Spark源码解析 - Spark-shell浅析
1.准备工作
1.1 安装spark,并配置spark-env.sh
使用spark-shell前需要安装spark,详情可以参考http://www.cnblogs.com/swordfall/p/7903678.html
如果只用一个节点,可以不用配置slaves文件,spark-env.sh文件只需配置为master_ip和local_ip两个属性
spark-env.sh添加如下配置:
export SPARK_MASTER_IP=hadoop1
export SPARK_LOCAL_IP=hadoop1
注意:hadoop1是这台虚拟机的ip地址,或者用127.0.0.1代替hadoop1也行。spark-shell浅析是基于spark-2.2.0-bin-hadoop2.7版本进行的。
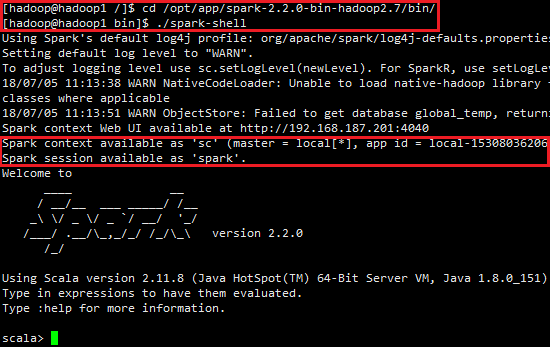
1.2 启动spark-shell
输入spark安装目录的bin下,执行spark-shell命令
cd /opt/app/spark-2.2.0-bin-hadoop2.7/bin/
./spark-shell
最后我们会看到spark启动的过程,如图所示:
2. 执行word count 范例
通过word count例子来感受下spark任务的执行过程,启动spark-shell后,会打开scala命令行,然后按照以下步骤输入脚本。
1) 输入val lines = sc.textFile("../README.md", 2)

2) 输入val words = lines.flatMap(line => line.split(" "))

