2. An Array of Sequences
1. Overview of Built-In Sequences
- Container sequences: list, tuple, and collections.deque can hold items of different types.
- Flat sequences: str, bytes, bytearray, memoryview, and array.array hold items of one type.
- Mutable sequences: list, bytearray, array.array, collections.deque, and memoryview.
- Immutable sequences: tuple, str, and bytes.
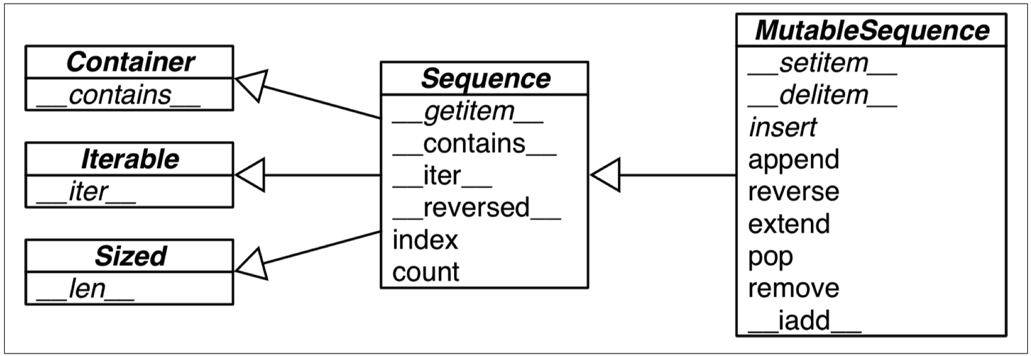
[Notes]: The built-in concrete sequence types do not actually subclass the Sequence and MutableSequence abstract base classes (ABCs) depicted, but the ABCs are still useful as a formalization of what functionality to expect from a full-featured sequence type.
2. List Comprehensions and Generator Expressions
2.1 List Comprehensions
a = 1
t = [a for a in range(9)] #
# print a # 8 (run in python 2.7)
print(a) # 1 (run in python 3) # 1. List comprehensions, generator expressions, and their siblings set
# and dict compre‐hensions now have their own local scope, like functions. t1 = [(i, j) for i in i_list for j in j_list]
t2 = [i for i in range(5) if i > 2]
2.2 Generator Expressions
- Genexp saves memory because it yields items one by one using the iterator protocol instead of building a whole list just to feed another constructor.
for item in ('%s %s' % (i, j) for i in i_list for j in j_list):
print(item)
[Notes]: In Python code, line breaks are ignored inside pairs of [], {}, or (). So you can build multiline without using \ .
3. Tuples Are Not Just Immutable Lists
- Tuples do double duty: they can be used as immutable lists and also as records with no field names.
- Tuples hold records: each item in the tuple holds the data for one field and the position of the item gives its meaning.
3.1 Tuple Unpacking
b, a = a, b
add(*(3, 4))
_, t = (3, 4) # A dummy variable
t, _ = (3, 4) # Not a good dummy variable
a, *rest = [1,] # rest = []
*rest, a = range(3) # rest = [0, 1]
a, b, (c, d) = (1, 2, (3, 4)) # 1. Before Python 3, it was possible to define functions with nested
# tuples in the formal parameters (e.g., def fn(a, (b, c), d):).
# This is no longer supported in Python 3 function definitions,
3.2 Named Tuples
- Instances of a class that you build with namedtuple take exactly the same amount of memory as tuples because the field names are stored in the class. They use less memory than a regular object because they don’t store attributes in a per-instance __dict__.
from collections import namedtuple
# A class name and a list of field names, which can be given
# as an iterable of strings or as a single space-delimited string.
City = namedtuple('City', 'name country population coordinates')
tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
print tokyo.population # 36.933
print tokyo[0] # Tokyo
print City._fields # ('name', 'country', 'population', 'coordinates')
tmp = City._make("1234") # iterable
print tmp # City(name='1', country='2', population='3', coordinates='4')
print tmp._asdict()['country'] # 2
print tmp._asdict().values() # ['1', '2', '3', '4']
3.3 Tuples as Immutable Lists
- Tuple supports all list methods that do not involve adding or removing items, with one exception—tuple lacks the __reversed__ method. However, that is just for optimization; reversed(my_tuple) works without it.


4. Slicing
4.1 Why Slices and Range Exclude the Last Item
- It’s easy to see the length of a slice or range when only the stop position is given. (a[:3])
- It’s easy to compute the length of a slice or range when start and stop are given. (a[1: 5])
- It’s easy to split a sequence in two parts at any index x, without overlapping. (a[:3] / a[3:])
4.2 Slice Objects
s = 'bicycle'
print s[::3] # bye
print s[::-1] # elcycib # seq[start:stop:step] -> seq.__getitem__(slice(start, stop, step))
invoice = """
0.....6.................................40........52...55........
