Hadoop基础-完全分布式模式部署yarn日志聚集功能
Hadoop基础-完全分布式模式部署yarn日志聚集功能
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
其实我们不用配置也可以在服务器后台通过命令行的形式查看相应的日志,但为了更方便查看日志,我们可以将其配置成通过webUI的形式访问日志,本篇博客会手把手的教你如何实操。如果你的集群配置比较低的话,并不建议开启日志,但是一般的大数据集群,服务器配置应该都不低,不过最好根据实际情况考虑。
一.查看日志信息
1>.通过web界面查看日志信息

2>.webUI默认是无法查看到日志信息

3>.通过命令行查看
日志默认存放在安装hadoop目录的logs文件夹中,其实我们不用配置web页面也可以查看相应的日志,下图就是通过命令行的形式查看日志。

二.配置日志聚集功能
1>.停止hadoop集群
[yinzhengjie@s101 ~]$ stop-dfs.sh
Stopping namenodes on [s101 s105]
s101: stopping namenode
s105: stopping namenode
s103: stopping datanode
s104: stopping datanode
s102: stopping datanode
Stopping journal nodes [s102 s103 s104]
s102: stopping journalnode
s104: stopping journalnode
s103: stopping journalnode
Stopping ZK Failover Controllers on NN hosts [s101 s105]
s101: stopping zkfc
s105: stopping zkfc
[yinzhengjie@s101 ~]$
停止hdfs分布式文件系统([yinzhengjie@s101 ~]$ stop-dfs.sh )
[yinzhengjie@s101 ~]$ stop-yarn.sh
stopping yarn daemons
s101: stopping resourcemanager
s105: no resourcemanager to stop
s102: stopping nodemanager
s104: stopping nodemanager
s103: stopping nodemanager
s102: nodemanager did not stop gracefully after seconds: killing with kill -
s104: nodemanager did not stop gracefully after seconds: killing with kill -
s103: nodemanager did not stop gracefully after seconds: killing with kill -
no proxyserver to stop
[yinzhengjie@s101 ~]$
停止yarn集群([yinzhengjie@s101 ~]$ stop-yarn.sh )
[yinzhengjie@s101 ~]$ mr-jobhistory-daemon.sh stop historyserver
stopping historyserver
[yinzhengjie@s101 ~]$
停止yarn日志服务([yinzhengjie@s101 ~]$ mr-jobhistory-daemon.sh stop historyserver)
[yinzhengjie@s101 ~]$ more `which xcall.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数"
exit
fi #获取用户输入的命令
cmd=$@ for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo ============= s$i $cmd ============
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
ssh s$i $cmd
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
Jps
命令执行成功
============= s102 jps ============
Jps
QuorumPeerMain
命令执行成功
============= s103 jps ============
Jps
QuorumPeerMain
命令执行成功
============= s104 jps ============
QuorumPeerMain
Jps
命令执行成功
============= s105 jps ============
Jps
命令执行成功
[yinzhengjie@s101 ~]$
检查是否停止成功([yinzhengjie@s101 ~]$ xcall.sh jps)
2>.修改“yarn-site.xml”配置文件
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s101</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property> <property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property> </configuration> <!-- yarn-site.xml配置文件的作用:
#主要用于配置调度器级别的参数. yarn.resourcemanager.hostname 参数的作用:
#指定资源管理器(resourcemanager)的主机名 yarn.nodemanager.aux-services 参数的作用:
#指定nodemanager使用shuffle yarn.nodemanager.pmem-check-enabled 参数的作用:
#是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true yarn.nodemanager.vmem-check-enabled 参数的作用:
#是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true yarn.log-aggregation-enable 参数的作用:
#是否开启webUI日志聚集功能使能,默认为flase yarn.log-aggregation.retain-seconds 参数的作用:
#指定日志保留时间,单位为妙
-->
[yinzhengjie@s101 ~]$
3>.分发配置文件到各个节点
[yinzhengjie@s101 ~]$ more `which xrsync.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数";
exit
fi #获取文件路径
file=$@ #获取子路径
filename=`basename $file` #获取父路径
dirpath=`dirname $file` #获取完整路径
cd $dirpath
fullpath=`pwd -P` #同步文件到DataNode
for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo =========== s$i %file ===========
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
rsync -lr $filename `whoami`@s$i:$fullpath
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ xrsync.sh /soft/hadoop-2.7./
=========== s102 %file ===========
命令执行成功
=========== s103 %file ===========
命令执行成功
=========== s104 %file ===========
命令执行成功
=========== s105 %file ===========
命令执行成功
[yinzhengjie@s101 ~]$
4>.启动hadoop集群
[yinzhengjie@s101 ~]$ start-dfs.sh
Starting namenodes on [s101 s105]
s105: starting namenode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-namenode-s105.out
s101: starting namenode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-namenode-s101.out
s103: starting datanode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-datanode-s103.out
s102: starting datanode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-datanode-s102.out
s104: starting datanode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-datanode-s104.out
Starting journal nodes [s102 s103 s104]
s102: starting journalnode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-journalnode-s102.out
s103: starting journalnode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-journalnode-s103.out
s104: starting journalnode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-journalnode-s104.out
Starting ZK Failover Controllers on NN hosts [s101 s105]
s105: starting zkfc, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-zkfc-s105.out
s101: starting zkfc, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-zkfc-s101.out
[yinzhengjie@s101 ~]$
启动hdfs分布式文件系统([yinzhengjie@s101 ~]$ start-dfs.sh )
[yinzhengjie@s101 ~]$ start-yarn.sh
starting yarn daemons
s101: starting resourcemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-resourcemanager-s101.out
