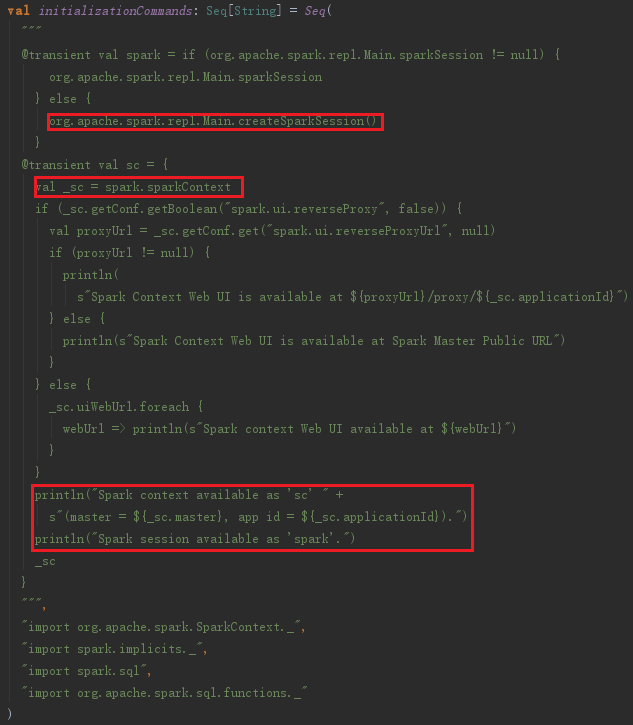
从代码中可以看到,命令集合中会调用org.apache.spark.repl.Main的createSparkSession()方法创建或者获取sparkSession类,如图:
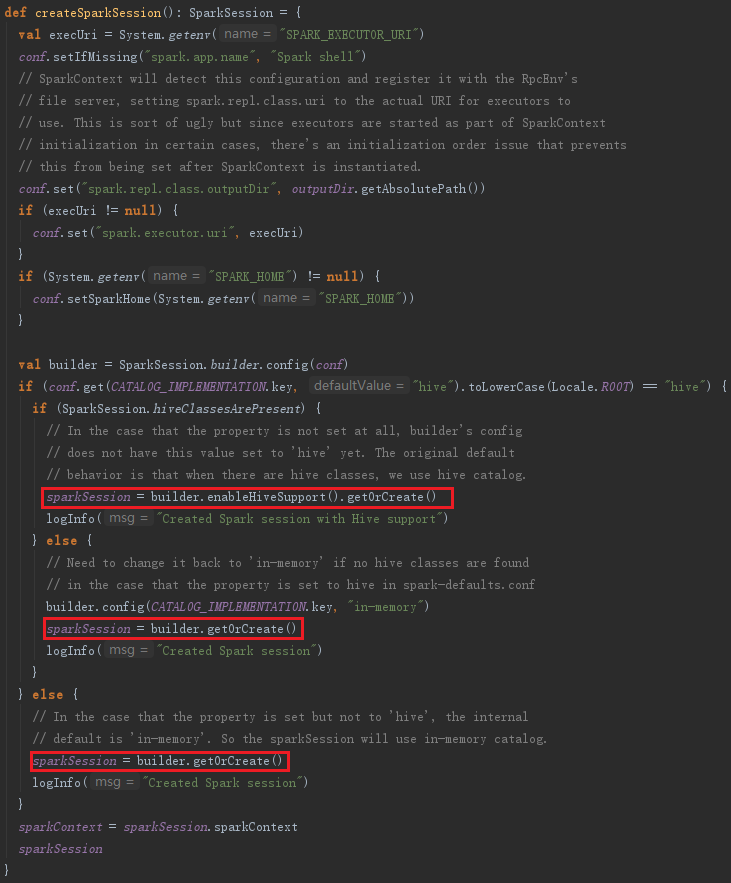
从上述代码可以看到builder是SparkSession里面的属性,IDEA工具使用“ctrl+鼠标点击”操作,可以进入到builder.getOrCreate()方法里面查看SparkSession如何创建,如图:
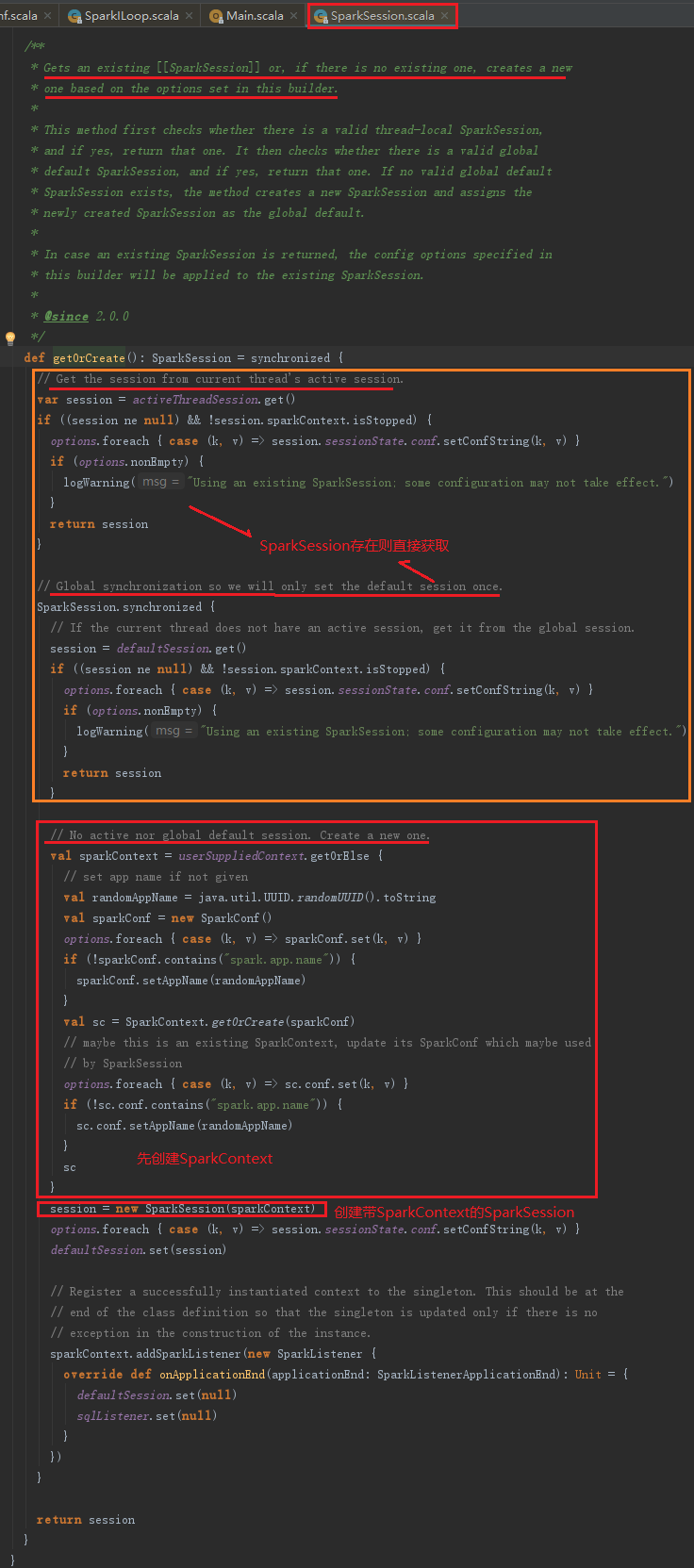
从上述代码可以看到SparkContext首先创建,再创建SparkSession。SparkContext的创建代码如下:
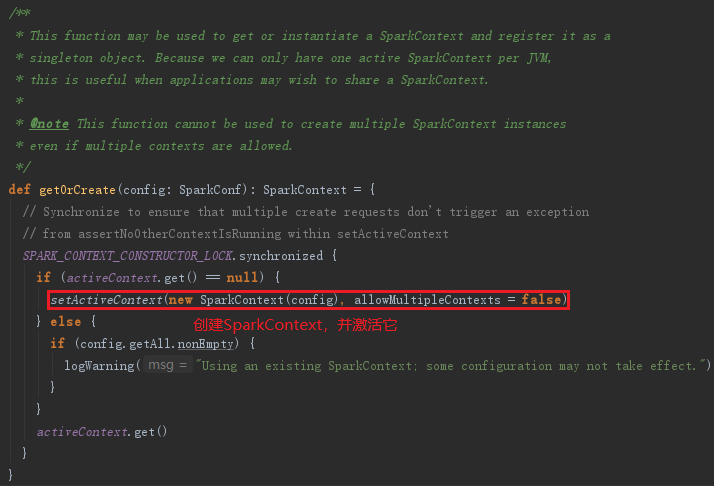
