Prometheus高可用部署
Prometheus的本地存储给Prometheus带来了简单高效的使用体验,可以让Promthues在单节点的情况下满足大部分用户的监控需求。但是本地存储也同时限制了Prometheus的可扩展性,带来了数据持久化等一系列的问题。通过Prometheus的Remote Storage特性可以解决这一系列问题,包括Promthues的动态扩展,以及历史数据的存储。
而除了数据持久化问题以外,影响Promthues性能表现的另外一个重要因素就是数据采集任务量,以及单台Promthues能够处理的时间序列数。因此当监控规模大到Promthues单台无法有效处理的情况下,可以选择利用Promthues的联邦集群的特性,将Promthues的监控任务划分到不同的实例当中。
基本HA:服务可用性
由于Promthues的Pull机制的设计,为了确保Promthues服务的可用性,用户只需要部署多套Prometheus Server实例,并且采集相同的Exporter目标即可。
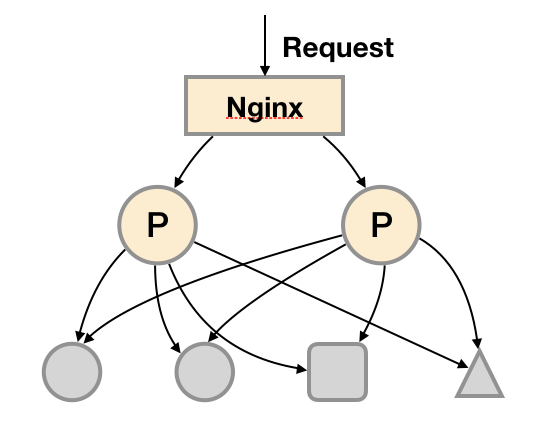
基本的HA模式只能确保Promthues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
基本HA + 远程存储
在基本HA模式的基础上通过添加Remote Storage存储支持,将监控数据保存在第三方存储服务上。
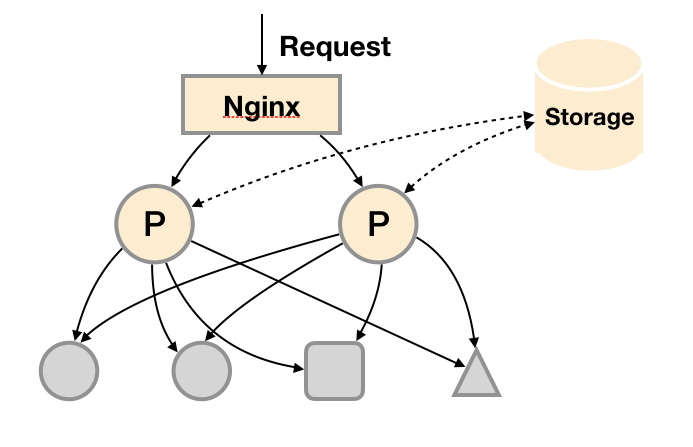
在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景。
基本HA + 远程存储 + 联邦集群
当单台Promthues Server无法处理大量的采集任务时,用户可以考虑基于Prometheus联邦集群的方式将监控采集任务划分到不同的Promthues实例当中即在任务级别功能分区。
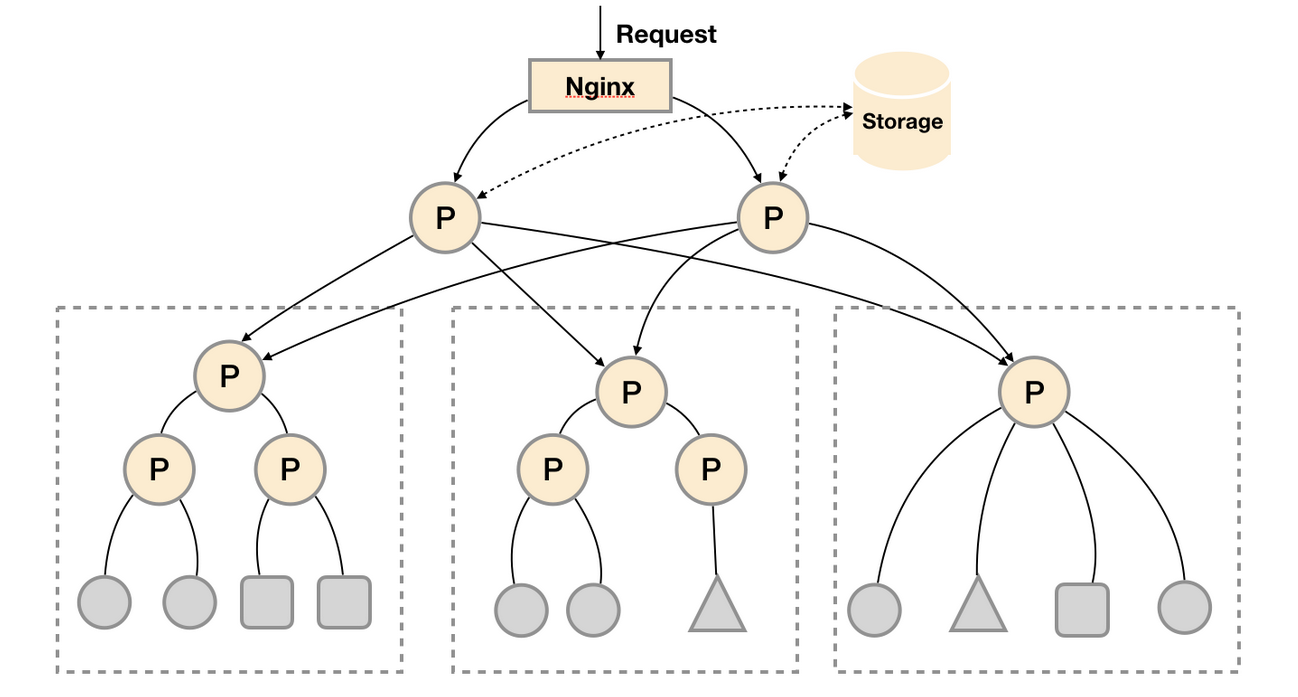
这种部署方式一般适用于两种场景:
场景一:单数据中心 + 大量的采集任务
这种场景下Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
场景二:多数据中心
这种模式也适合与多数据中心的情况,当Promthues Server无法直接与数据中心中的Exporter进行通讯时,在每一个数据中部署一个单独的Promthues Server负责当前数据中心的采集任务是一个不错的方式。这样可以避免用户进行大量的网络配置,只需要确保主Promthues Server实例能够与当前数据中心的Prometheus Server通讯即可。 中心Promthues Server负责实现对多数据中心数据的聚合。
