2、 Spark Streaming方式从socket中获取数据进行简单单词统计
Spark 1.5.2 Spark Streaming 学习笔记和编程练习
Overview 概述
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.
Spark Streaming 是核心Spark API的一个扩展,其处理实时流数据具有可扩展性、高吞吐量,容错性。数据可以通过多种源加载进来,如Kafka, Flume, Twitter, ZeroMQ, Kinesis, or TCP sockets;并且能够使用像map, reduce, join and window这样高级别的复杂算法处理。数据处理后可以输出到文件系统,如databases, and live dashboards。你也可以使用spark的机器学习,图处理算法在数据流上。

Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.
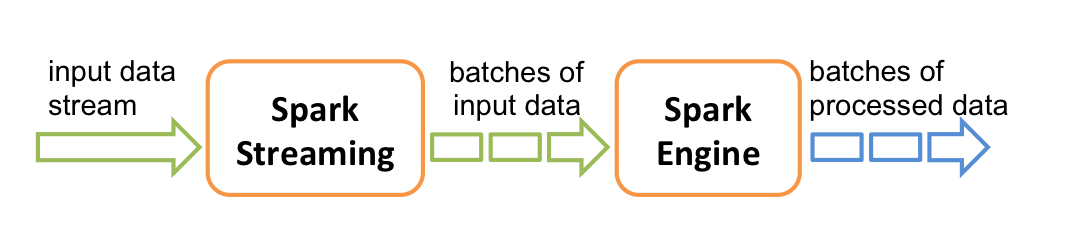
Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data. DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs.
Spark Streaming提出了一个高度抽象的概念叫做离散流或者DStream,来表达一个连续的流数据。一个Dstream可以看作一系列RDD。
Java编程练习:
一个spark streaming从socket获取数据进行单词统计的例子:(pom文件要添加spark相关依赖)
socket代码:
说明:启动一个socket服务端,等待连接,连接之后,重复输出一个字符串到连接的socket中。socket地址为本机,9999端口。
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Date; /**
* socket服务端简单实现,主要作用往socket客户端发送数据
*/
public class SocketServerPut {
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(9999);
Socket socket=null;
while(true) {
socket = serverSocket.accept();
while(socket.isConnected()) {
// 向服务器端发送数据
OutputStream os = socket.getOutputStream();
DataOutputStream bos = new DataOutputStream(os);
//每隔20ms发送一次数据
String str="Connect 123 test spark streaming abc xyz hik\n";
while(true){
bos.writeUTF(str);
bos.flush();
System.out.println(str);
//20ms发送一次数据
try {
Thread.sleep(500L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
//10ms检测一次连接
try {
Thread.sleep(10L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Spark Streaming 处理代码:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2; import java.util.Arrays; /**
* streaming从socket获取数据处理
*/
public class StreamingFromSocket {
public static void main(String[] args) {
//设置运行模式local 设置appname
SparkConf conf=new SparkConf().setMaster("local[2]").setAppName("StreamingFromSocketTest");
//初始化,设置窗口大小为2s
JavaStreamingContext jssc=new JavaStreamingContext(conf, Durations.seconds(2L));
//从本地Socket的9999端口读取数据
JavaReceiverInputDStream<String> lines= jssc.socketTextStream("localhost", 9999);
//把一行数据转化成单个单次 以空格分隔
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String,String>(){
@Override
public Iterable<String> call(String x){
return Arrays.asList(x.split(" "));
}
});
//计算每一个单次在一个batch里出现的个数
JavaPairDStream<String, Integer> pairs= words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s,1);
}
});
JavaPairDStream<String,Integer> wordCounts=pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer+integer2;
}
});
//输出统计结果
wordCounts.print();
jssc.start();
//20s后结束
jssc.awaitTerminationOrTimeout(20*1000L); }
}
输出结果:
-------------------------------------------
Time: 1470385522000 ms
-------------------------------------------
(hik,4)
(123,4)
(streaming,4)
(abc,4)
(test,4)
初始化streamingContext
1、方式一:使用sparkconf初始化
import org.apache.spark.*;
import org.apache.spark.streaming.api.java.*; SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaStreamingContext ssc = new JavaStreamingContext(conf, Duration(1000));
2、由已存在的sparkcontext初始化
import org.apache.spark.streaming.api.java.*; JavaSparkContext sc = ... //existing JavaSparkContext
JavaStreamingContext ssc = new JavaStreamingContext(sc, Durations.seconds(1));
After a context is defined, you have to do the following.
- Define the input sources by creating input DStreams.
- Define the streaming computations by applying transformation and output operations to DStreams.
- Start receiving data and processing it using
streamingContext.start(). - Wait for the processing to be stopped (manually or due to any error) using
streamingContext.awaitTermination(). - The processing can be manually stopped using
streamingContext.stop().
Points to remember:
- Once a context has been started, no new streaming computations can be set up or added to it.
- Once a context has been stopped, it cannot be restarted.
- Only one StreamingContext can be active in a JVM at the same time.
- stop() on StreamingContext also stops the SparkContext. To stop only the StreamingContext, set the optional parameter of
stop()calledstopSparkContextto false. - A SparkContext can be re-used to create multiple StreamingContexts, as long as the previous StreamingContext is stopped (without stopping the SparkContext) before the next StreamingContext is created.
