Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码。
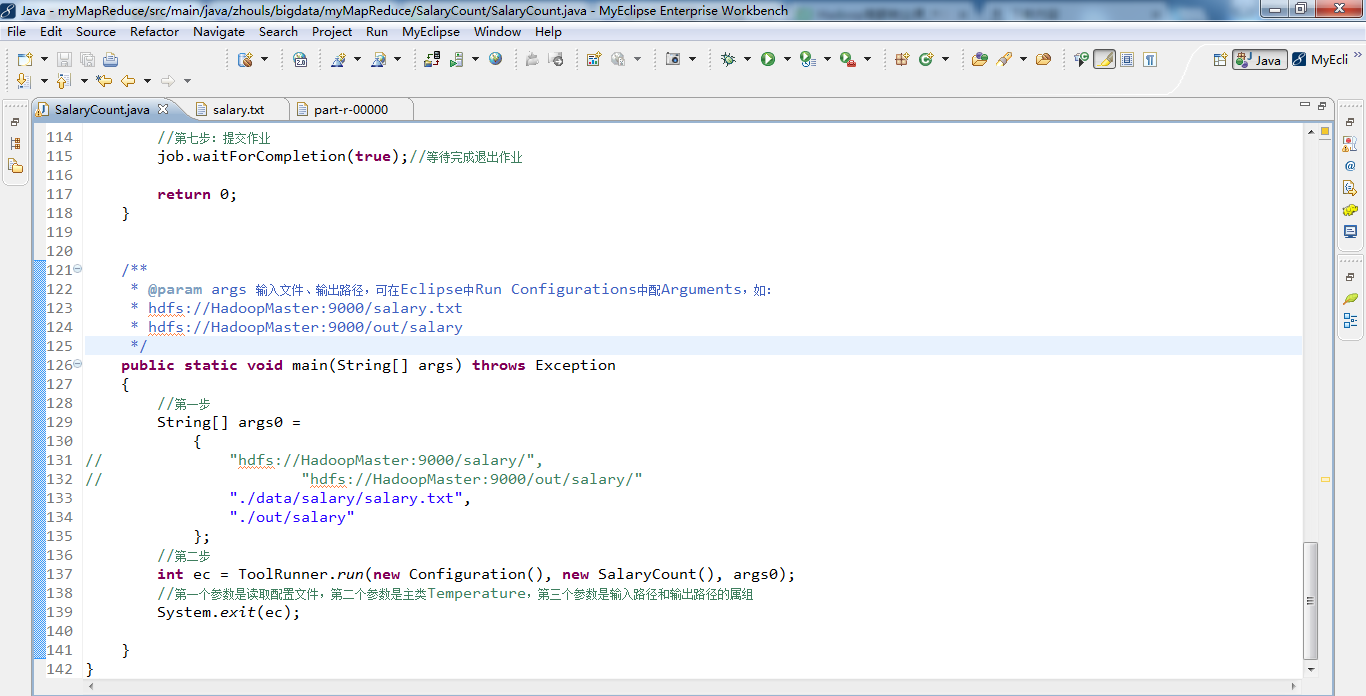
代码
package zhouls.bigdata.myMapReduce.SalaryCount;
import java.io.IOException;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 基于样本数据做Hadoop工程师薪资统计:计算各工作年限段的薪水范围
*/
public class SalaryCount extends Configured implements Tool
{
public static class SalaryMapper extends Mapper<LongWritable, Text, Text, Text>
{
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
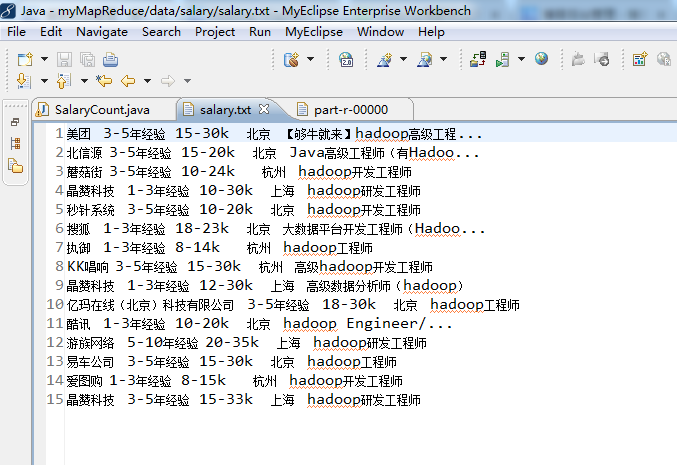
// 美团 3-5年经验 15-30k 北京 【够牛就来】hadoop高级工程...
//北信源 3-5年经验 15-20k 北京 Java高级工程师(有Hadoo...