这里使用SparkConf、SparkContext和SparkSession来完成初始化,代码分析中涉及的repl主要用于与Spark实时交互。
4.Spark-shell的整体流程
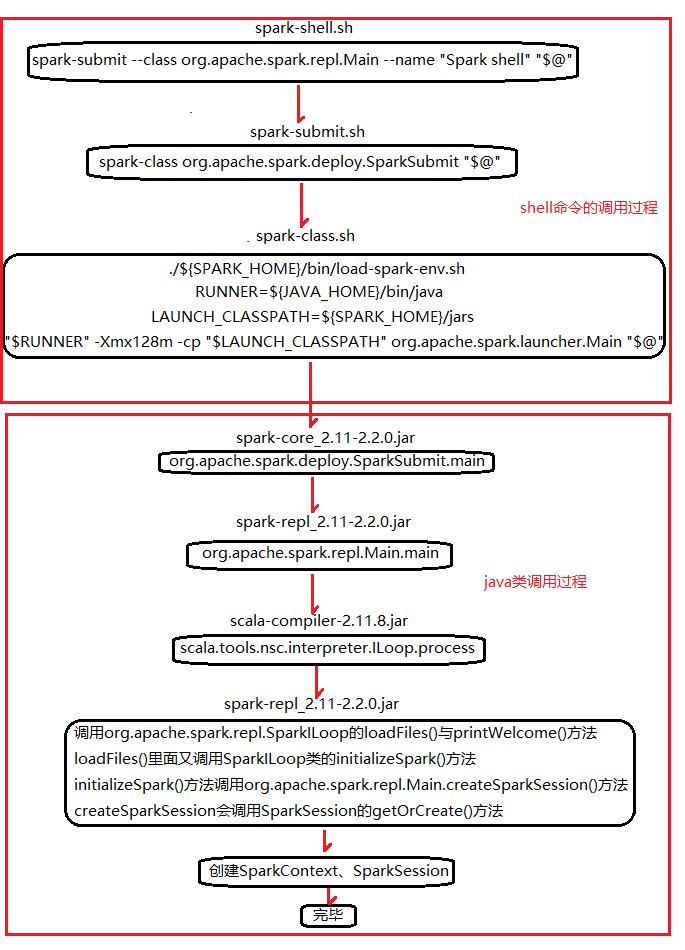
至此,Spark-shell解析完毕。
参考资料:
《深入理解Spark核心思想与源码分析》
https://www.iteblog.com/archives/1349.html 使用jvisualvm监控Spark作业
Spark源码解析 - Spark-shell浅析的更多相关文章
- Spark 源码解析:TaskScheduler的任务提交和task最佳位置算法
上篇文章< Spark 源码解析 : DAGScheduler中的DAG划分与提交 >介绍了DAGScheduler的Stage划分算法. 本文继续分析Stage被封装成TaskSet, ...
- Spark 源码解析 : DAGScheduler中的DAG划分与提交
一.Spark 运行架构 Spark 运行架构如下图: 各个RDD之间存在着依赖关系,这些依赖关系形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG,进行Stage划分,划分的规 ...
- Scala实战高手****第4课:零基础彻底实战Scala控制结构及Spark源码解析
1.环境搭建 基础环境配置 jdk+idea+maven+scala2.11.以上工具安装配置此处不再赘述. 2.源码导入 官网下载spark源码后解压到合适的项目目录下,打开idea,File-&g ...
- spark源码解析大全
第1章 Spark 整体概述 1.1 整体概念 Apache Spark 是一个开源的通用集群计算系统,它提供了 High-level 编程 API,支持 Scala.Java 和 Pytho ...