初始化Context后,需要做如下几件事情,才能完成一个job。
1)定义一个输入源,从而产生DStreams;
2)定义streaming计算通过对DStreams应用转换和输出操作;
3)使用streamingContext.start()语句开始接受数据并进行处理;
4)使用streamingContext.awaitTermination().让程序等待job完成;程序异常也可导致停止job;
5)使用streamingContext.stop()可以停止job;
注意项:
1)当context开始后,新的streaming computation不能被设置和添加进来;
2)context停止后,不能重启;
3)同一时间JVM(java虚拟机)中只允许一个StreamingContext存在;
4)停止StreamingContext后,sparkcontext也会停止;如果你只想停止StreamingContext,你可以在stop的参数中设置stopSparkContext为false;
5)一个SparkContext可以被重复使用去创建StreamingContext,但新的StreamingContext被创建前,前一个StreamingContext要停止。
未完待续
2、 Spark Streaming方式从socket中获取数据进行简单单词统计的更多相关文章
- Spark Streaming连接TCP Socket
1.Spark Streaming是什么 Spark Streaming是在Spark上建立的可扩展的高吞吐量实时处理流数据的框架,数据可以是来自多种不同的源,例如kafka,Flume,Twitte ...
- 哪种方式更适合在React中获取数据?
作者:Dmitri Pavlutin 译者:小维FE 原文:dmitripavlutin.com 国外文章,笔者采用意译的方式,以保证文章的可读性. 当执行像数据获取这样的I/O操作时,你必须发起获取 ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- geotrellis使用(十六)使用缓冲区分析的方式解决投影变换中边缘数据值计算的问题
Geotrellis系列文章链接地址http://www.cnblogs.com/shoufengwei/p/5619419.html 目录 前言 问题探索 采样说明 实现方案 总结 一.前言 ...
- Thymeleaf+SpringMVC,如何从模板中获取数据
Thymeleaf+SpringMVC,如何从模板中获取数据 在一个典型的SpringMVC应用中,带@Controller注解的类负责准备数据模型Map的数据和选择一个视图进行渲染.这个模型Map对 ...
- hive从查询中获取数据插入到表或动态分区
Hive的insert语句能够从查询语句中获取数据,并同时将数据Load到目标表中.现在假定有一个已有数据的表staged_employees(雇员信息全量表),所属国家cnty和所属州st是该表的两 ...
- SpringMVC从Request域中获取数据
SpringMVC从Request域中获取数据的三种方式 SpringMVC环境自行搭建, 约定存在如下目录和文件:/WEB-INF/pages/success.jsp 方式一:传入Model对象 前 ...
- Django Form 实时从数据库中获取数据
修改 models.py 添加 class UserType(models.Model): caption = models.CharField(max_length=32) 执行命令,生成数据库 p ...
- SQL语句的使用,SELECT - 从数据库表中获取数据 UPDATE - 更新数据库表中的数据 DELETE - 从数据库表中删除数据 INSERT INTO - 向数据库表中插入数据
SQL DML 和 DDL 可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL). SQL (结构化查询语言)是用于执行查询的语法. 但是 SQL 语言也包含用于更新. ...
随机推荐
- zoj 3755
状态压缩dp 扫雷 n×M格子奇数行有雷,给出偶数行的数字,求最少有多少个雷. 刚开始觉得状压状态不知道怎么办,因为每行能影响的范围太广,后来展昭说横着来,然后几分钟就a了. 这件事请告诉我们看问题要 ...
- Go语言之defer
defer语句被用于预定对一个函数的调用.我们把这类被defer语句调用的函数称为延迟函数.注意,defer语句只能出现在函数或方法的内部. 一条defer语句总是以关键字defer开始.在defer ...
- 自定义 select 下拉菜单
.selectBeautifyMainStyle{ color: #9fa0a0; font-size: 14px; font-family: "alegreya_sansthin" ...
- Debian/Ubuntu 安装bcm43142无线网卡驱动
Drivers for Broadcom BCM43142 wireless card of Ubuntu/Debian 64-bit Linux 1.Check the wireless card ...
- 使用typedef语句定义数组类型
使用typedef语句定义数组类型 1. 一维数组类型的定义格式 typedef <元素类型关键字><数组类型名>[<常量表达式>]; 例如: (1) ty ...
- 为什么Application_BeginRequest会执行两次
大家也看到了,很奇怪的是我们明明就请求了一个页面,页面中也没有其他的图片请求.为什么Application_BeginRequest会被执行了两次呢?!既然他请求,那我们看看他到底在请求什么就是 ...
- 搜索引擎选择: Elasticsearch与Solr
我用过这两种搜索引擎,但也仅仅是用过而已,没有非常深入研究,以下是我的看法 lucene是完全用java实现,而sphinx是支持java api.显然这两者是有差别的,用java实现的意义在于,你可 ...
- MyBatis里json型字段到Java类的映射
一.简介 我们在用MyBatis里,很多时间有这样一个需求:bean里有个属性是非基本数据类型,在DB存储时我们想存的是json格式的字符串,从DB拿出来时想直接映射成目标类型,也即json格式的字符 ...
- Oracle 11gR2 RAC Votedisk and OCR Diskgroup Recovery
check votedisk and OCR [root@vzwc1 ~]# ocrcheck Status of Oracle Cluster Registry is as follows : Ve ...
- asp.net 中的错误跳转 customerrors 对html文件不起作用
在配置web.config时发现customerrors对aspx文件是起作用的,我想通过customerrors来判断是否有html文件时,却不起作用? 这是为什么,如果要起作用.net里该如何操作 ...