3) 输入val ones = words.map(w => (w, 1))

4) 输入val counts = ones.reduceByKey(_ + _)
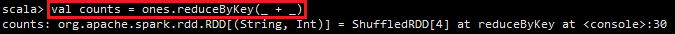
5) 输入counts.foreach(println)

3. 剖析spark-shell
通过word count在spark-shell中执行的过程,看看spark-shell做了什么。spark-shell中有以下一段脚本
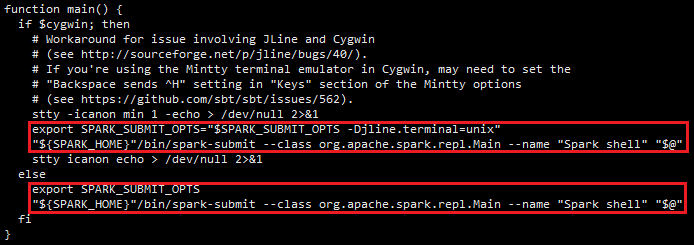
我们看到脚本spark-shell里执行了spark-submit脚本,打开spark-submit脚本,发现其中包含以下脚本:
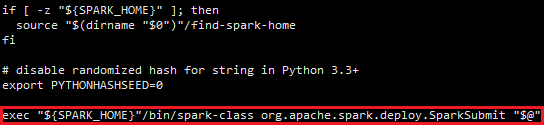
脚本spark-submit在执行spark-class脚本时,给它增加了参数SparkSubmit。打开spark-class脚本,其中包含以下脚本:


读到这里,可知spark-class里面首先加载spark-env.sh里面的配置属性,然后获取jdk的java命令,接着拿到spark_home的jars目录。至此,Spark启动了以SparkSubmit为主类的jvm进程。
为便于在本地对Spark进程使用远程监控,给SPARK_HOME目录conf/spark-defaults.conf配置文件追加以下jmx配置:
#driver端监控
