模块/os/sys/json
内容概要
- os模块
- sys模块
- json模块/实战
1.os模块
# os模块主要是与我们的操作系统打交道
1.创建文件夹(目录)
import os
os.mkdir(文件夹名字) # 创建当前文件目录下单极空文件夹
os.makedirs(文件夹名字/文件夹名字) # 创建当前文件目录下多级空文件夹/也可以单文件夹
2.删除文件夹
import os
os.rmdir('module1') # 删除单级空目录
os.removedirs('module2/mm1/m1') # 删除多级空目录
3.获取文件所在位置文件名称
import os
print(os.listdir()) # 获取执行文件当前目录的文件名
print(os.listdir('C:\\')) # ()可以填写具体路径查询当前目录下的所有文件
4.修改文件名与删除文件(当前文件所在路径)
import os
os.rename('bb.txt','xiaoxin.txt') # 更改当前目录下的文件名字
os.remove('bb.txt') # 删除当前目录内的指定文件
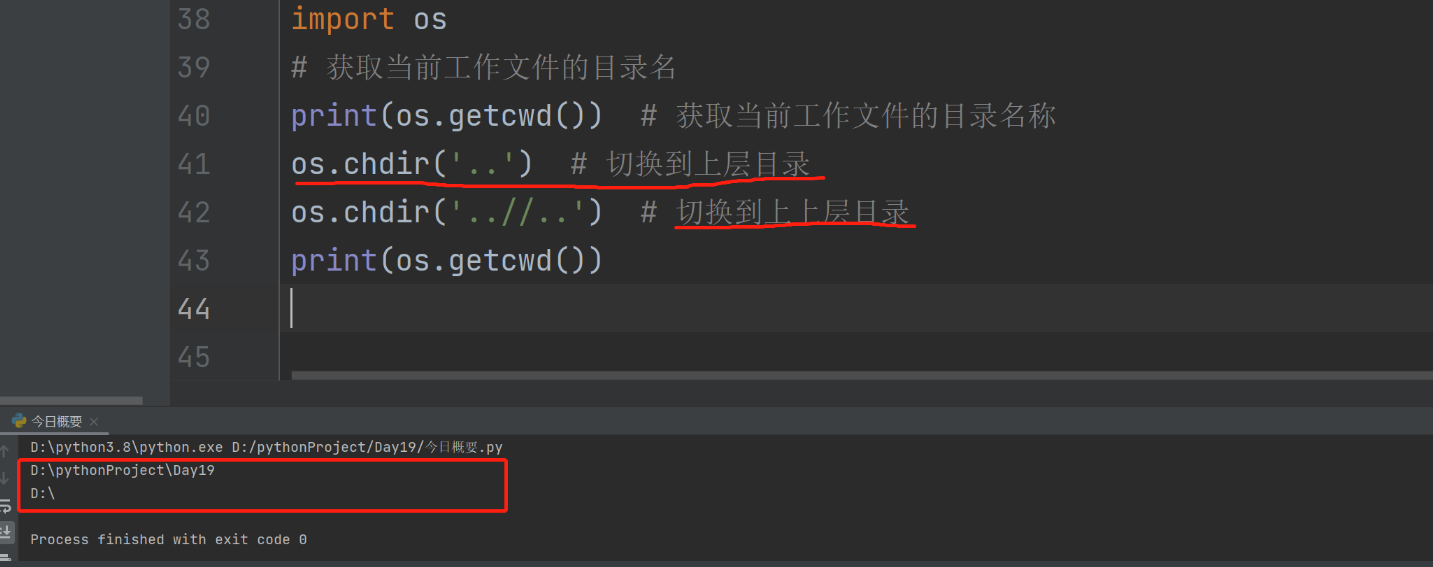
5.获取当前执行文件的目录名
import os
# 获取当前工作文件的目录名
print(os.getcwd()) # 获取当前工作文件的目录名称
os.chdir('..') # 切换到上层目录
os.chdir('..//..') # 切换到上上层目录
print(os.getcwd())
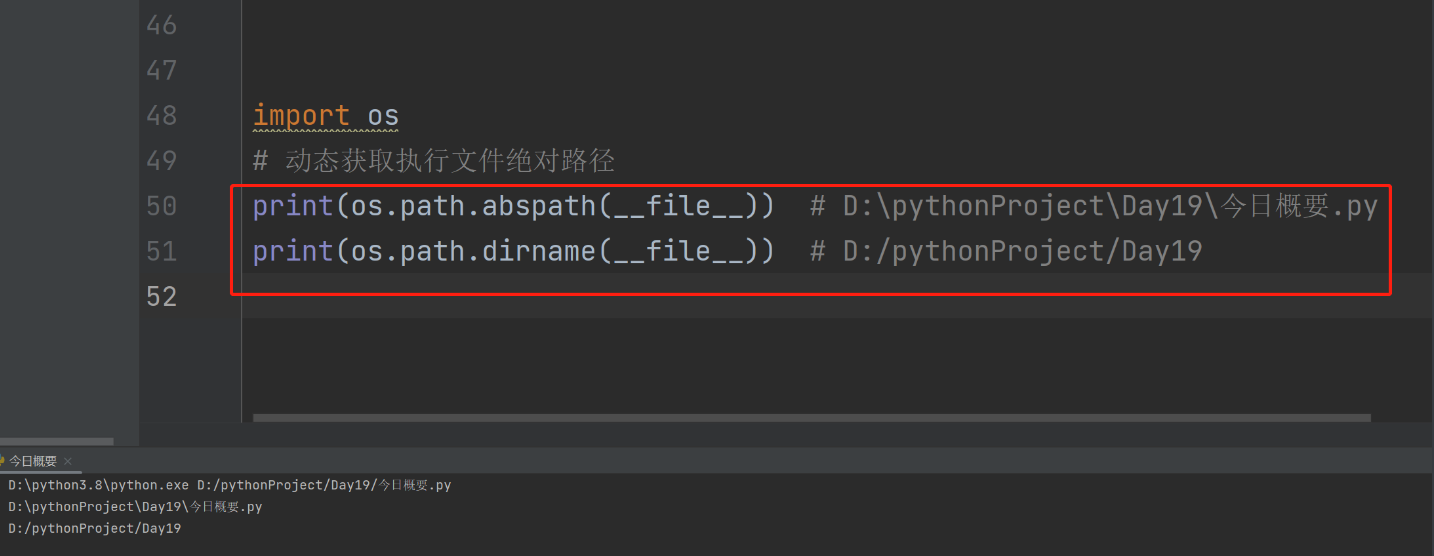
6.动态获取执行文件的路径/目录 !!