s105: starting resourcemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-resourcemanager-s105.out
s102: starting nodemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-nodemanager-s102.out
s103: starting nodemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-nodemanager-s103.out
s104: starting nodemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-nodemanager-s104.out
[yinzhengjie@s101 ~]$
启动yarn集群([yinzhengjie@s101 ~]$ start-yarn.sh )
[yinzhengjie@s101 ~]$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /soft/hadoop-2.7./logs/mapred-yinzhengjie-historyserver-s101.out
[yinzhengjie@s101 ~]$
启动yarn日志服务([yinzhengjie@s101 ~]$ mr-jobhistory-daemon.sh start historyserver)
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
DFSZKFailoverController
Jps
NameNode
JobHistoryServer
ResourceManager
命令执行成功
============= s102 jps ============
DataNode
JournalNode
NodeManager
Jps
QuorumPeerMain
命令执行成功
============= s103 jps ============
JournalNode
NodeManager
Jps
DataNode
QuorumPeerMain
命令执行成功
============= s104 jps ============
JournalNode
NodeManager
QuorumPeerMain
Jps
DataNode
命令执行成功
============= s105 jps ============
NameNode
Jps
DFSZKFailoverController
命令执行成功
[yinzhengjie@s101 ~]$
检查集群是否启动成功([yinzhengjie@s101 ~]$ xcall.sh jps)
5>.在yarn上执行MapReduce程序
[yinzhengjie@s101 ~]$ hdfs dfs -rm -R /yinzhengjie/data/output
// :: INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = minutes, Emptier interval = minutes.
Deleted /yinzhengjie/data/output
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ hadoop jar /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /yinzhengjie/data/input /yinzhengjie/data/output
// :: INFO client.RMProxy: Connecting to ResourceManager at s101/172.30.1.101:
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1534857666985_0001
// :: INFO impl.YarnClientImpl: Submitted application application_1534857666985_0001
// :: INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1534857666985_0001/
// :: INFO mapreduce.Job: Running job: job_1534857666985_0001
// :: INFO mapreduce.Job: Job job_1534857666985_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1534857666985_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
[yinzhengjie@s101 ~]$
6>.查看yarn的记录信息
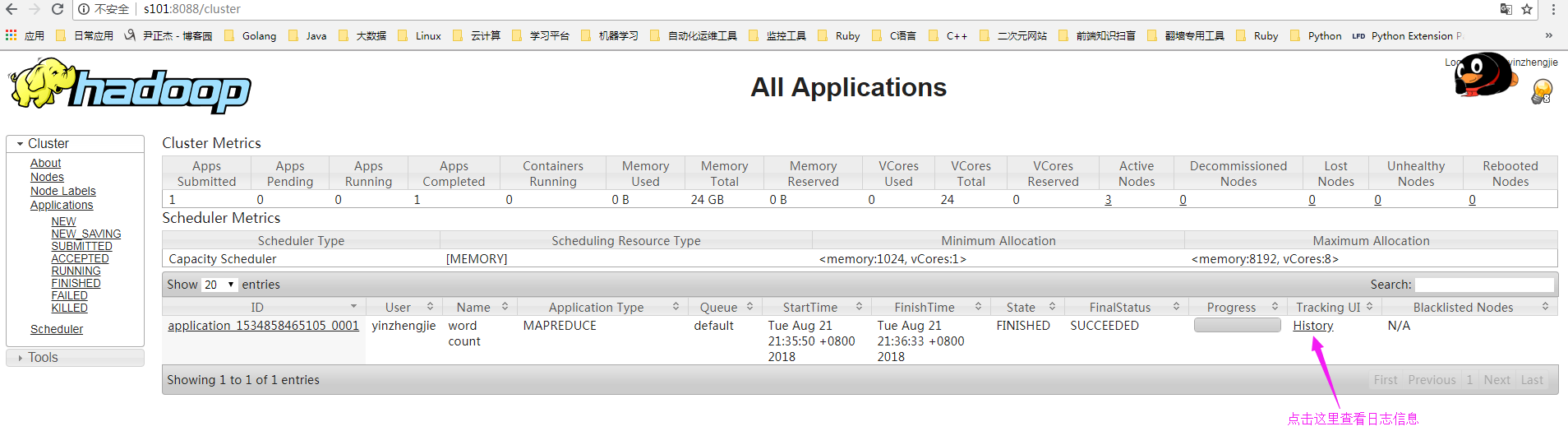
7>.查看历史日志
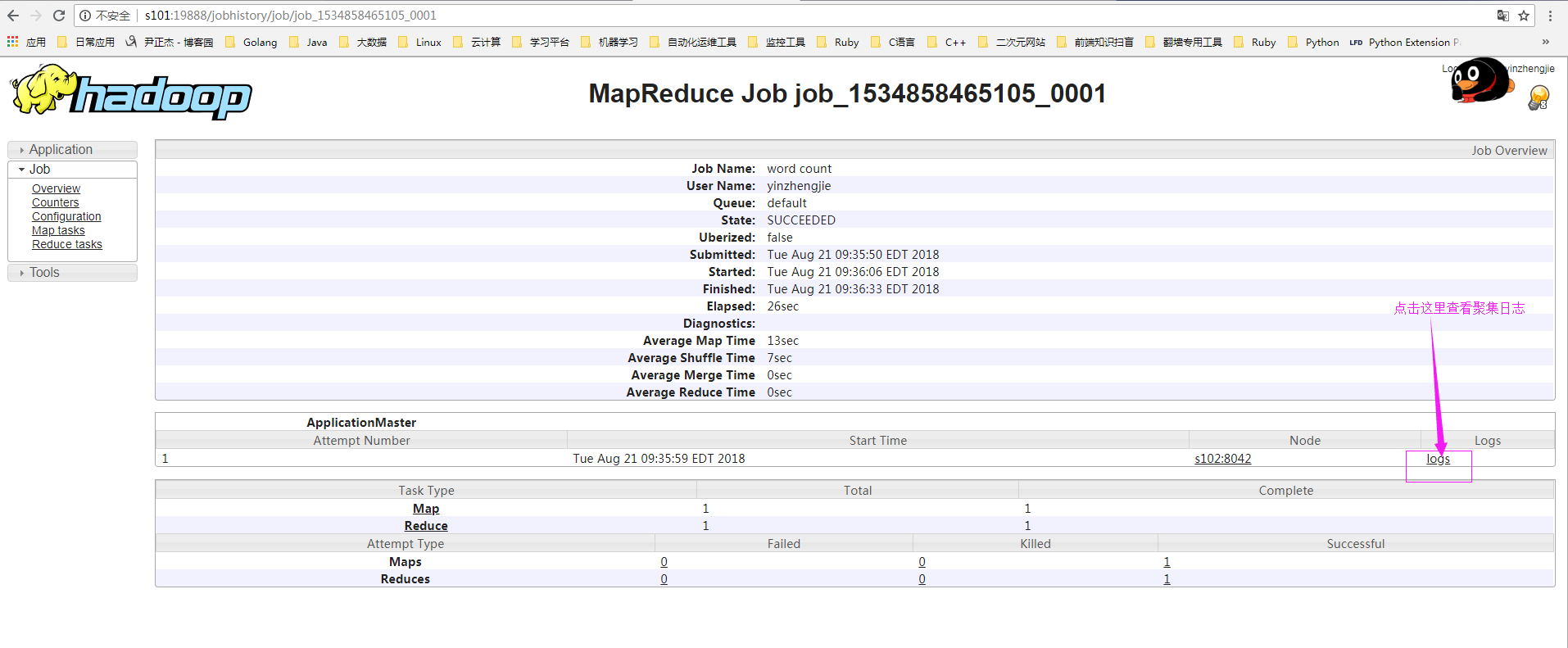
8>.查看日志信息

Hadoop基础-完全分布式模式部署yarn日志聚集功能的更多相关文章
- 启用yarn日志聚集功能
在yarn-site.xml配置文件中添加如下内容: ##开启日志聚集功能 <property> <name>yarn.log-ag ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- Yarn 的日志聚集功能配置使用
需要 hadoop 的安装目录/etc/hadoop/yarn-site.xml 中进行配置 配置内容 <property> <name>yarn.log-aggregati ...