spark.driver.extraJavaOptions=-XX:+UnlockCommercialFeatures -XX:+FlightRecorder -Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port= -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false #executor端监控,暂时注释
#spark.executor.extraJavaOptions=-XX:+UnlockCommercialFeatures -XX:+FlightRecorder -Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port= -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
注意:使用远程监控前,如果spark-shell在运行中需要先停止,配置好监控参数,再需要运行spark-shell命令,否则jvisualvm找不到该线程。上面的两条命令都是一行的,不是两行,两行会导致jvisualvm连接不上,报“无法使用 service:jmx:rmi:///jndi/rmi://192.168.187.201:8009/jmxrmi 连接到 192.168.187.201:8009”错误。
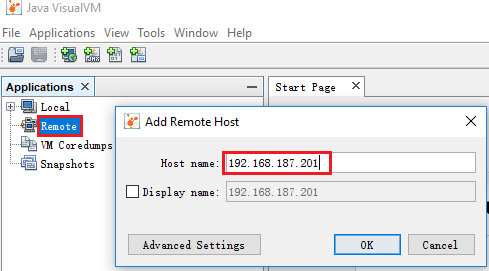
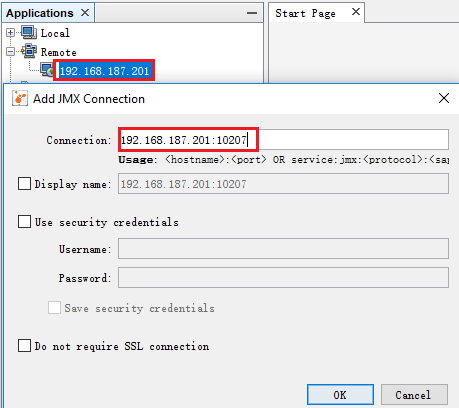
在本地JAVA_HOME/bin目录下打开jvisualvm,添加远程主机,如图;右击已添加的远程主机,添加JMX连接,如图:
单击右侧的“线程”选项卡,选择main线程,然后单击“线程Dump”按钮,如图:
从dump的内容中找到线程main的信息,如图:
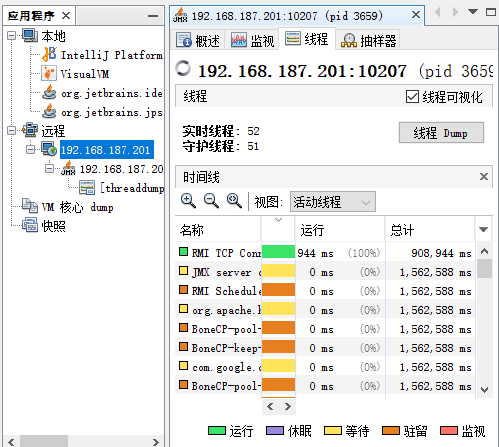