import os
# 动态获取执行文件绝对路径
print(os.path.abspath(__file__)) # D:\pythonProject\Day19\今日概要.py
print(os.path.dirname(__file__)) # D:/pythonProject/Day19
7. 判断路径内文件/目录是否存在
import os.path
#
os.makedirs('module1/mm1') # 如果文件存在就无法创建新的空文件目录
print(os.path.exists(r'xiaoxin.txt')) # 判断当前执行文件目录内文件名是否存在
print(os.path.exists('bb.txt')) # 无法判断除当前执行文件目录外其他层级的文件
print(os.path.exists('module1/mm1/bb.txt')) # 填写详细路径即可做判断

8. 判断路径内文件是否存在
import os.path
print(os.path.isfile('module1/mm1/bb.txt'))
9.判断路径文件夹是否存在
print(os.path.isdir('mm1'))
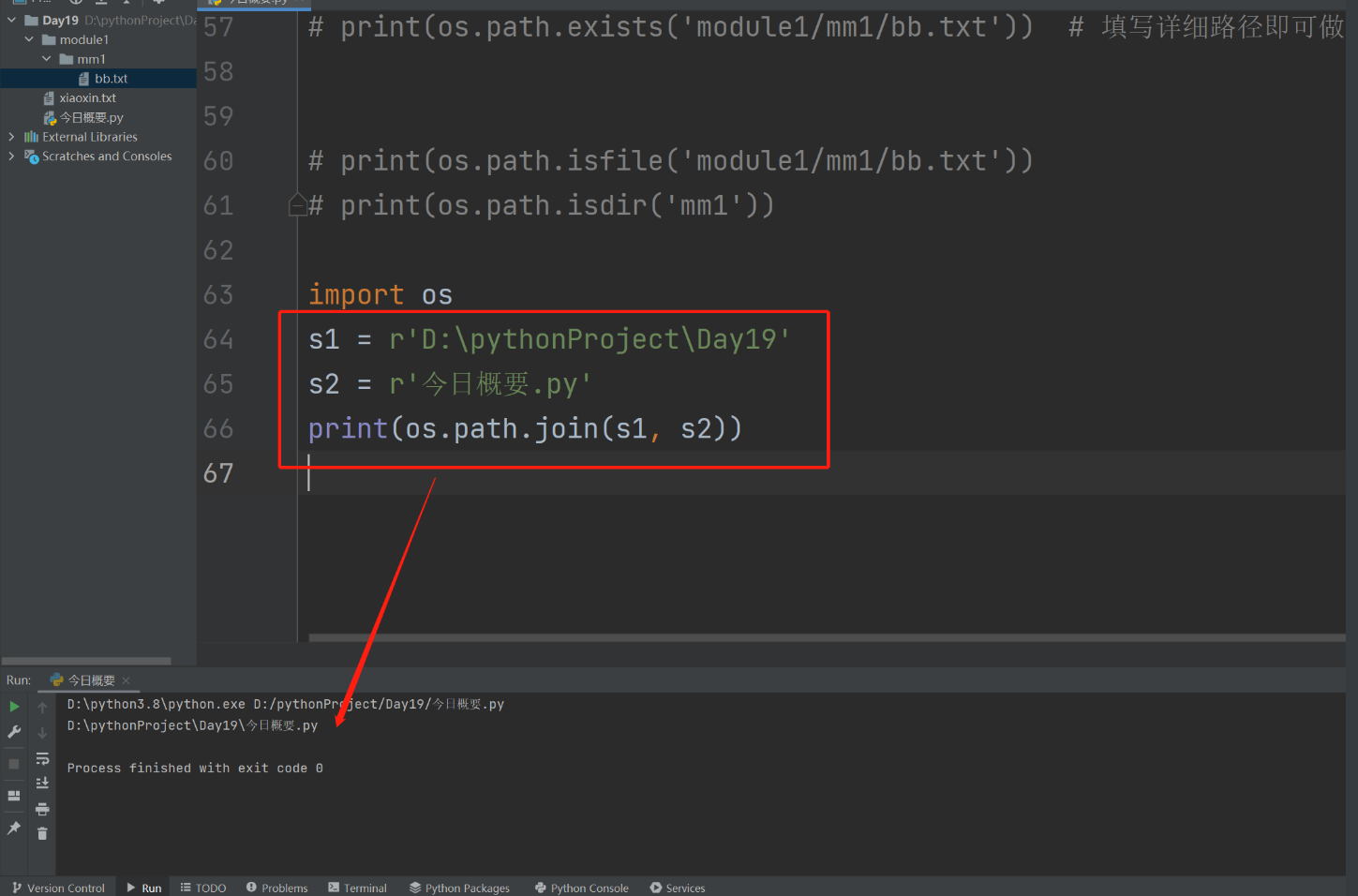
10.拼接路径 !!
