hadoop yarn日志分离
根据hdfs的auditlog以及fsimage分析,yarn的日志文件占用了10%-20%的rpc请求以及文件量,这对namenode的性能有比较大的影响,特别是当集群规模越来越大,会影响生产业务。故下面的方案对yarn日志进行拆分,将日志写入一个独立的hdfs集群
运行yarn的集群(pascdev),日志写入集群(pasc)
一、 配置
hdfs-site.xml
//添加日志写入集群的nameservice
<property>
<name>dfs.nameservices</name>
<value>pascdev,pasc</value>
</property>
//添加日志写入集群的rpc端口
<property>
<name>dfs.ha.namenodes.pasc</name>
<value>CDM01,CDM02</value>
</property>
<property>
<name>dfs.namenode.rpc-address.pasc.CDM01</name>
<value>CDM01.qa.pab.com.cn:8020</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.pasc.CDM01</name>
<value>CDM01.qa.pab.com.cn:8021</value>
</property>
<property>
<name>dfs.namenode.rpc-address.pasc.CDM02</name>
<value>CDM02.qa.pab.com.cn:8020</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.pasc.CDM02</name>
<value>CDM02.qa.pab.com.cn:8021</value>
</property>
//添加日志集群的client.failover.proxy
<property>
<name>dfs.client.failover.proxy.provider.pasc</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
//为防止datanode向日志集群的namenode执行块汇报,添加以下配置
<property>
<name>dfs.internal.nameservices</name>
<value>pascdev</value>
</property>
yarn-site.xml
//修改Yarn日志路径
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>hdfs://pasc/metadata/logs/remoteyarn</value>
</property>
二、 部署相关Patch
(1)修改以上配置,重启hadoop服务后,报以下错误

原因是现有的版本不支持跨ns的日志聚合操作,部署Patch Yarn-3269
(2)解决跨ns问题后,再次重启服务,报以下错误,提示rpc认证错误

查看源码发现是在logaggragationservice的initappaggregator方法中获取用户的credential
通过打印日志,获取了Nodemananger在进行日志聚合操作时所持有的tokens,发现并没有集群pasc的HDFS_DELEGATION_TOKEN

通过添加代码修改这个问题:
credentials = new Credentials();
FileSystem remoteFs = getFileSystem(getconfig());
remoteFs.addDelegationTokens(UserGroupInformation.getLoginUser().getshortname(),credentials)
可以看到已经获取集群pasc的HDFS_DELEGATION_TOKEN

