Tensorflow加载预训练模型和保存模型
转载自:https://blog.csdn.net/huachao1001/article/details/78501928
使用tensorflow过程中,训练结束后我们需要用到模型文件。有时候,我们可能也需要用到别人训练好的模型,并在这个基础上再次训练。这时候我们需要掌握如何操作这些模型数据。看完本文,相信你一定会有收获!
1 Tensorflow模型文件
我们在checkpoint_dir目录下保存的文件结构如下:
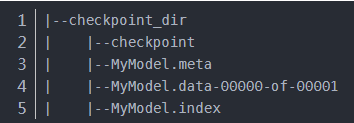
1.1 meta文件
MyModel.meta文件保存的是图结构,meta文件是pb(protocol buffer)格式文件,包含变量、op、集合等。
1.2 ckpt文件
ckpt文件是二进制文件,保存了所有的weights、biases、gradients等变量。在tensorflow 0.11之前,保存在**.ckpt**文件中。0.11后,通过两个文件保存,如:
1.3 checkpoint文件
我们还可以看,checkpoint_dir目录下还有checkpoint文件,该文件是个文本文件,里面记录了保存的最新的checkpoint文件以及其它checkpoint文件列表。在inference时,可以通过修改这个文件,指定使用哪个model
2 保存Tensorflow模型
tensorflow 提供了tf.train.Saver类来保存模型,值得注意的是,在tensorflow中,变量是存在于Session环境中,也就是说,只有在Session环境下才会存有变量值,因此,保存模型时需要传入session:
saver = tf.train.Saver()
saver.save(sess,"./checkpoint_dir/MyModel")
看一个简单例子:
import tensorflow as tf w1 = tf.Variable(tf.random_normal(shape=[2]), name='w1')
w2 = tf.Variable(tf.random_normal(shape=[5]), name='w2')
saver = tf.train.Saver()
sess = tf.Session()
sess.run(tf.global_variables_initializer())
saver.save(sess, './checkpoint_dir/MyModel')
执行后,在checkpoint_dir目录下创建模型文件如下:
checkpoint
MyModel.data-00000-of-00001
MyModel.index
MyModel.meta
另外,如果想要在1000次迭代后,再保存模型,只需设置global_step参数即可:
saver.save(sess, './checkpoint_dir/MyModel',global_step=1000)
保存的模型文件名称会在后面加-1000,如下:
checkpoint
MyModel-1000.data-00000-of-00001
MyModel-1000.index
MyModel-1000.meta
在实际训练中,我们可能会在每1000次迭代中保存一次模型数据,但是由于图是不变的,没必要每次都去保存,可以通过如下方式指定不保存图:
saver.save(sess, './checkpoint_dir/MyModel',global_step=step,write_meta_graph=False)
另一种比较实用的是,如果你希望每2小时保存一次模型,并且只保存最近的5个模型文件:
tf.train.Saver(max_to_keep=5, keep_checkpoint_every_n_hours=2)
注意:tensorflow默认只会保存最近的5个模型文件,如果你希望保存更多,可以通过max_to_keep来指定
如果我们不对tf.train.Saver指定任何参数,默认会保存所有变量。如果你不想保存所有变量,而只保存一部分变量,可以通过指定variables/collections。在创建tf.train.Saver实例时,通过将需要保存的变量构造list或者dictionary,传入到Saver中:
import tensorflow as tf
w1 = tf.Variable(tf.random_normal(shape=[2]), name='w1')
w2 = tf.Variable(tf.random_normal(shape=[5]), name='w2')
saver = tf.train.Saver([w1,w2]) #这定义了需要保存的参数
sess = tf.Session()
sess.run(tf.global_variables_initializer())
saver.save(sess, './checkpoint_dir/MyModel',global_step=1000)
3 导入训练好的模型
在第1小节中我们介绍过,tensorflow将图和变量数据分开保存为不同的文件。因此,在导入模型时,也要分为2步:构造网络图和加载参数
3.1 构造网络图
一个比较笨的方法是,手敲代码,实现跟模型一模一样的图结构。其实,我们既然已经保存了图,那就没必要在去手写一次图结构代码。
saver=tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta')
上面一行代码,就把图加载进来了
3.2 加载参数
仅仅有图并没有用,更重要的是,我们需要前面训练好的模型参数(即weights、biases等),本文第2节提到过,变量值需要依赖于Session,因此在加载参数时,先要构造好Session:
import tensorflow as tf
with tf.Session() as sess:
new_saver = tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta')
new_saver.restore(sess, tf.train.latest_checkpoint('./checkpoint_dir'))
此时,W1和W2加载进了图,并且可以被访问:
import tensorflow as tf
with tf.Session() as sess:
saver = tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta')