import os
s1 = r'D:\pythonProject\Day19'
s2 = r'今日概要.py'
print(os.path.join(s1, s2))
11.计算文件内部字符数量
import os
print(os.path.getsize('module1/mm1/bb.txt'))
2.sys模块
sys模块主要是帮助我们与python解释器打交道
import sys
path
1.print(sys.path) # 返回当前Py的环境路径(当前py环境可以导入内置、第三方包与函数的所在路径)
platform
2.print(sys.platform) # 获取当前系统平台(如windows、Mac、linux)
version
3.print(sys.version) # 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)] 获取当前 Python 的版本
modules
4.print(sys.modules) # 将Python启动时加载的模块集合起来并返回一个列表
getrecursionlimit()
5.print(sys.getrecursionlimit()) # 获取python解释器默认最大递归深度 ()可以填写参数更改最大递归深度
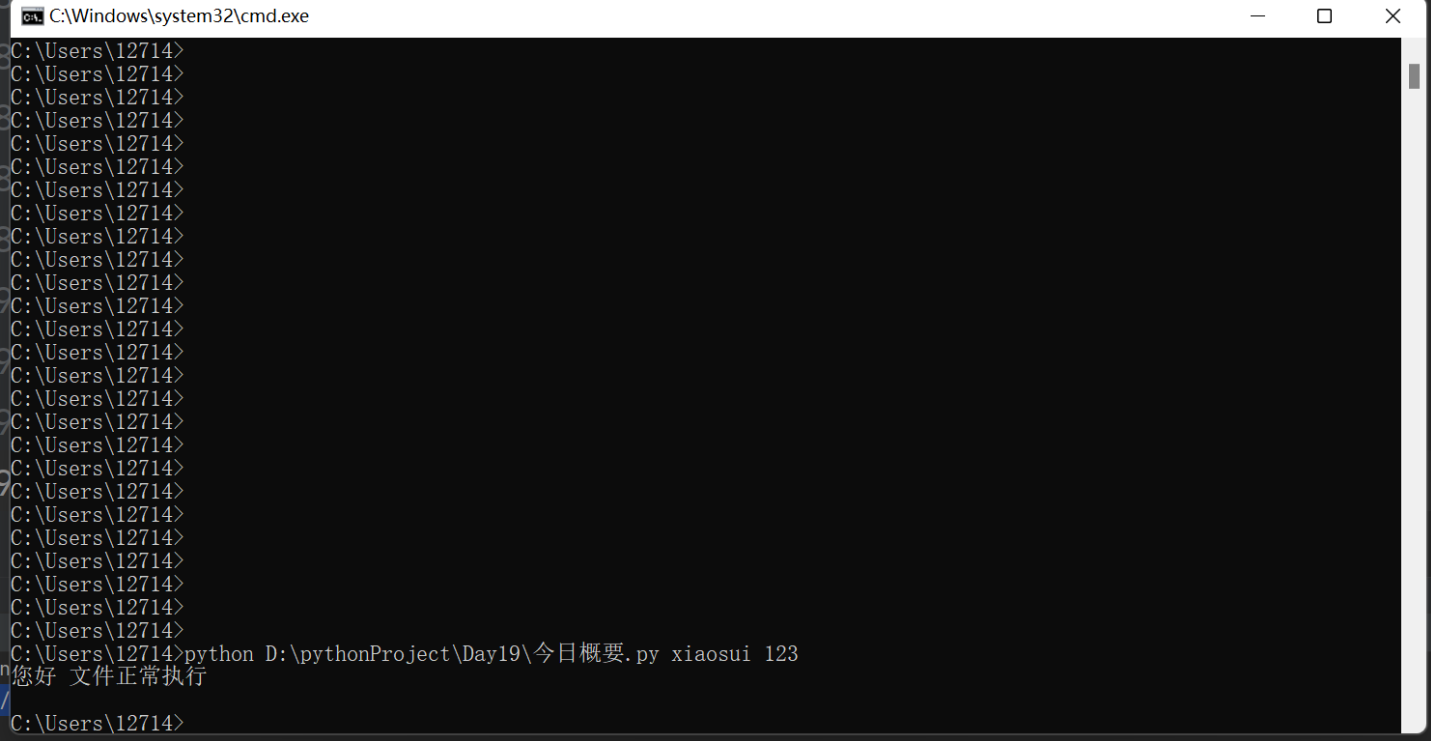
argv
6.