三、测试
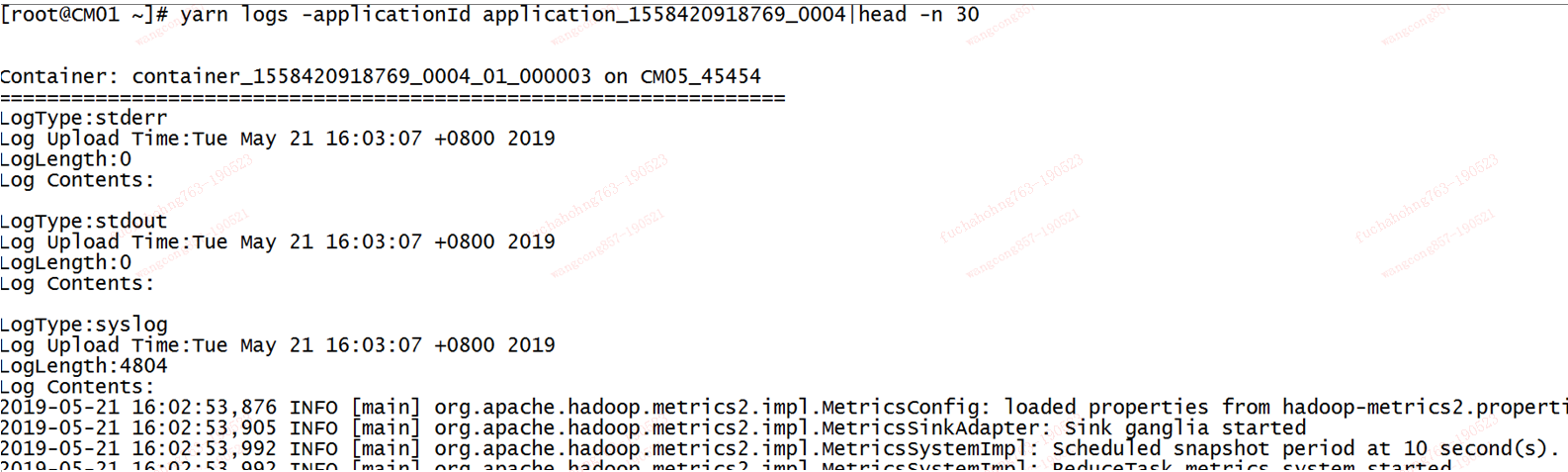
可以看到pasc集群上已经有该app执行的日志

同时可以在pascdev集群上通过yarn logs命令查看日志
hadoop yarn日志分离的更多相关文章
- Hadoop基础-完全分布式模式部署yarn日志聚集功能
Hadoop基础-完全分布式模式部署yarn日志聚集功能 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 其实我们不用配置也可以在服务器后台通过命令行的形式查看相应的日志,但为了更方 ...
- hadoop yarn
简介: 本文介绍了 Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理,优势,运作机制和配置方法等:着重介绍新的 yarn 框架相对于原框架的差异及改进:并通过 ...
- Hadoop - YARN 概述
一 概述 Apache Hadoop YARN (Yet Another Resource Negotiator,还有一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源 ...
- Hive分析hadoop进程日志
想把hadoop的进程日志导入hive表进行分析,遂做了以下的尝试. 关于hadoop进程日志的解析 使用正则表达式获取四个字段,一个是日期时间,一个是日志级别,一个是类,最后一个是详细信息, 然后在 ...
- Hadoop YARN配置参数剖析—RM与NM相关参数
注意,配置这些参数前,应充分理解这几个参数的含义,以防止误配给集群带来的隐患.另外,这些参数均需要在yarn-site.xml中配置. 1. ResourceManager相关配置参数 (1) ...
- Hadoop yarn配置参数
参照site:http://hadoop.apache.org/docs/r2.6.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml 我们在配置yar ...
- Hadoop YARN ERROR 1/1 local-dirs are bad *, 1/1 log-dirs are bad *
转 http://blog.csdn.net/u012303571/article/details/46913471 查看 nodemanager 日志发下 如下信息 2015-07-16 1 ...
- Hadoop Yarn 安装
环境:Linux, 8G 内存.60G 硬盘 , Hadoop 2.2.0 为了构建基于Yarn体系的Spark集群.先要安装Hadoop集群,为了以后查阅方便记录了我本次安装的详细步骤. 事前准备 ...
- [BigData - Hadoop - YARN] YARN:下一代 Hadoop 计算平台
Apache Hadoop 是最流行的大数据处理工具之一.它多年来被许多公司成功部署在生产中.尽管 Hadoop 被视为可靠的.可扩展的.富有成本效益的解决方案,但大型开发人员社区仍在不断改进它.最终 ...
随机推荐
- z-index神奇的失效了!!!
z-index简单介绍 首先z-index只对定位元素有效,什么是定位元素呢,也就是设置了position属性的元素,position:relative--相对定位,position:absolute ...
- 你不知道的css各类布局(一)之固定布局、静态布局
前言 当为大量用户设计网站时,设计人员必须考虑到访问者的差异: 屏幕分辨率, 浏览器的选择, 是否在浏览器最大化状态, 浏览器的额外工具栏的开启(历史记录,书签等), 操作系统和硬件. 我们知道css ...
- QT编译Mysql驱动问题及解决方案
默认情况下,qt 并没有自带mysql的数据库插件,需要自己编译先安装mysql server ,运行setup.exe时选择自定义安装,安装目录设为"D:\mysqldev"不要 ...
- 【Javascript】 js的构造函数与原形对象的关系
构造函数只是提供了一个创建对象的模板,它并不是对象的原形. 对象的原形是构造函数的原形,即object. ----------------------------------------------- ...
- js之常用正则
//用户名正则,4到16位(字母,数字,下划线,减号) let uPattern = /^[a-zA-Z0-9_-]{4,16}$/; //密码强度正则,最少6位,包括至少1个大写字母,1个小写字母, ...
- centos7搭建docker并部署lnmp (转)
1.首先呢先更新yum源 yum -y update 2.1.安装docker存储库 yum install -y yum-utils \ device-mapper-persistent-dat ...
- hadoop 中ALL Applications 中Tracking 下History查找不到MapReduce Job 日志
运行一个Map Reduce job 想查看日志: 点击History ,找不到网页 解决办法如下: 1.其中有一个进程是需要启动的: Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行 ...
- 第六章·Logstash深入-收集java日志
1.通过Logstash收集java日志并输出到ES中 因为我们现在需要用Logstash收集tomcat日志,所以我们暂时将tomcat安装到Logstash所在机器,也就是db03:10.0.0. ...
- deep_learning_Dropout
吴恩达深度学习笔记(十一)—— dropout正则化 主要内容: 一.dropout正则化的思想 二.dropout算法流程 三.dropout的优缺点 一.dropout正则化的思想 在神经网络中, ...
- 【转】关于 Error[Pe020]: identifier "HAL_StatusTypeDef" is undefined
@2019-06-06 [小记] 这个bug比较常见,右键可以定位到相关头文件,但系统依旧报错,其实主要还是头文件的问题. 1.需要检查头文件中关于主程序所用到的部分是否已经使能,尤其是 “stm32 ...