1909 Pimoroni PiBrella $17.50 3 $52.50
1489 6mm Tactile Switch x20 $4.95 2 $9.90
1510 Panavise Jr. - PV-201 $28.00 1 $28.00
"""
DESCRIPTION = slice(6, 40) # assign names to slices
line_items = invoice.split('\n')[2:]
for item in line_items:
print item[DESCRIPTION] # Pimoroni PiBrella # Mutable sequences can be grafted, excised, modified in place using slice
l = list(range(5))
l[0:2] = [9]
# l[0:2] = 1 # TypeError: can only assign an iterable
print l # [9, 2, 3, 4]
del l[0:2]
print l # [3, 4]
l[::-1] = [11, 22]
print l # [22, 11]
5. Using + and * with Sequences
l = [1, 2, 3]
print l * 2 # [1, 2, 3, 1, 2, 3] # Both + and * always create a new object, and never change their operands
board = [['_'] * 3 for i in range(3)]
board[1][2] = 'X'
print board # [['_', '_', '_'], ['_', '_', 'X'], ['_', '_', '_']]
# board = []
# for i in range(3):
# row = ['_'] * 3
# board.append(row)
weird_board = [['_'] * 3] * 3
weird_board[1][2] = 'X'
print weird_board # [['_', '_', 'X'], ['_', '_', 'X'], ['_', '_', 'X']]
# row = ['_'] * 3
# board = []
# for i in range(3):
# board.append(row)
6. Augmented Assignment with Sequences
- The special method that makes += work is __iadd__ (for “in-place addition”). However, if __iadd__ is not implemented, Python falls back to calling __add__.
- If a implements __iadd__, that will be called. In the case of mutable sequences, a will be changed in place (i.e., the effect will be similar to a.extend(b)). However, when a does not implement __iadd__, the expression a += b has the same effect as a = a + b: the expression a + b is evaluated first, producing a new object, which is then bound to a.
l = [1, 2, 3]
t = (1, 2, 3)
print id(l) # 4517558248
print id(t) # 4452583856
l *= 2
t *= 2
print id(l) # 4517558248
print id(t) # 4452506128 # >>> t = (1, 2, [30, 40])
# >>> t[2] += [50, 60]
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'tuple' object does not support item assignment
# >>> t
# (1, 2, [30, 40, 50, 60]) # Put s[a] on TOS (Top Of Stack).
# Perform TOS += b.
# Assign s[a] = TOS. # -> Augmented assignment is not an atomic operation
7. list.sort and the sorted Built-In Function
- The list.sort method sorts a list in place—that is, without making a copy. It returns None to remind us that it changes the target object, and does not create a new list.
- In contrast, the built-in function sorted creates a new list and returns it. In fact, it accepts any iterable object as an argument, including immutable sequences and gener‐ators. Regardless of the type of iterable given to sorted, it always returns a newly created list.
- reverse: If True, the items are returned in descending order. The default is False.
- key: A one-argument function that will be applied to each item to produce its sorting key.
fruits = ['grape', 'raspberry', 'apple', 'banana']
print sorted(fruits) # ['apple', 'banana', 'grape', 'raspberry']
print fruits # ['grape', 'raspberry', 'apple', 'banana']
print fruits.sort() # None
print fruits # ['apple', 'banana', 'grape', 'raspberry']
print sorted(fruits, key=len) # ['apple', 'grape', 'banana', 'raspberry']
print sorted(fruits, reverse=True, key=len) # ['raspberry', 'banana', 'apple', 'grape']
# It is not the reverse of the previous result because the sorting is stable
8. Managing Ordered Sequences with bisect
- bisect(haystack, needle) does a binary search for needle in haystack—which must be a sorted sequence—to locate the position where needle can be inserted while main‐taining haystack in ascending order.
- You could use the result of bisect(haystack, needle) as the index argument to haystack.insert(index, needle)—however, using insort does both steps, and is faster.
import bisect a = [1, 3, 5]
idx = bisect.bisect(a, 2)
a.insert(idx, 2)
print a # [1, 2, 3, 5] def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):
i = bisect.bisect(breakpoints, score)
return grades[i]
print [grade(score) for score in [33, 66, 100]] # ['F', 'D', 'A'] bisect.insort(a, 4)
print a # [1, 2, 3, 4, 5] # 1. Once your sequences are sorted, they can be very efficiently searched.
# 2. Their difference between bisect(bisect_right) and bisect_left is apparent
# only when the needle compares equal to an item in the list.
# 3. so is insort_left
9. When a List Is Not the Answer
9.1 Arrays
- An array does not actually hold full-fledged float objects, but only the packed bytes representing their machine values—just like an array in the C language.
