Hadoop单节点启动分布式伪集群
emm~ 写这篇博客只是手痒,因为开发环境用单节点就够了,生产环境肯定是真实集群,所以这个伪分布式纯属娱乐而已。
配置HDFS
1. 安装好一台hadoop,可以参考这篇博客。
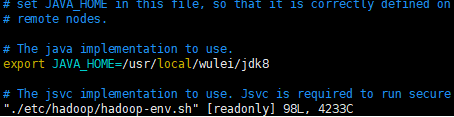
2. 在hadoop目录下编辑文件指定java环境变量 vim ./etc/hadoop/hadoop-env.sh
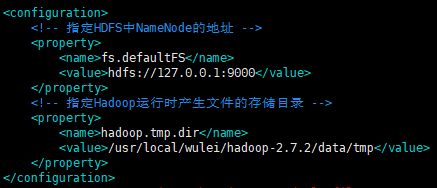
3.指定hdfs存储位置和地址 vim etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/wulei/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
core-site.xml
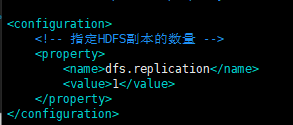
4. 指定hdsf副本数量 vim etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
hdfs-site.xml
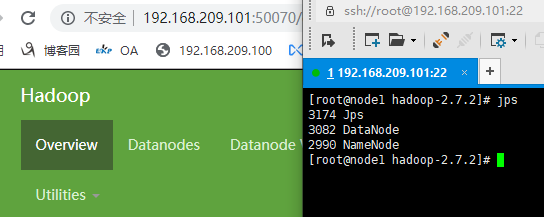
启动集群
(a)格式化NameNode(第一次启动时格式化会生成刚刚指定的data目录,以后就不要总格式化。格式化会让集群找不到已往数据datanode启动失败,所以一定要先删除data文件夹和log文件夹,然后再格式化)
[root@node1 hadoop-2.7.2]# bin/hdfs namenode -format
(b)启动NameNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode
(c)启动DataNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
jps查看节点启动状态
配置YARN
1.指定环境变量 vim etc/hadoop/yarn-env.sh

2.配置环境变量 vim etc/hadoop/mapred-env.sh

3.配置(node1是当前主机名,可以 vim /etc/hosts 指定) vim etc/hadoop/yarn-site.xml
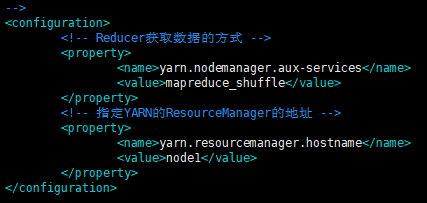
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
yarn-site.xml
4.将mapred-site.xml.template重新命名为 mapred-site.xml
[wulei@node1 hadoop-2.7.2]$ sudo cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[wulei@node1 hadoop-2.7.2]$ sudo vim etc/hadoop/mapred-site.xml <configuration>
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapred-site.xml