main线程dump信息

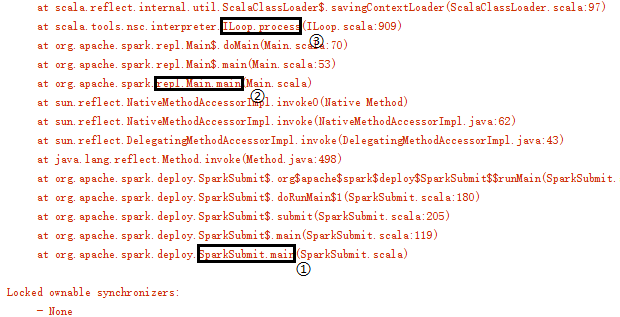
从main线程的栈信息中可以看出程序的调用顺序:SparkSubmit.main -> repl.Main -> ILoop.process。org.apache.spark.repl.SparkILoop类继承ILoop类,ILoop的process方法调用SparkILoop的loadFiles(settings)与printWelcome()方法。SparkILoop的loadFiles(settings)方法中又调用了自身的initializeSpark方法,initializeSpark的实现如下:

initializationCommands是一个命令集合,见代码:
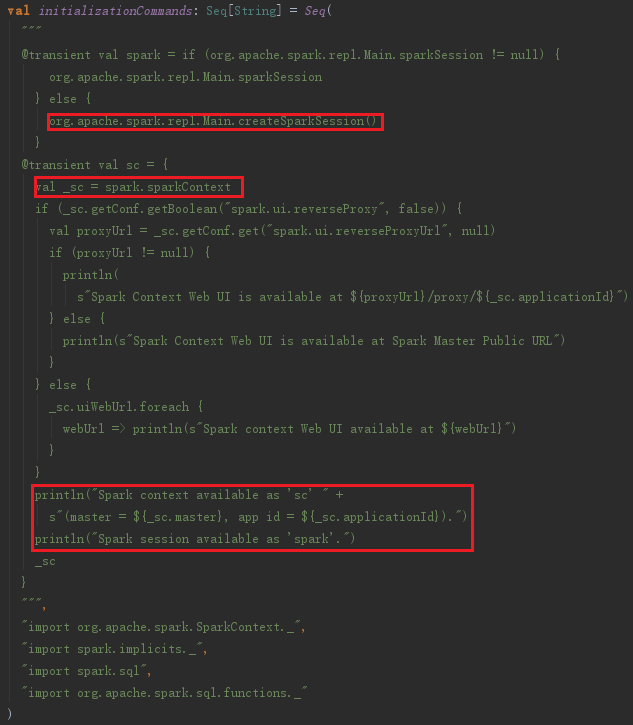
从代码中可以看到,命令集合中会调用org.apache.spark.repl.Main的createSparkSession()方法创建或者获取sparkSession类,如图:
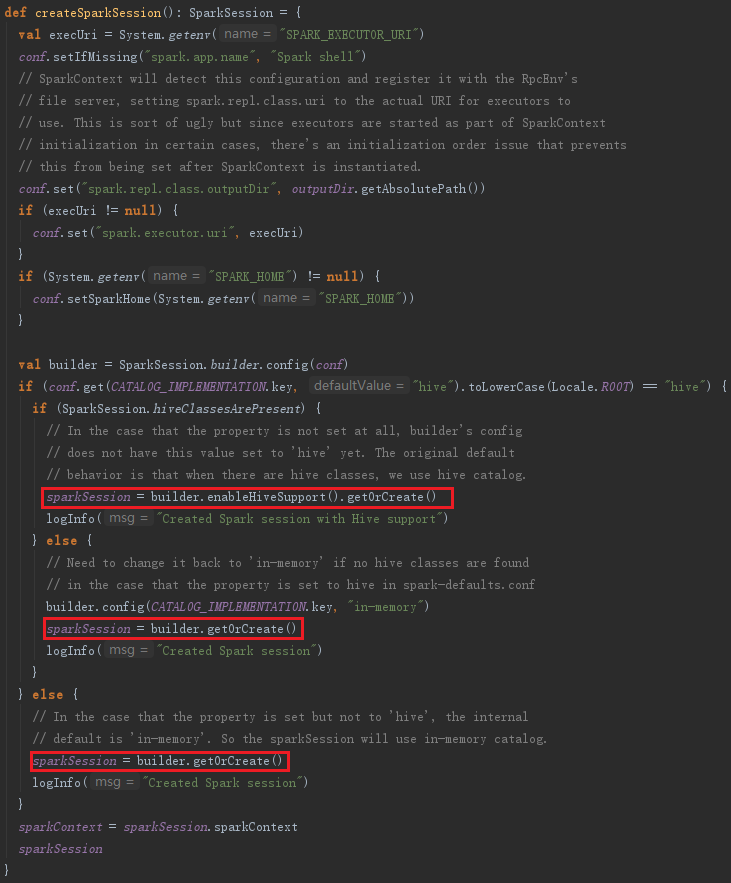
从上述代码可以看到builder是SparkSession里面的属性,IDEA工具使用“ctrl+鼠标点击”操作,可以进入到builder.getOrCreate()方法里面查看SparkSession如何创建,如图:
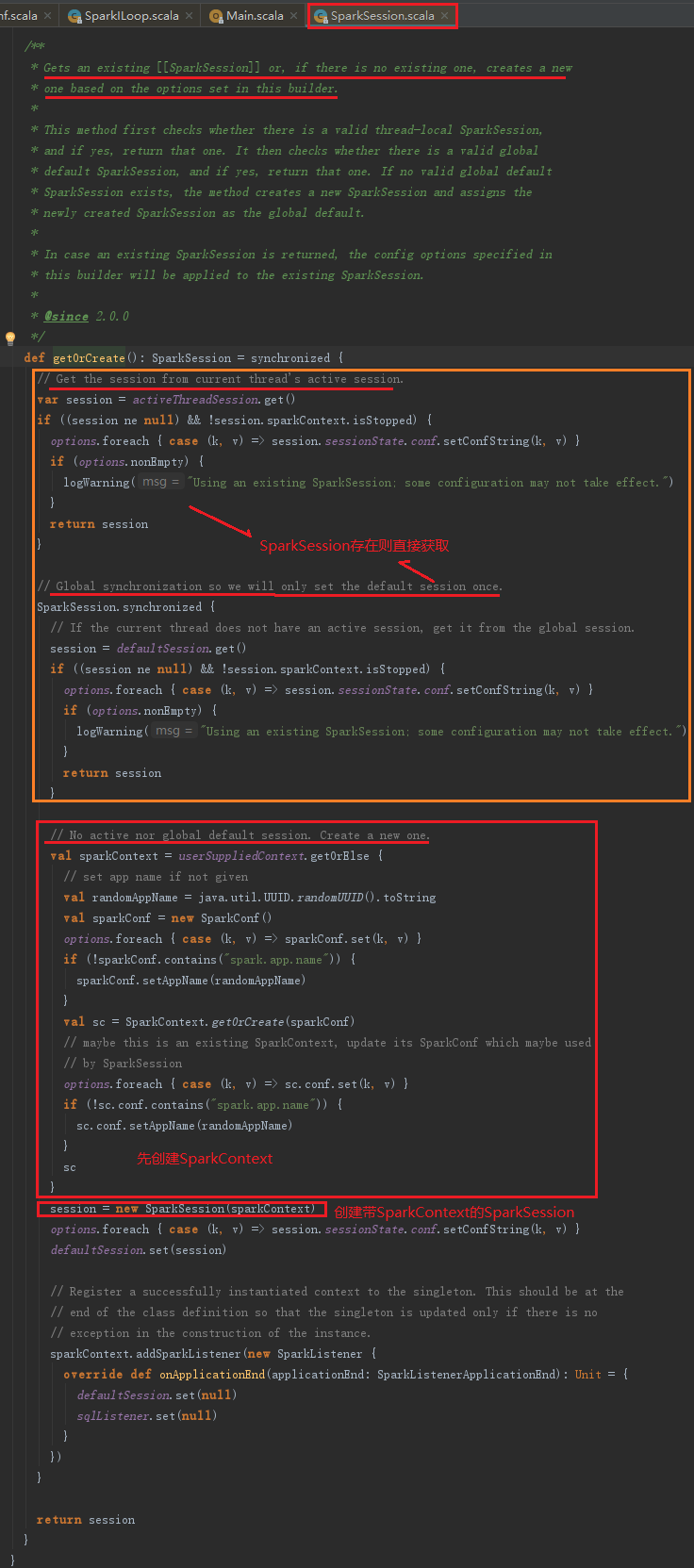
从上述代码可以看到SparkContext首先创建,再创建SparkSession。SparkContext的创建代码如下:
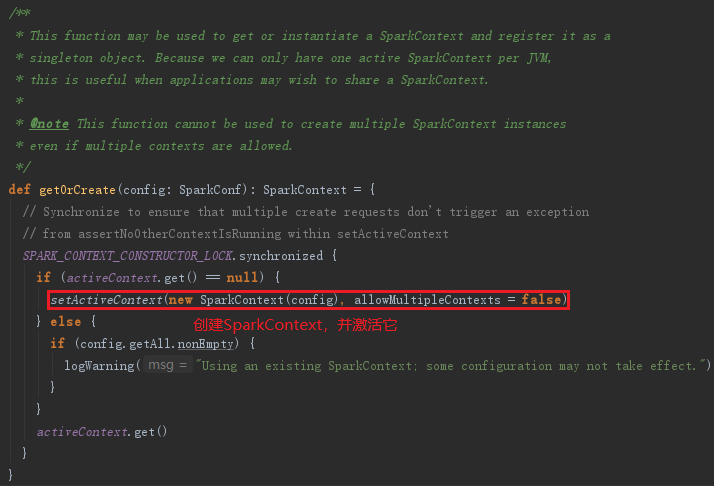
这里使用SparkConf、SparkContext和SparkSession来完成初始化,代码分析中涉及的repl主要用于与Spark实时交互。
4.Spark-shell的整体流程
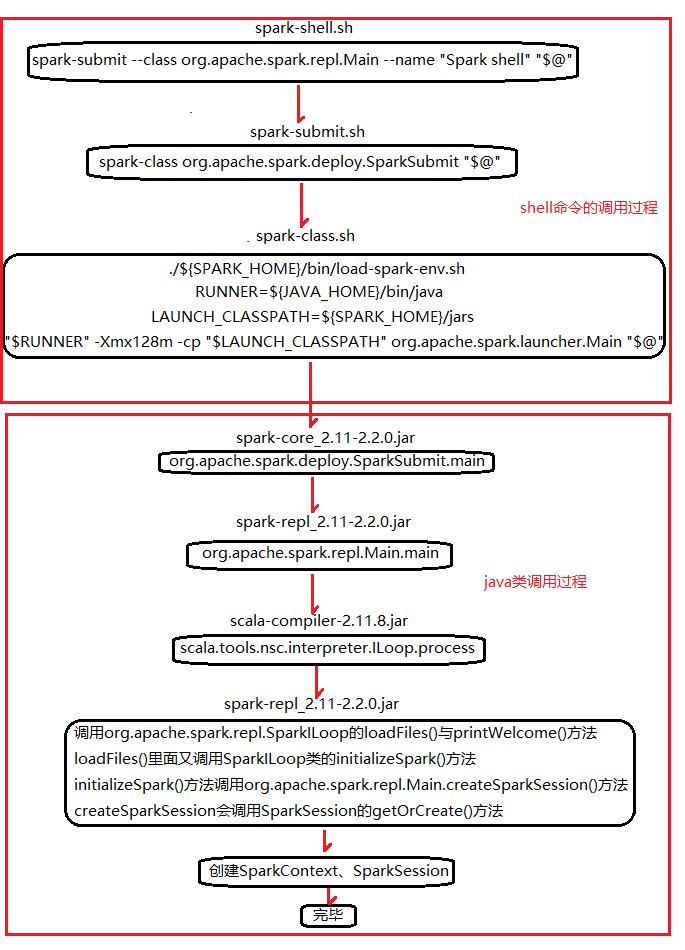
至此,Spark-shell解析完毕。
参考资料:
《深入理解Spark核心思想与源码分析》
https://www.iteblog.com/archives/1349.html 使用jvisualvm监控Spark作业
Spark源码解析 - Spark-shell浅析的更多相关文章
- Spark 源码解析:TaskScheduler的任务提交和task最佳位置算法
上篇文章< Spark 源码解析 : DAGScheduler中的DAG划分与提交 >介绍了DAGScheduler的Stage划分算法. 本文继续分析Stage被封装成TaskSet, ...
- Spark 源码解析 : DAGScheduler中的DAG划分与提交
一.Spark 运行架构 Spark 运行架构如下图: 各个RDD之间存在着依赖关系,这些依赖关系形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG,进行Stage划分,划分的规 ...
- Scala实战高手****第4课:零基础彻底实战Scala控制结构及Spark源码解析
1.环境搭建 基础环境配置 jdk+idea+maven+scala2.11.以上工具安装配置此处不再赘述. 2.源码导入 官网下载spark源码后解压到合适的项目目录下,打开idea,File-&g ...
