Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码。
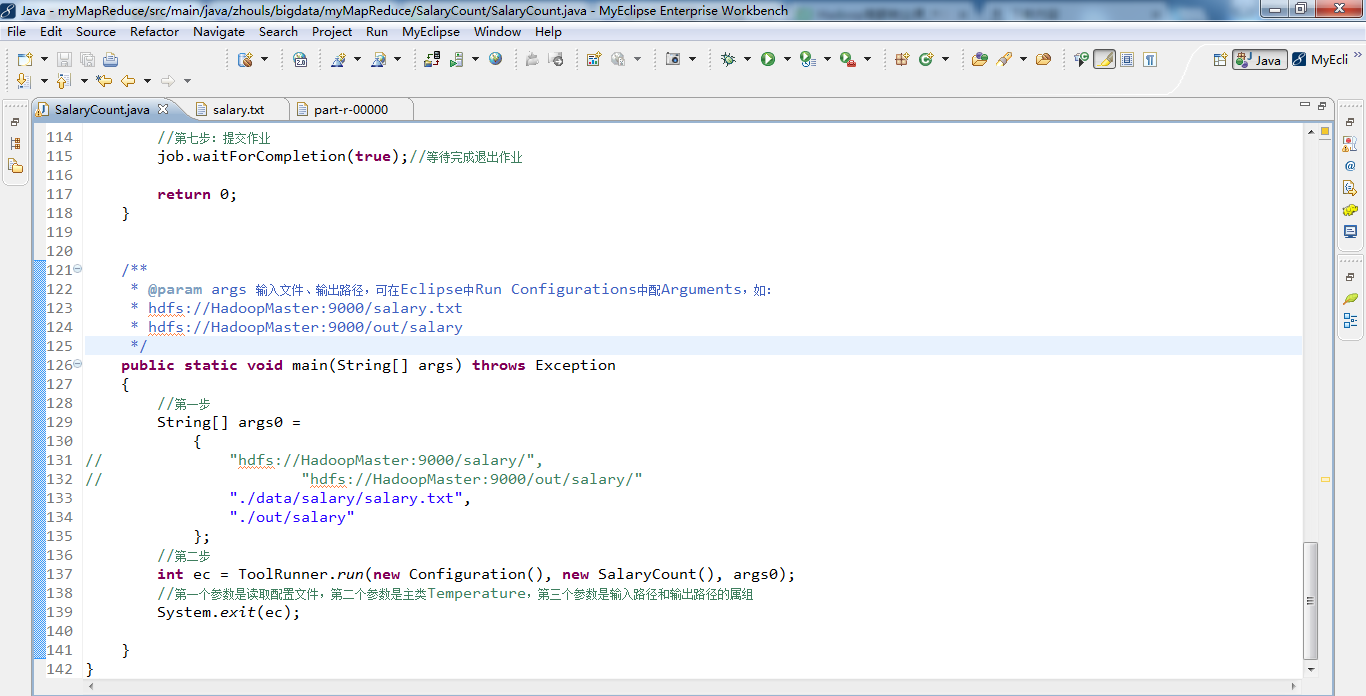
代码
package zhouls.bigdata.myMapReduce.SalaryCount;
import java.io.IOException;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 基于样本数据做Hadoop工程师薪资统计:计算各工作年限段的薪水范围
*/
public class SalaryCount extends Configured implements Tool
{
public static class SalaryMapper extends Mapper<LongWritable, Text, Text, Text>
{
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
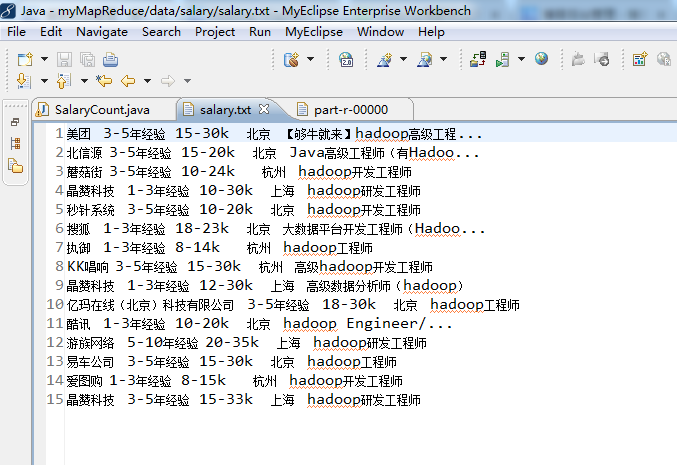
// 美团 3-5年经验 15-30k 北京 【够牛就来】hadoop高级工程...
//北信源 3-5年经验 15-20k 北京 Java高级工程师(有Hadoo...