启动集群
1. 启动前必须保证NameNode和DataNode已经启动
[root@node1 hadoop-2.7.2]# jps
12133 NameNode
12203 DataNode
12303 Jps
2. 启动ResourceManager
[root@node1 hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /usr/local/wulei/hadoop-2.7.2/logs/yarn-root-resourcemanager-node1.out
3. 启动NodeManager
[root@node1 hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /usr/local/wulei/hadoop-2.7.2/logs/yarn-root-nodemanager-node1.out
[root@node1 hadoop-2.7.2]# jps
12609 NodeManager
12371 ResourceManager
12133 NameNode
12203 DataNode
12750 Jps
[root@node1 hadoop-2.7.2]#
Hadoop单节点启动分布式伪集群的更多相关文章
- Zookeeper集群搭建(多节点,单机伪集群,Docker集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- windows单节点下安装es集群
linux下的es的tar包,拖到windows下,配置后,启动bin目录下的bat文件,也是可以正常运行的. 从linux下拷的tar包,需要修改虚拟机的内存elasticsearch.in.bat ...
- Kafka 单节点多Kafka Broker集群
Kafka 单节点多Kafka Broker集群 接前一篇文章,今天搭建一下单节点多Kafka Broker集群环境. 配置与启动服务 由于是在一个节点上启动多个 Kafka Broker实例,所以我 ...
- redhat6.5 redis单节点多实例3A集群搭建
在进行搭建redis3M 集群之前,首先要明白如何在单节点上完成redis的搭建. 单节点单实例搭建可以参看这个网:https://www.cnblogs.com/butterflies/p/9628 ...
- 利用shell脚本[带注释的]部署单节点多实例es集群(docker版)
文章目录 目录结构 install_docker_es.sh elasticsearch.yml.template 没事写写shell[我自己都不信,如果不是因为工作需要,我才不要写shell],努力 ...
- Zookeeper集群搭建(单机多节点,伪集群,docker-compose集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- Zookeeper详解-伪分布式和集群搭建(八)
说到分布式开发Zookeeper是必须了解和掌握的,分布式消息服务kafka .hbase 到hadoop等分布式大数据处理都会用到Zookeeper,所以在此将Zookeeper作为基础来讲解. Z ...
- zookeeper的单实例和伪集群部署
原文链接: http://gudaoyufu.com/?p=1395 zookeeper工作方式 ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现 ...
- hadoop 2.5.1单机安装部署伪集群
环境:ubuntu 14.04 server 64版本 hadoop 2.5.1 jdk 1.6 部署的步骤主要参考了http://blog.csdn.net/greensurfer/article/ ...
随机推荐
- NetScaler VPX configration
境搭建概述 本文主要介绍Netscaler的安装配置,以及与StoreFront相结合,实现外网访问内网资源.当用户访问时,Netscaler Gateway Virtual Server将把请求转给 ...
- LeetCode 105. 从前序与中序遍历序列构造二叉树(Construct Binary Tree from Preorder and Inorder Traversal)
题目描述 根据一棵树的前序遍历与中序遍历构造二叉树. 注意:你可以假设树中没有重复的元素. 例如,给出 前序遍历 preorder = [3,9,20,15,7] 中序遍历 inorder = [9, ...
- 【好书推荐】9、安卓Andorid编程吐血整理100+本
点开即可
- iOS真机调试之免费预配(Free provisioning)
免费预配允许开发者在不加入Applec Developer Program的情况下,可以发布和测试App 注意:免费预配(Free Provisioning)与自动预配(Auto Provisioni ...
- The remote system refused the connection.
使用SecureCRT连接Ubuntu时,报错: The remote system refused the connection. 说明Ubuntu上没有安装openssh-server,使用命令: ...
- 2.HDFS和HA
1.HDFS简介 DataNode NameNode SecondaryNameNode HDFS文件权限 2.HDFS小结 3.HDFS交互操作 4.HDFS编程访问接口
- maven 打包异常
异常信息: [ERROR] Failed to execute goal org.springframework.boot:spring-boot-maven-plugin:2.1.6.RELEASE ...
- oracle 导出关键字说明
关键字 说明(默认) ----------------------------------------- UserId 用户名/口令 Full 导出整个文件(N) Buff ...
- Ceph 分布式存储架构解析与工作原理
目录 文章目录 目录 Ceph 简介 Ceph 的架构:分布式服务进程 Ceph Monitor(MON) Ceph Object Storage Device Daemon(OSD) Ceph Me ...
- 【转载】如何在 Kaggle 首战中进入前 10%
本文转载自如何在 Kaggle 首战中进入前 10% 转载仅出于个人学习收藏,侵删 Introduction 本文采用署名 - 非商业性使用 - 禁止演绎 3.0 中国大陆许可协议进行许可.著作权由章 ...