# argv 获取程序外部的参数,返回值是一个列表
res = argv
if len(res) != 3:
print('执行命令缺少了用户名或密码')
else:
username = res[1]
password = res[2]
if username == 'xiaosui' and password == '123':
print('您好 文件正常执行')
else:
print('您不是无权执行该文件')
它主要是在cmd终端中添加的功能,如果需要用终端调用这个文件,那么必须要传输参数 在文件后面 如果不传输就不可以使用这个文件
3.json模块/实战
json 是一种'字符串'数据格式
我们使用json格式数据就可以让编程语言中的数据轻松的转换到别的编程语言中
json模块的主要功能是将序列化数据从文件里读取出来或者存入文件
序列化可以打破语言限制实现不同编程语言之间数据交互
'''
json 数据的形式都是字符串类型,并且是双引号引起来的
'''
1.针对数据
dumps
d1 = {'name': 'xiaoming', 'age': 18, 'sex': 'male', 'account': 15000}
json_dict1 = json.dumps(d1)
print(json_dict1) # 转为 json 格式
loads
with open('xiaoxin.txt','r',encoding='utf8') as f:
for i in f:
print(json.loads(i), type(json.loads(i)))
# {'1': {'name': 'xiaoming', 'age': 18, 'sex': 'male', 'account': 15000}} <class 'dict'>
2.针对文件
dump
d1 = {1: {'name': 'xiaoming', 'age': 18, 'sex': 'male', 'account': 15000}}
# json_dict1 = json.dumps(d1)
# print(json_dict1)
with open('xiaoxin.txt','w',encoding='utf8') as f:
json.dump(d1, f)
可以直接把d1字典类型转为json格式并直接写入文件中
load
with open('xiaoxin.txt','r',encoding='utf8') as f:
data = json.load(f)
print(data,type(data))
# {'1': {'name': 'xiaoming', 'age': 18, 'sex': 'male', 'account': 15000}} <class 'dict'>
def register():
import os
import json
# 存储用户数据建立信息存放库
start_file = os.path.dirname(__file__) # 获取当前执行文件目录名
db_dir = os.path.join(start_file, 'db_info') # 拼接文件目录名和db_info文件夹
if not os.path.isdir(db_dir): # 判断执行文件目录中有没有db_info的文件夹
os.makedirs(db_dir) # 在绝对路径里面创建一个db_info文件夹
# 获取用户输入:
user_name = input('please input your username >>>>>:').strip()
user_data_file = os.path.join(db_dir, f'{user_name}.json') # 拼接用户信息文件路径
if not os.path.isfile(user_data_file):
pass_word = input('please input your password >>>>>:').strip()
user_dict = { # 创建用户数据字典
'user_name': None,
'pass_word': None,
'age': None,
'account': 15000
}
user_dict['user_name'] = user_name
user_dict['pass_word'] = pass_word
with open(f'{user_data_file}','w',encoding='utf8') as f:
json.dump(user_dict, f)
print(f'恭喜用户{user_name}注册成功~!')
else:
print('用户名已存在!')
def login():
start_file = os.path.dirname(__file__) # 获取当前执行文件目录名
db_dir = os.path.join(start_file, 'db_info') # 拼接文件目录名和db_info文件夹
if not os.path.isdir(db_dir): # 判断执行文件目录中有没有db_info的文件夹
os.makedirs(db_dir) # 在绝对路径里面创建一个db_info文件夹
user_name = input('please input your username >>>>>:').strip()
user_data_file = os.path.join(db_dir, f'{user_name}.json')
if os.path.isfile(user_data_file):
pass_word = input('please input your password >>>>>:').strip()
with open(f'{user_data_file}','r',encoding='utf8') as f:
real_user_dict = json.load(f)
if real_user_dict['user_name'] == user_name and real_user_dict['pass_word'] == pass_word:
print(f'欢迎光临,用户{user_name}登录成功')
else:
print('用户名都错了,密码还能对了吗,小笨蛋?')