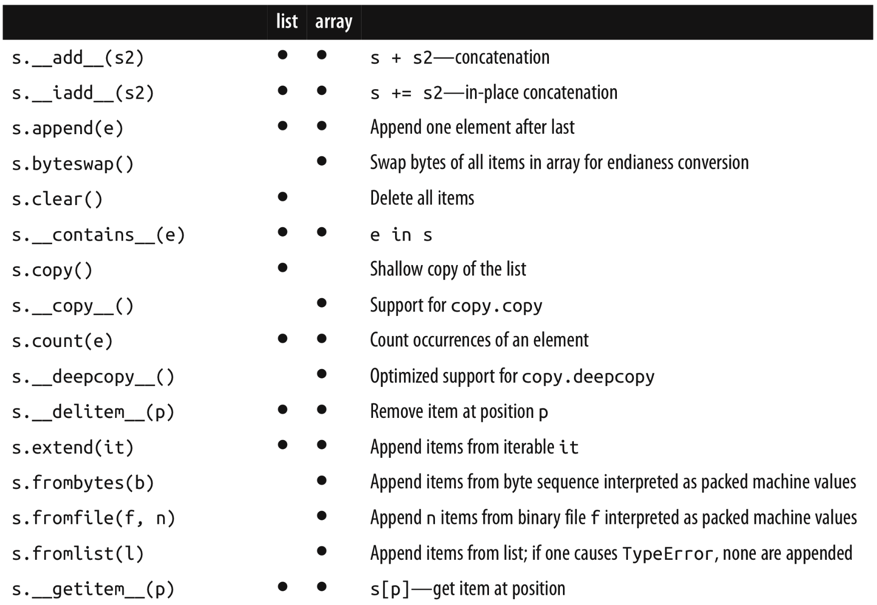
- If the list will only contain numbers, an array.array is more efficient than a list: it supports all mutable sequence operations (including .pop, .insert, and .extend), and additional methods for fast loading and saving such as .frombytes and .tofile.
- When creating an array, you provide a typecode, a letter to determine the underlying C type used to store each item in the array. For example, b is the typecode for signed char. If you create an array('b'), then each item will be stored in a single byte and interpreted as an integer from -128 to 127.
from array import array
from random import random
floats = array('d', (random() for i in range(10**7))) # iterable
print floats[-1] # 0.741274710798 fp = open('floats.bin', 'wb')
floats.tofile(fp)
fp.close() floats2 = array('d')
fp = open('floats.bin', 'rb')
floats2.fromfile(fp, 10**7)
fp.close()
print floats2[-1] # 0.741274710798 print floats == floats2 # True
[Notes]: Another fast and more flexible way of saving numeric data is the pickle module for object serialization. Saving an array of floats with pickle.dump is almost as fast as with array.tofile—how‐ever, pickle handles almost all built-in types, including complex numbers, nested collections, and even instances of user-defined classes automatically (if they are not too tricky in their implemen‐tation).

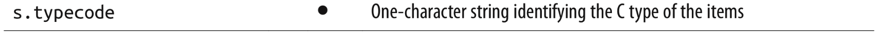
9.2 Memory Views
- The built-in memorview class is a shared-memory sequence type that lets you handle slices of arrays without copying bytes.
- A memoryview is essentially a generalized NumPy array structure in Python itself (without the math). It allows you to share memory between data-structures (things like PIL images, SQLlite databases, NumPy arrays, etc.) without first copying. This is very important for large data sets.
import array
numbers = array.array('h', [-2, -1, 0, 1, 2]) # short signed integers
memv = memoryview(numbers)
print(len(memv)) # 5
print(memv[0]) # -2 memv_oct = memv.cast('B') # unsigned char
print(memv_oct.tolist()) # [254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
memv_oct[5] = 4
print(numbers) # array('h', [-2, -1, 1024, 1, 2]) # 1. The memoryview.cast method lets you change the way multiple bytes
# are read or written as units without moving bits around. It returns
# yet another memoryview object, always sharing the same memory.
9.3 NumPy and SciPy
- NumPy implements multi-dimensional, homogeneous arrays and matrix types that hold not only numbers but also user-defined records, and provides efficient elementwise operations.
- SciPy is a library, written on top of NumPy, offering many scientific computing algo‐rithms from linear algebra, numerical calculus, and statistics. SciPy is fast and reliable because it leverages the widely used C and Fortran code base from the Netlib Reposi‐tory. In other words, SciPy gives scientists the best of both worlds: an interactive prompt and high-level Python APIs, together with industrial-strength number-crunching func‐tions optimized in C and Fortran.