saver.restore(sess,tf.train.latest_checkpoint('./checkpoint_dir'))
print(sess.run('w1:0'))
执行后,打印如下:[ 0.51480412 -0.56989086]
4 使用恢复的模型
前面我们理解了如何保存和恢复模型,很多时候,我们希望使用一些已经训练好的模型,如prediction、fine-tuning以及进一步训练等。这时候,我们可能需要获取训练好的模型中的一些中间结果值,
可以通过graph.get_tensor_by_name('w1:0')来获取,注意w1:0是tensor的name。
假设我们有一个简单的网络模型,代码如下:
import tensorflow as tf
w1 = tf.placeholder("float", name="w1")
w2 = tf.placeholder("float", name="w2")
b1= tf.Variable(2.0,name="bias")
#定义一个op,用于后面恢复
w3 = tf.add(w1,w2)
w4 = tf.multiply(w3,b1,name="op_to_restore")
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#创建一个Saver对象,用于保存所有变量
saver = tf.train.Saver()
#通过传入数据,执行op
print(sess.run(w4,feed_dict ={w1:4,w2:8}))
#打印 24.0 ==>(w1+w2)*b1
#现在保存模型
saver.save(sess, './checkpoint_dir/MyModel',global_step=1000)
接下来我们使用graph.get_tensor_by_name()方法来操纵这个保存的模型。
import tensorflow as tf sess=tf.Session()
#先加载图和参数变量
saver = tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta')
saver.restore(sess, tf.train.latest_checkpoint('./checkpoint_dir')) # 访问placeholders变量,并且创建feed-dict来作为placeholders的新值
graph = tf.get_default_graph()
w1 = graph.get_tensor_by_name("w1:0")
w2 = graph.get_tensor_by_name("w2:0")
feed_dict ={w1:13.0,w2:17.0} #接下来,访问你想要执行的op
op_to_restore = graph.get_tensor_by_name("op_to_restore:0") print(sess.run(op_to_restore,feed_dict))
#打印结果为60.0==>(13+17)*2
如果你不仅仅是用训练好的模型,还要加入一些op,或者说加入一些layers并训练新的模型,可以通过一个简单例子来看如何操作:
import tensorflow as tf sess = tf.Session()
# 先加载图和变量
saver = tf.train.import_meta_graph('my_test_model-1000.meta')
saver.restore(sess, tf.train.latest_checkpoint('./')) # 访问placeholders变量,并且创建feed-dict来作为placeholders的新值
graph = tf.get_default_graph()
w1 = graph.get_tensor_by_name("w1:0")
w2 = graph.get_tensor_by_name("w2:0")
feed_dict = {w1: 13.0, w2: 17.0} #接下来,访问你想要执行的op
op_to_restore = graph.get_tensor_by_name("op_to_restore:0") # 在当前图中能够加入op
add_on_op = tf.multiply(op_to_restore, 2) print (sess.run(add_on_op, feed_dict))
# 打印120.0==>(13+17)*2*2
如果只想恢复图的一部分,并且再加入其它的op用于fine-tuning。只需通过graph.get_tensor_by_name()方法获取需要的op,并且在此基础上建立图,看一个简单例子,假设我们需要在训练好的VGG网络使用图,并且修改最后一层,将输出改为2,用于fine-tuning新数据:
......
......
saver = tf.train.import_meta_graph('vgg.meta')
# 访问图
graph = tf.get_default_graph() #访问用于fine-tuning的output
fc7= graph.get_tensor_by_name('fc7:0') #如果你想修改最后一层梯度,需要如下
fc7 = tf.stop_gradient(fc7) # It's an identity function
fc7_shape= fc7.get_shape().as_list() new_outputs=2
weights = tf.Variable(tf.truncated_normal([fc7_shape[3], num_outputs], stddev=0.05))
biases = tf.Variable(tf.constant(0.05, shape=[num_outputs]))
output = tf.matmul(fc7, weights) + biases
pred = tf.nn.softmax(output) # Now, you run this with fine-tuning data in sess.run()
Tensorflow加载预训练模型和保存模型的更多相关文章
- Tensorflow加载预训练模型和保存模型(ckpt文件)以及迁移学习finetuning
转载自:https://blog.csdn.net/huachao1001/article/details/78501928 使用tensorflow过程中,训练结束后我们需要用到模型文件.有时候,我 ...