- Scala实战高手****第7课:零基础实战Scala面向对象编程及Spark源码解析
/** * 如果有这些语法的支持,我们说这门语言是支持面向对象的语言 * 其实真正面向对象的精髓是不是封装.继承.多态呢? * --->肯定不是,封装.继承.多态,只不过是支撑面向对象的 * 一 ...
- spark源码解析之基本概念
从两方面来阐述spark的组件,一个是宏观上,一个是微观上. 1. spark组件 要分析spark的源码,首先要了解spark是如何工作的.spark的组件: 了解其工作过程先要了解基本概念 官方罗 ...
- spark源码解析之scala基本语法
1. scala初识 spark由scala编写,要解析scala,首先要对scala有基本的了解. 1.1 class vs object A class is a blueprint for ob ...
- spark源码解析总结
========== Spark 通信架构 ========== 1.spark 一开始使用 akka 作为网络通信框架,spark 2.X 版本以后完全抛弃 akka,而使用 netty 作为新的网 ...
- Scala实战高手****第6课 :零基础实战Scala集合操作及Spark源码解析
本课内容1.Spark中Scala集合操作鉴赏2.Scala集合操作实战 --------------------------------------------------------------- ...
随机推荐
- php+redis配置
系统环境: win10+phpstudy+lamp 安装扩展 php5.6.4 =>下载地址:http://windows.php.net/downloads/pecl/releases/red ...
- PHP 事务写法
$md=new Model(); //创建事务 $md->startTrans(); //开始事务 $md->table("ym_xxx")->where(&qu ...
- 安装 linux-dash
先看看软件的效果图,再介绍安装方法. 通过上图可以看到.软件可以实时监控CPU.内存.网络流量等相关信息,甚至可以监控到硬件信息安装方法:yum -y install httpd php zip un ...
- [USACO08DEC]在农场万圣节Trick or Treat on the Farm【Tarja缩点+dfs】
题目描述 每年,在威斯康星州,奶牛们都会穿上衣服,收集农夫约翰在N(1<=N<=100,000)个牛棚隔间中留下的糖果,以此来庆祝美国秋天的万圣节. 由于牛棚不太大,FJ通过指定奶牛必须遵 ...
- angular与vue的应用对比
因为各种笔试面试,最近都没时间做一些值得分享的东西,正好复习一下vue技术栈,与angular做一下对比. angular1就跟vue比略low了. 1.数据绑定 ng1 ng-bind,{{ sco ...
- java 数组转字符串 字符串转数组
字符串转数组 使用Java split() 方法 split() 方法根据匹配给定的正则表达式来拆分字符串. 注意: . . | 和 * 等转义字符,必须得加 \\.多个分隔符,可以用 | 作为连字符 ...
- 【洛谷P4318】完全平方数
题目大意:求第 K 个无平方因子数. 题解:第 k 小/大的问题一般采用二分的方式,通过判定从 1 到当前数中满足某一条件的数有多少个来进行对上下边界的转移. 考虑莫比乌斯函数的定义,根据函数值将整数 ...
- 【洛谷P4145】花神游历各国
题目大意:给定一个长度为 N 的序列,支持区间开根,区间求和. 题解:对于区间开根操作,可以发现任何一个位置的值开根至多 6 次就会变成 1.因此即使是整个区间开根,暴力修改6次后,所有的点的权值均小 ...
- Django 子程序
在Web应用中,通常有一些业务功能模块是在不同的项目中都可以复用的,故在开发中通常将工程项目拆分为不同的子功能模块,各功能模块间可以保持相对的独立,在其他工程项目中需要用到某个特定功能模块时,可以将该 ...
- SetCapture() & ReleaseCapture() 捕获窗口外的【松开左键事件】: WM_LBUTTONUP
今天在窗口上绘图的时候,遇到一个问题:在特殊情况下,当用户在窗口中按下鼠标左键,然后移动到窗口外松开鼠标左键,这时程序中只能捕获到 WM_LBUTTONDOWN(按下) 和 WM_MOUSEMOVE( ...