9.4 Deques and Other Queues
- The class collections.deque is a thread-safe double-ended queue designed for fast inserting and removing from both ends. It is also the way to go if you need to keep a list of “last seen items” or something like that, because a deque can be bounded—i.e., created with a maximum length—and then, when it is full, it discards items from the opposite end when you append new ones.
- The append and popleft operations are atomic, so deque is safe to use as a LIFO queue in multithreaded applications without the need for using locks.
from collections import deque
dq = deque(range(10), maxlen=10)
print dq # deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
dq.rotate(3)
print dq # deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
dq.appendleft(-1)
print dq # deque([-1, 7, 8, 9, 0, 1, 2, 3, 4, 5], maxlen=10)
dq.extend([11, 22, 33])
print dq # deque([9, 0, 1, 2, 3, 4, 5, 11, 22, 33], maxlen=10)
dq.extendleft([10, 20, 30, 40])
print dq # deque([40, 30, 20, 10, 9, 0, 1, 2, 3, 4], maxlen=10)


- Besides deque, other Python standard library packages implement queues:
- queue
- multiprocessing
- asyncio
- heapq
2. An Array of Sequences的更多相关文章
- 《流畅的Python》Data Structures--第2章序列array
第二部分 Data Structure Chapter2 An Array of Sequences Chapter3 Dictionaries and Sets Chapter4 Text vers ...
- python常用序列list、tuples及矩阵库numpy的使用
近期开始学习python机器学习的相关知识,为了使后续学习中避免编程遇到的基础问题,对python数组以及矩阵库numpy的使用进行总结,以此来加深和巩固自己以前所学的知识. Section One: ...
- numpy基本用法
numpy 简介 numpy的存在使得python拥有强大的矩阵计算能力,不亚于matlab. 官方文档(https://docs.scipy.org/doc/numpy-dev/user/quick ...
- numpy快速指南
Quickstart tutorial 引用https://docs.scipy.org/doc/numpy-dev/user/quickstart.html Prerequisites Before ...
- Leetcode:Repeated DNA Sequences详细题解
题目 All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: " ...
- ValueError: setting an array element with a sequence.
http://blog.csdn.net/pipisorry/article/details/48031035 From the code you showed us, the only thing ...
- [Swift]LeetCode187. 重复的DNA序列 | Repeated DNA Sequences
All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: "ACG ...
- Kotlin系列之序列(Sequences)源码完全解析
Kotlin系列之序列(Sequences)源码完全解析 2018年06月05日 22:04:50 mikyou 阅读数:179 标签: Kotlin序列(sequence)源码解析Androidja ...
- Array Product(模拟)
Array Product http://codeforces.com/problemset/problem/1042/C You are given an array aa consisting o ...
随机推荐
- ldap客户端工具ldap admin tool
官网下载:非免费软件,自己破解 http://www.ldapbrowsermac.com/
- OpenGL(5)——变换
学习三种变换:Scaling, Rotation和Translation. 上学期修了Kobbelt教授(男神!)的图形学基础课,这部分内容已经接触过. 添加GLM库,直接给出齐次坐标系下的变换矩阵和 ...
- 获取Xshell Xftp等官网下载地址
1. 首先还是得填写邮箱获取试用链接地址,例如我这次获取的是: https://cdn.netsarang.net/c5711331/Xshell-6.0.0175.exe 关键需要记下 c57113 ...
- 【Qt开发】关于QWSServer
QWS Server QT Embeded应用没有来严格的区分server和client进程,如果一个QT进程的启动参数中有-qws,那么这个进程就具有server管理功能,被称为QWS server ...
- 【记录】编译安装 YAML 扩展
转自:https://learnku.com/articles/30985 Yaml,专门用来写配置文件的语言 依赖安装 $ sudo apt-get install libyaml-dev ...
- 日常工作问题解决:记一次centos7上的lvm表错误解决过程
问题描述: 公司大数据hadoop2服务器采用电信云服务器,后来故障,电信恢复该服务器,需要重新部署程序,需要扩展lvm分区,但是使用pvsan命令发现有报错信息,需要解决以防重启后,因挂载问题,无法 ...
- 一个memset导致的血案
本文记录解答MIT 6.828 Lab 1 Exercise 10时遇到的一个Bug. 问题描述 在i386_init入口处设置断点并运行,发现执行memset(edata, 0, end - eda ...
- The Maze II
There is a ball in a maze with empty spaces and walls. The ball can go through empty spaces by rolli ...
- storm group 的介绍与使用
一.stream group分组介绍 Stream 的分组分为随机分组.字段分组.全部分组.全局分组.无分组.直接分组,自定义分组 二.group的介绍 1.Shuffle grouping:通过tu ...
- 【AtCoder】ARC059
为啥这场ARC那么水--一个点就切完了 ARC059 C - いっしょ / Be Together 枚举就行 #include <bits/stdc++.h> #define fi fir ...