按照实例进行功能分区
这时在考虑另外一种极端情况,即单个采集任务的Target数也变得非常巨大。这时简单通过联邦集群进行功能分区,Prometheus Server也无法有效处理时。这种情况只能考虑继续在实例级别进行功能划分。
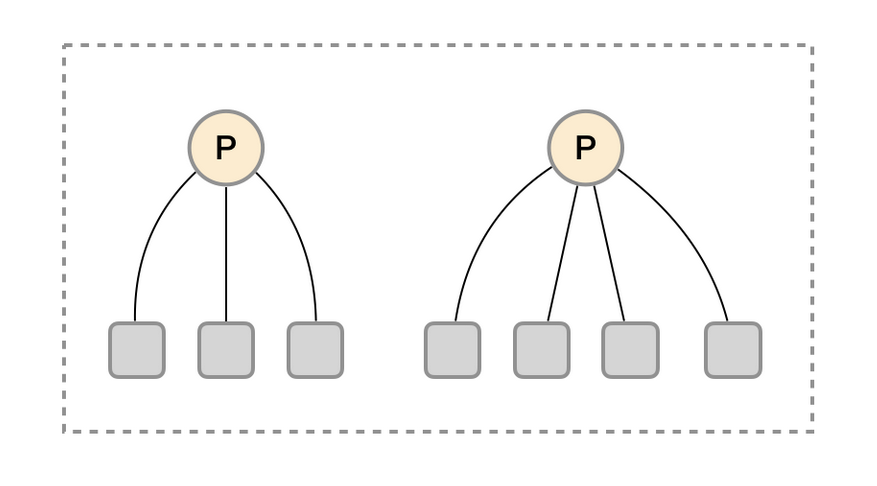
如上图所示,将统一任务的不同实例的监控数据采集任务划分到不同的Prometheus实例。通过relabel设置,我们可以确保当前Prometheus Server只收集当前采集任务的一部分实例的监控指标。
global:
external_labels:
slave: 1 # This is the 2nd slave. This prevents clashes between slaves.
scrape_configs:
- job_name: some_job
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
并且通过当前数据中心的一个中心Prometheus Server将监控数据进行聚合到任务级别。
- scrape_config:
- job_name: slaves
honor_labels: true
metrics_path: /federate
params:
match[]:
- '{__name__=~"^slave:.*"}' # Request all slave-level time series
static_configs:
- targets:
- slave0:9090
- slave1:9090
- slave3:9090
- slave4:9090
高可用方案选择
上面的部分,根据不同的场景演示了3种不同的高可用部署方案。当然对于Promthues部署方案需要用户根据监控规模以及自身的需求进行动态调整,下表展示了Promthues和高可用有关3个选项各自解决的问题,用户可以根据自己的需求灵活选择。
| 选项\需求 | 服务可用性 | 数据持久化 | 水平扩展 |
|---|---|---|---|
| 主备HA | v | x | x |
| 远程存储 | x | v | x |
| 联邦集群 | x | x | v |
Prometheus高可用部署的更多相关文章
- kubernetes 1.15.1 高可用部署 -- 从零开始
这是一本书!!! 一本写我在容器生态圈的所学!!! 重点先知: 1. centos 7.6安装优化 2. k8s 1.15.1 高可用部署 3. 网络插件calico 4. dashboard 插件 ...