// 蘑菇街 3-5年经验 10-24k 杭州 hadoop开发工程师
//第一步,将输入的纯文本文件的数据转化成String
String line = value.toString();//读取每行数据
String[] record = line.split( "\\s+");//使用空格正则解析数据
//key=record[1]:输出3-5年经验
//value=record[2]:15-30k
//作为Mapper输出,发给 Reduce 端
//第二步
if(record.length >= 3)//因为取得的薪资在第3列,所以要大于3
{
context.write( new Text(record[1]), new Text(record[2]) );
//Map输出,record数组的第2列,第3列
}
}
}
public static class SalaryReducer extends Reducer<Text, Text, Text, Text>
{
public void reduce(Text Key, Iterable<Text> Values, Context context) throws IOException, InterruptedException
{
int low = 0;//记录最低工资
int high = 0;//记录最高工资
int count = 1;
//针对同一个工作年限(key),循环薪资集合(values),并拆分value值,统计出最低工资low和最高工资high
for (Text value : Values)
{
String[] arr = value.toString().split("-");//其中的一行而已,15 30K
int l = filterSalary(arr[0]);//过滤数据 //15
int h = filterSalary(arr[1]);//过滤数据 //30
if(count==1 || l< low)
{
low = l;
}
if(count==1 || h>high)
{
high = h;
}
count++;
}
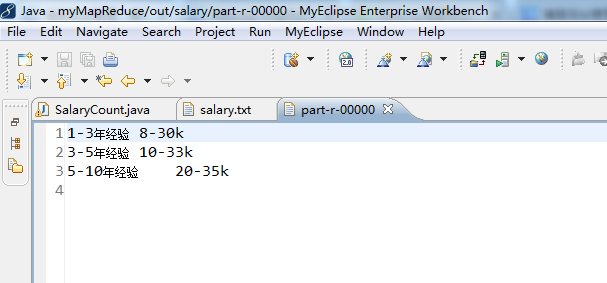
context.write(Key, new Text(low + "-" +high + "k"));//即10-30K
}
}
//正则表达式提取工资值,因为15 30k,后面有k,不干净
public static int filterSalary(String salary)//过滤数据
{
String sal = Pattern.compile("[^0-9]").matcher(salary).replaceAll("");
return Integer.parseInt(sal);
}
public int run(String[] args) throws Exception
{
//第一步:读取配置文件
Configuration conf = new Configuration();//读取配置文件
//第二步:输出路径存在就先删除
Path out = new Path(args[1]);//定义输出路径的Path对象,mypath
FileSystem hdfs = out.getFileSystem(conf);//通过路径下的getFileSystem来获得文件系统
if (hdfs.isDirectory(out))
{//删除已经存在的输出目录
hdfs.delete(out, true);
}
//第三步:构建job对象
Job job = new Job(conf, "SalaryCount" );//新建一个任务
job.setJarByClass(SalaryCount.class);//设置 主类
//通过job对象来设置主类SalaryCount.class
//第四步:指定数据的输入路径和输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));// 文件输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 文件输出路径
//第五步:指定Mapper和Reducer
job.setMapperClass(SalaryMapper.class);// Mapper
job.setReducerClass(SalaryReducer.class);// Reducer
//第六步:设置map函数和reducer函数的输出类型
job.setOutputKeyClass(Text.class);//输出结果key类型
job.setOutputValueClass(Text.class);//输出结果的value类型
//第七步:提交作业
job.waitForCompletion(true);//等待完成退出作业
return 0;
}
/**
* @param args 输入文件、输出路径,可在Eclipse中Run Configurations中配Arguments,如:
* hdfs://HadoopMaster:9000/salary.txt
* hdfs://HadoopMaster:9000/out/salary
*/
public static void main(String[] args) throws Exception
{
//第一步
String[] args0 =
{
// "hdfs://HadoopMaster:9000/salary/",
// "hdfs://HadoopMaster:9000/out/salary/"
"./data/salary/salary.txt",
"./out/salary"
};
//第二步
int ec = ToolRunner.run(new Configuration(), new SalaryCount(), args0);
//第一个参数是读取配置文件,第二个参数是主类Temperature,第三个参数是输入路径和输出路径的属组
System.exit(ec);
}
}
Hadoop MapReduce编程 API入门系列之薪水统计(三十一)的更多相关文章
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
随机推荐
- UVA 208 (DFS)
题意:找出1到T的所有路径: 坑点:一开始以为是到终点,读错了题意,没测试第二个样例,结果WA了4遍,坑大了: #include <iostream> #include <cmath ...
- Boundaries
Using Third-Party Code There is a natural tension between the provider of an interface and the user ...
- 12-8 php基础
<?php //单行注释/* 多行注释*/ //弱类型语言//var a = 10;/*$a=10;$b = "hello";var_dump($a);$a="wo ...
- fastcoloredtextbox 中文不重叠
DrawLineChars方法: private void DrawLineChars(PaintEventArgs e, int firstChar, int lastChar, int iLine ...
- sqlite入门
SQLite官网: https://www.sqlite.org/index.html 1. 下载请到https://www.sqlite.org/download.html下载相应平台的sqlite ...
- read.csv 把 "T" 读成 "TRUE" 的问题
read.csv(text="A,B,T,T", header=FALSE) ## V1 V2 V3 V4 ## 1 A B TRUE TRUE RT, 有的时候R读取数据的时候容 ...
- 华为HG255D路由器使用OH3C进行中大校园网认证
之前用的上海贝尔RG100A-AA路由器,被我无情地摧残了,电源按钮挂了,只能换个路由器.由于在校内,使用OP还是比较方便的,网上淘了这款华为HG255D,店主已刷好OP,无线速率300M,想想也是值 ...
- @SuppressWarnings有什么用处?
J2SE 提供的最后一个批注是 @SuppressWarnings.该批注的作用是给编译器一条指令,告诉它对被批注的代码元素内部的某些警告保持静默. @SuppressWarnings 批注允许您选择 ...
- IOS学习笔记34—EGOTableViewPullRefresh实现下拉刷新
移动应用开发中有这么一种场景,就是在列表中显示的数据刷新,有点击刷新按钮刷新的,也有现在最流行的由Twitter首先推出的下拉刷新功能,在IOS中,使用下拉刷新更新UITableView中的数据也用的 ...
- Oracle建表添加数据