4.练习题及答案
### 作业
```python
1.编写一个统计指定文件类型的脚本工具
输入指定类型的文件后缀
eg:.txt
并给出一个具体路径 之后统计该类型文件在该文件下的个数
ps:简单实现即可 无需优化
# solution1:
target_file_class = input('请输入您想要查询的文件后缀名').strip()
target_path = input('请输入您想要查询信息的路径>>>>>>:').strip()
data_list = os.listdir(r'{}'.format(target_path))
l2 = []
for i in data_list:
if target_file_class in i:
l2.append(i)
print('您好您需要找的数据为:',l2, '共', len(l2), r'个{}类型的文件'.format(target_file_class))
2.针对json实操 尝试单文件多用户(一行一个)是否可实现>>>:哪个更方便
不要求完成 单纯体会两种思路的难易
实现不了
3.编程小练习
有一个目录文件下面有一堆文本文件
eg:
db目录
J老师视频合集
R老师视频合集
C老师视频合集
B老师视频合集
文件内容自定义即可 要求循环打印出db目录下所有的文件名称让用户选择
用户选择哪个文件就自动打开该文件并展示内容
涉及到文件路径全部使用代码自动生成 不准直接拷贝当前计算机固定路径
import os
start_file = os.path.dirname(__file__)
db_dir_path = os.path.join(start_file, 'db_dir')
if not os.path.isdir(db_dir_path): # 判断执行文件目录中有没有db_dir的文件夹
os.makedirs(db_dir_path)
file_name = os.listdir(db_dir_path)
while True:
for i in file_name:
vision = i.strip('.txt')
print(vision)
choice = input('请输入您想要观看的文件名>>>>>>:')
real_file_path = os.path.join(db_dir_path, (choice + '.txt'))
if len(choice) == 7:
with open(real_file_path, 'r', encoding='utf8') as f:
for line in f:
print(line)
else:
print('请输入正确的文件名!')
4.周末大作业(尝试编写)
# 项目功能
1.用户注册
2.用户登录
3.添加购物车
4.结算购物车
# 项目说明
用户数据采用json格式存储到文件目录db下 一个用户一个单独的文件
数据格式 {"name":"jason","pwd":123}
# ps:文件名可以直接用用户名便于校验
用户注册时给每个用户添加两个默认的键值对(账户余额 购物车)
{"balance":15000,"shop_car":{}}
添加购物车功能 商品列表可以自定义或者采用下列格式
good_list = [
['挂壁面',3]
['印度飞饼', 22]
['极品木瓜', 666],
['土耳其土豆', 999],
['伊拉克拌面', 1000],
['董卓戏张飞公仔', 2000],
['仿真玩偶', 10000]
]
用户可以反复添加商品,在购物车中记录数量
{'极品木瓜':[个数,单价]}
结算购物车
获取用户购物车中所有的商品计算总价并结算即可
针对添加购物车和结算只有登录的用户才可以执行
```
模块/os/sys/json的更多相关文章
- 模块random+os+sys+json+subprocess
模块random+os+sys+json+subprocess 1. random 模块 (产生一个随机值) import random 1 # 随机小数 2 print(random.rando ...
- 6 - 常用模块(os,sys,time&datetime,random,json&picle,shelve,hashlib)
导入模块 想使用 Python 源文件,只需在另一个源文件里执行 import 语句 import module1[, module2[,... moduleN] from语句让你从模块中导入一个指定 ...
- python模块 os&sys&subprocess&hashlib模块
os模块 # os模块可根据带不带path分为两类 # 不带path print(os.getcwd()) # 得到当前工作目录 print(os.name) # 指定你正在使用的操作系统,windo ...