- Kubernetes 监控--Prometheus 高可用: Thanos
前面我们已经学习了 Prometheus 的使用,了解了基本的 PromQL 语句以及结合 Grafana 来进行监控图表展示,通过 AlertManager 来进行报警,这些工具结合起来已经可以帮助 ...
- kubernetes1.7.6 ha高可用部署
写在前面: 1. 该文章部署方式为二进制部署. 2. 版本信息 k8s 1.7.6,etcd 3.2.9 3. 高可用部分 etcd做高可用集群.kube-apiserver 为无状态服务使用hap ...
- NoSQL数据库Mongodb副本集架构(Replica Set)高可用部署
NoSQL数据库Mongodb副本集架构(Replica Set)高可用部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. MongoDB 是一个基于分布式文件存储的数据库.由 C ...
- LVS+Keepalived高可用部署
一.LVS+Keepalived高可用部署 一.keepalived节点部署 1.安装keepalived yum install keepalived ipvsadm -y mkdir -p /op ...
- Rancher Server HA的高可用部署实验-学习笔记
转载于https://blog.csdn.net/csdn_duomaomao/article/details/78771731 Rancher Server HA的高可用部署实验-学习笔记 一.机器 ...
- eql高可用部署方案
运行环境 服务器两台(后面的所有配置案例都是以10.96.0.64和10.96.0.66为例) 操作系统CentOS release 6.2 必须要有共同的局域网网段 两台服务器都要安装keepali ...
- MooseFS及其高可用部署
MooseFS的工作原理分析 MooseFS(下面统一称为MFS)由波兰公司Gemius SA于2008年5月30日正式推出的一款Linux下的开源存储系统,是OpenStack开源云计算项目的子项目 ...
- Redis高可用部署及监控
Redis高可用部署及监控 目录 一.Redis Sentinel简介 二.硬件需求 三.拓扑结构 .单M-S结构 .双M-S结构 .优劣对比 四.配置部 ...
随机推荐
- 新版recon-ng安装模块
表现:进入后报[*] No modules enabled/installed. 1.直接在recon-ng控制台输入marketplace install all,用来下载所有插件,如果不可以,往下 ...
- idea 内置tomcat jersey 上传文件报403错误
Request processing failed; nested exception is com.sun.jersey.api.client.UniformInterfaceException: ...
- 适用于MES、WMS、ERP等管理系统的实体下拉框设计
场景 该设计多适用于MES,ERP,WMS 等管理类型的项目. 在做管理类型项目的时候,前端经常会使用到下拉框,比如:设备,工厂等等.下拉组件中一般只需要他们的ID,Name属性,而这些数据都创建于其 ...
- Collection集合汇总
Collectioin(java) Collection简介 打开帮助文档 java.utill //使用时需要导包 Interface Collection 集合层次结构中的根界面 . 集合表示一组 ...
- SQLServer从入门基础
1.数据库管理工具 工具创建数据库 1>登录数据库管理工具[Microsoft SQL Server Management Studio] 2>右键[新建数据库] 3>数据数据库名称 ...
- 主线程和创建多线程程序的第一种方式_创建Thread类的子类
/** * 主线程:执行主方法的线程(main) * 单线程程序:在java程序中只有一个线程 * 执行从main方法开始,从上倒下依次执行 */ public class Demo01MainThr ...
- Linux—文件系统结构
1.文件目录结构 /:是Linux系统的根目录 /bin:存放用户经常使用的命令 /boot:启动加载程序的静态文件 /dev:设备文件目录,不能单独分区 /etc:系统配置文件目录 /home:普通 ...
- 不安装运行时运行.NET程序
好久没写文章了,有些同学问我公众号是不是废了?其实并没有.其实想写的东西很多很多,主要是最近公司比较忙,以及一些其他个人原因没有时间来更新文章.这几天抽空写了一点点东西,证明公众号还活着. 长久以来的 ...
- 5.27 NOI 模拟
\(T1\)约定 比较水的\(dp\)题 上午想到了用区间\(dp\)求解,复杂度\(O(n^5),\)貌似没开\(long\ long\)就爆掉了 正解还是比较好想的,直接枚举从何时互不影响然后转移 ...
- 重构、插件化、性能提升 20 倍,Apache DolphinScheduler 2.0 alpha 发布亮点太多!
点击上方 蓝字关注我们 社区的小伙伴们,好消息!经过 100 多位社区贡献者近 10 个月的共同努力,我们很高兴地宣布 Apache DolphinScheduler 2.0 alpha 发布.这是 ...