- hadoop 3.x 配置日志聚集功能
打开$HADOOP_HOME/etc/hadoop/yarn-site.xml,增加以下配置(在此配置文件中尽量不要使用中文注释) <!--logs--> <property> ...
- 开启spark日志聚集功能
spark监控应用方式: 1)在运行过程中可以通过web Ui:4040端口进行监控 2)任务运行完成想要监控spark,需要启动日志聚集功能 开启日志聚集功能方法: 编辑conf/spark-env ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- 用python + hadoop streaming 编写分布式程序(三) -- 自定义功能
又是期末又是实训TA的事耽搁了好久……先把写好的放上博客吧 相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍 ...
- Hadoop+Hbas完全分布式安装部署
Hadoop安装部署基本步骤: 1.安装jdk,配置环境变量. jdk可以去网上自行下载,环境变量如下: 编辑 vim /etc/profile 文件,添加如下内容: export JAVA_HO ...
- hadoop实战之分布式模式
环境 192.168.1.101 host101 192.168.1.102 host102 1.安装配置host101 [root@host101 ~]# cat /etc/hosts |grep ...
随机推荐
- android开发之Tabhost刷新
在android中,使用tabHost的时候,如果tab被点击,该tab所对应的activity被加载了,从别的tab切换回来的时候,activity不会再次被创建了(onCreate),所以要想每次 ...
- 选择J2EE的SSH框架的理由
选择J2EE的SSH框架的理由 Struts2框架: Struts2框架的基本思想是采用MVC设计模式,即将应用设计成模型(Model).视图(View)和控制器(Control)三个部分:控制部分由 ...
- 软件工程个人项目作业 Individual Project
利用Junit4进行程序模块的测试,回归测试 源码 https://github.com/dpch16303/test/blob/master/%E5%9B%9E%E5%BD%92%E6%B5%8B% ...
- Java正则解析HTML一例
import java.util.regex.Matcher;import java.util.regex.Pattern; public class Test { static String tes ...
- 转帖: Serverless架构模式简介
Serverless架构模式简介 原贴地址:https://blog.csdn.net/chdhust/article/details/71250099?utm_medium=referral&a ...
- msyql sql语句收集
在不断的学习中,发现了一些新的slq语句,总结于此. 一.复制数据表的sql 1)create table tableName as select * from tableName2 ...
- Get请求,Post请求乱码问题解决方案
下面以两种常见的请求方式为例讲解乱码问题的解决方法. 1.Post方式请求乱码. 自从Tomcat5.x以来,Get方式和Post方式提交的请求,tomcat会采用不同的方式来处理编码. 对于Post ...
- std::string 字符串替换
std::string 没有原生的字符串替换函数,需要自己来完成 string& replace_str(string& str, const string& to_repla ...
- Sql 重置自动增长列
Sql 重置自动增长列: dbcc checkident(表名, reseed, 0) 使用的情况,一般出现在主外键关联表,导致无法 truncate 只能delete的情况. 此时我们可能会需要重置 ...
- day9 集合基础命令
集合的创建 s = set("hello") print(s) s = set({","alex","sb"}) print(s) ...