- Python常用模块os & sys & shutil模块
OS模块 import os ''' os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录: ...
- 学到了林海峰,武沛齐讲的Day22-完 os sys json pickle shelve XML re
__ file__ ===== 文件路径 os.path.dirname( 路径 )=======到上一层目录 os sys
- python --- 23 模块 os sys pickle json
一. os模块 主要是针对操作系统的 用于文件操作 二. sys 模块 模块的查找路径 sys.path 三.pickle 模块 1. pickle.dumps(对象) 序列化 把对 ...
- 23 模块 os sys pickle json
一. os模块 主要是针对操作系统的 用于文件操作 二. sys 模块 模块的查找路径 sys.path 三 pickle 模块 1. pickle.dumps(对象) 序列化 ...
- python之常见模块(time,datetime,random,os,sys,json,pickle)
目录 time 为什么要有time模块,time模块有什么用?(自己总结) 1. 记录某一项操作的时间 2. 让某一块代码逻辑延迟执行 时间的形式 时间戳形式 格式化时间 结构化时间 时间转化 总结: ...
- Day 17 time,datetime,random,os,sys,json,pickle
time模块 1.作用:打印时间,需要时间的地方,暂停程序的功能 时间戳形式 time.time() # 1560129555.4663873(python中从1970年开始计算过去了多少秒) 格式化 ...
- Python模块 - os , sys.shutil
os 模块是与操作系统交互的一个接口 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录: ...
随机推荐
- 【设计模式】Java设计模式 - 模板模式
Java设计模式 - 模板模式 不断学习才是王道 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 原创作品,更多关注我CSDN: 一个有梦有戏的人 准备将博客园.CSDN一起记录分享自己 ...
- 8. Ceph 基础篇 - 运维常用操作
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247485300&idx=1&sn=aacff9f7 ...
- Elasticsearch:设置Elastic账户安全
- 使用二进制文件部署Etcd集群
Etcd 是一个分布式键值存储系统,Kubernetes使用Etcd进行数据存储,所以先准备一个Etcd数据库,为解决Etcd单点故障,应采用集群方式部署,这里使用3台组建集群,可容忍1台机器故障,当 ...
- Logstash & 索引生命周期管理(ILM)
Grok语法 Grok是通过模式匹配的方式来识别日志中的数据,可以把Grok插件简单理解为升级版本的正则表达式.它拥有更多的模式,默认,Logstash拥有120个模式.如果这些模式不满足我们解析日志 ...
- 在 Linux 中找出内存消耗最大的进程
1 使用 ps 命令在 Linux 中查找内存消耗最大的进程 ps 命令用于报告当前进程的快照.ps 命令的意思是"进程状态".这是一个标准的 Linux 应用程序,用于查找有关在 ...
- Handler机制与生产者消费者模式
本文梳理了 Handler 的源码,并详细阐述了 Handler 与生产者消费者模式的关系,最后给出了多版自定义 Handler 实现.本文首发于简书,重新整理发布. 一.Handler Handle ...
- C++自学笔记 构造与析构;
构造与析构 类不是实体:对象属于类:函数属于类 : 用不同的对象调用同一个类里面的函数的时候,函数知道是哪一个对象在调用它 关键字 this this是一个指针 Point a; a.print(); ...
- 基于Qt Designer和PyQt5的桌面软件开发--环境搭建和入门例子
本文介绍了如何使用技术栈PyCharm+Qt Designer+PyQt5来开发桌面软件,从环境搭建.例子演示到对容易混淆概念的解释.文中用到的全部软件+代码下载链接为:https://url39 ...
- P4556 [Vani有约会]雨天的尾巴 /【模板】线段树合并 (树上差分+线段树合并)
显然的树上差分问题,最后要我们求每个点数量最多的物品,考虑对每个点建议线段树,查询子树时将线段树合并可以得到答案. 用动态开点的方式建立线段树,注意离散化. 1 #include<bits/st ...