// 蘑菇街 3-5年经验 10-24k 杭州 hadoop开发工程师
//第一步,将输入的纯文本文件的数据转化成String
String line = value.toString();//读取每行数据
String[] record = line.split( "\\s+");//使用空格正则解析数据
//key=record[1]:输出3-5年经验
//value=record[2]:15-30k
//作为Mapper输出,发给 Reduce 端
//第二步
if(record.length >= 3)//因为取得的薪资在第3列,所以要大于3
{
context.write( new Text(record[1]), new Text(record[2]) );
//Map输出,record数组的第2列,第3列
}
}
}
public static class SalaryReducer extends Reducer<Text, Text, Text, Text>
{
public void reduce(Text Key, Iterable<Text> Values, Context context) throws IOException, InterruptedException
{
int low = 0;//记录最低工资
int high = 0;//记录最高工资
int count = 1;
//针对同一个工作年限(key),循环薪资集合(values),并拆分value值,统计出最低工资low和最高工资high
for (Text value : Values)
{
String[] arr = value.toString().split("-");//其中的一行而已,15 30K
int l = filterSalary(arr[0]);//过滤数据 //15
int h = filterSalary(arr[1]);//过滤数据 //30
if(count==1 || l< low)
{
low = l;
}
if(count==1 || h>high)
{
high = h;
}
count++;
}
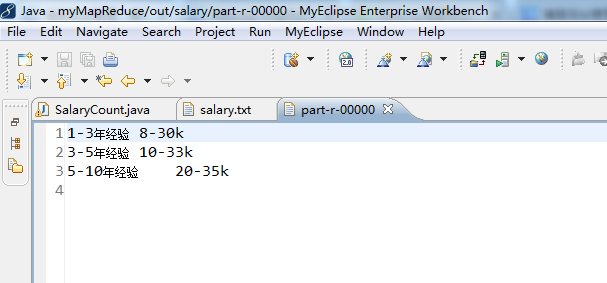
context.write(Key, new Text(low + "-" +high + "k"));//即10-30K
}
}
//正则表达式提取工资值,因为15 30k,后面有k,不干净
public static int filterSalary(String salary)//过滤数据
{
String sal = Pattern.compile("[^0-9]").matcher(salary).replaceAll("");
return Integer.parseInt(sal);
}
public int run(String[] args) throws Exception
{
//第一步:读取配置文件
Configuration conf = new Configuration();//读取配置文件
//第二步:输出路径存在就先删除
Path out = new Path(args[1]);//定义输出路径的Path对象,mypath
FileSystem hdfs = out.getFileSystem(conf);//通过路径下的getFileSystem来获得文件系统
if (hdfs.isDirectory(out))
{//删除已经存在的输出目录
hdfs.delete(out, true);
}
//第三步:构建job对象
Job job = new Job(conf, "SalaryCount" );//新建一个任务
job.setJarByClass(SalaryCount.class);//设置 主类
//通过job对象来设置主类SalaryCount.class
//第四步:指定数据的输入路径和输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));// 文件输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 文件输出路径
//第五步:指定Mapper和Reducer
job.setMapperClass(SalaryMapper.class);// Mapper
job.setReducerClass(SalaryReducer.class);// Reducer
//第六步:设置map函数和reducer函数的输出类型
job.setOutputKeyClass(Text.class);//输出结果key类型
job.setOutputValueClass(Text.class);//输出结果的value类型
//第七步:提交作业
job.waitForCompletion(true);//等待完成退出作业
return 0;
}
/**
* @param args 输入文件、输出路径,可在Eclipse中Run Configurations中配Arguments,如:
* hdfs://HadoopMaster:9000/salary.txt
* hdfs://HadoopMaster:9000/out/salary
*/
public static void main(String[] args) throws Exception
{
//第一步
String[] args0 =
{
// "hdfs://HadoopMaster:9000/salary/",
// "hdfs://HadoopMaster:9000/out/salary/"
"./data/salary/salary.txt",
"./out/salary"
};
//第二步
int ec = ToolRunner.run(new Configuration(), new SalaryCount(), args0);
//第一个参数是读取配置文件,第二个参数是主类Temperature,第三个参数是输入路径和输出路径的属组
System.exit(ec);
}
}
Hadoop MapReduce编程 API入门系列之薪水统计(三十一)的更多相关文章
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
随机推荐
- python模块之collections
我们都知道,Python拥有一些内置的数据类型,比如str, int, list, tuple, dict等, collections模块在这些内置数据类型的基础上,提供了几个额外的数据类型: (1) ...
- Android 学习第5课,配置android
昨天与今天都在配置安卓的开发环境, 搞的头都大了,步骤比较多 1. 先下载安装 java 的 jdk ,这个是最基础的组件 2. 再下载 android SDK, http://developer. ...
- VS 2013 打包程序教程
简述 如果你只是想要在他人的机子上运行你的程序而不想安装,有一种简单的方法,只要使用本教程的“步骤—3.生成Release 文件夹”即可.但是有一点需要注意,如果你在程序中调用了其他的dll,那么你需 ...
- ASP代码审计 -4.命令执行漏洞总结
命令执行漏洞: 保存为cmd.asp,提交链接: http://localhost/cmd.asp?ip=127.0.0.1 即可执行命令 <%ip=request("ip" ...
- ipvsadm命令使用方法
由于LVS(IPVS)是工作在内核空间的,因此要在用户空间对其进行配置和管理就要用到ipvsadm,ipvsadm是LVS在用户空间的管理命令. 一般在安装linux(CentOS6.5)时该命令是为 ...
- LeetCode-Group Anagrams
Given an array of strings, group anagrams together. For example, given: ["eat", "tea& ...
- (转)注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 本文转自:http://www.cnblogs.com/robert-dlut/p/5952032.html 近年来,深度 ...
- ajax请求后弹开新页面被浏览器拦截
window.open()我想应该很多人都不陌生吧,它可以实现除用a标签以外来实现打开新窗口! 最近开发项目用到时,却遇到了麻烦,本来好好的弹出窗口,结果被浏览器无情的给拦截了! 代码如下: $.ge ...
- 互斥锁(Mutex)
互斥锁(Mutex)互斥锁是一个互斥的同步对象,意味着同一时间有且仅有一个线程可以获取它.互斥锁可适用于一个共享资源每次只能被一个线程访问的情况 函数://创建一个处于未获取状态的互斥锁Public ...
- HttpWebRequest.GetResponse 方法 转载
GetResponse 方法返回包含来自 Internet 资源的响应的 WebResponse 对象. 实际返回的实例是 HttpWebResponse,并且能够转换为访问 HTTP 特定的属性的类 ...