- spark源码解析大全
第1章 Spark 整体概述 1.1 整体概念 Apache Spark 是一个开源的通用集群计算系统,它提供了 High-level 编程 API,支持 Scala.Java 和 Pytho ...
- Scala实战高手****第7课:零基础实战Scala面向对象编程及Spark源码解析
/** * 如果有这些语法的支持,我们说这门语言是支持面向对象的语言 * 其实真正面向对象的精髓是不是封装.继承.多态呢? * --->肯定不是,封装.继承.多态,只不过是支撑面向对象的 * 一 ...
- spark源码解析之基本概念
从两方面来阐述spark的组件,一个是宏观上,一个是微观上. 1. spark组件 要分析spark的源码,首先要了解spark是如何工作的.spark的组件: 了解其工作过程先要了解基本概念 官方罗 ...
- spark源码解析之scala基本语法
1. scala初识 spark由scala编写,要解析scala,首先要对scala有基本的了解. 1.1 class vs object A class is a blueprint for ob ...
- spark源码解析总结
========== Spark 通信架构 ========== 1.spark 一开始使用 akka 作为网络通信框架,spark 2.X 版本以后完全抛弃 akka,而使用 netty 作为新的网 ...
- Scala实战高手****第6课 :零基础实战Scala集合操作及Spark源码解析
本课内容1.Spark中Scala集合操作鉴赏2.Scala集合操作实战 --------------------------------------------------------------- ...
随机推荐
- NEW —— Code
http://ai.baidu.com/ 百度AI开放平台
- BZOJ 5097: [Lydsy1711月赛]实时导航(最短路 + bitset)
题意 \(n\) 个点的有向图,边权 \(\in \{1, 2, 3, 4\}\) ,\(m\) 次修改边权/加边/删边,\(q\) 次询问:以 \(s_i\) 为起点,输出它到其他点的最短 ...
- 【BZOJ5471】[FJOI2018]邮递员问题(动态规划)
[BZOJ5471][FJOI2018]邮递员问题(动态规划) 题面 BZOJ 洛谷 给定平面上若干个点,保证这些点在两条平行线上,给定起点终点,求从起点出发,遍历所有点后到达终点的最短路径长度. 题 ...
- [luogu1341]无序字母对【欧拉回路】
题目描述 给定n个各不相同的无序字母对(区分大小写,无序即字母对中的两个字母可以位置颠倒).请构造一个有n+1个字母的字符串使得每个字母对都在这个字符串中出现. 分析 欧拉回路的模板题. 暴力删边欧拉 ...
- HR_Two Strings
https://www.hackerrank.com/challenges/two-strings/problem?h_l=interview&playlist_slugs%5B%5D=int ...
- Codeforces Round #487 (Div. 2) C - A Mist of Florescence
C - A Mist of Florescence 把50*50的矩形拆成4块 #include<bits/stdc++.h> using namespace std; ],b[]; ][ ...
- [CTSC2018]暴力写挂——边分树合并
[CTSC2018]暴力写挂 题面不错 给定两棵树,两点“距离”定义为:二者深度相加,减去两棵树上的LCA的深度(深度指到根节点的距离) 求最大的距离. 解决多棵树的问题就是降维了. 经典的做法是边分 ...
- python之设计模式
一.简介 设计模式的定义:为了解决面向对象系统中重要和重复的设计封装在一起的一种代码实现框架,可以使得代码更加易于扩展和调用 四个基本要素:模式名称,问题,解决方案,效果 六大原则: 1.开闭原则:一 ...
- 第十二节、尺度不变特征(SIFT)
上一节中,我们介绍了Harris角点检测.角点在图像旋转的情况下也可以检测到,但是如果减小(或者增加)图像的大小,可能会丢失图像的某些部分,甚至导致检测到的角点发生改变.这样的损失现象需要一种与图像比 ...
- 第十六节,使用函数封装库tf.contrib.layers
这一节,介绍TensorFlow中的一个封装好的高级库,里面有前面讲过的很多函数的高级封装,使用这个高级库来开发程序将会提高效率. 我们改写第十三节的程序,卷积函数我们使用tf.contrib.lay ...