- pytorch中修改后的模型如何加载预训练模型
问题描述 简单来说,比如你要加载一个vgg16模型,但是你自己需要的网络结构并不是原本的vgg16网络,可能你删掉某些层,可能你改掉某些层,这时你去加载预训练模型,就会报错,错误原因就是你的模型和原本 ...
- [Pytorch]Pytorch加载预训练模型(转)
转自:https://blog.csdn.net/Vivianyzw/article/details/81061765 东风的地方 1. 直接加载预训练模型 在训练的时候可能需要中断一下,然后继续训练 ...
- 使用Huggingface在矩池云快速加载预训练模型和数据集
作为NLP领域的著名框架,Huggingface(HF)为社区提供了众多好用的预训练模型和数据集.本文介绍了如何在矩池云使用Huggingface快速加载预训练模型和数据集. 1.环境 HF支持Pyt ...
- 关于Tensorflow 加载和使用多个模型的方式
在Tensorflow中,所有操作对象都包装到相应的Session中的,所以想要使用不同的模型就需要将这些模型加载到不同的Session中并在使用的时候申明是哪个Session,从而避免由于Sessi ...
- pytorch加载预训练模型参数的方式
1.直接使用默认程序里的下载方式,往往比较慢: 2.通过修改源代码,使得模型加载已经下载好的参数,修改地方如下: 通过查找自己代码里所调用网络的类,使用pycharm自带的函数查找功能(ctrl+鼠标 ...
- 开园第一篇---有关tensorflow加载不同模型的问题
写在前面 今天刚刚开通博客,主要想法跟之前某位博主说的一样,希望通过博客园把每天努力的点滴记录下来,也算一种坚持的动力.我是小白一枚,有啥问题欢迎各位大神指教,鞠躬~~ 换了新工作,目前手头是OCR项 ...
- 用MVVM模式开发中遇到的零散问题总结(5)——将动态加载的可视元素保存为图片的控件,Binding刷新的时机
原文:用MVVM模式开发中遇到的零散问题总结(5)--将动态加载的可视元素保存为图片的控件,Binding刷新的时机 在项目开发中经常会遇到这样一种情况,就是需要将用户填写的信息排版到一张表单中,供打 ...
- vue中加载three.js的gltf模型
vue中加载three.js的gltf模型 一.开始引入three.js相关插件.首先利用淘宝镜像,操作命令为: cnpm install three //npm install three也行 二. ...
随机推荐
- JDK快捷安装,以及详细安装步骤
一,直接快捷安装 安装JDK之前先打开终端输入以下内容检查是否有JDK环境 java javac java -version 输入完弹出一堆东西就是安装完成了 如果安装可以使用 rpm -qa | g ...
- LeetCode 141. 环形链表(Linked List Cycle)
题目描述 给定一个链表,判断链表中是否有环. 进阶:你能否不使用额外空间解决此题? 解题思路 快慢指针,慢指针一次走一步,快指针一次走两步,若两者相遇则说明有环,快指针无路可走则说明无环. 代码 /* ...
- ThinkPHP空操作与命名空间
命名空间:相当于一个虚拟的目录 正常管理文件使用文件夹--物理区分 TP框架的初始命名空间是:ThinkPHP\Library 在TP框架下命名空间里面使用\代表的是初始命名空间(ThinkPHP\L ...
- requests和BeautifulSoup模块的使用
用python写爬虫时,有两个很好用第三方模块requests库和beautifulsoup库,简单学习了下模块用法: 1,requests模块 Python标准库中提供了:urllib.urllib ...
- Android中常见的默认实现类
* Basexxx* Defaultxxx* Simplexxx* Baicxxx
- [Java复习] Java基础 Basic
Q1面向对象 类.对象特征? 类:对事物逻辑算法或概念的抽象,描述一类对象的行为和状态. OOP三大特征,封装,继承,多态 封装:隐藏属性实现细节,只公开接口.将抽象的数据和行为结合,形成类.目的是简 ...
- 实现超简单的http服务器
想在Linux下实现一个简单的web Server并不难.一个最简单的HTTP Server不过是一个高级的文件服务器,不断地接收客户端(浏览器)发送的HTTP请求,解析请求,处理请求,然后像客户端回 ...
- 一百零二:CMS系统之sweetalert提示框和使用
实现效果 css body.stop-scrolling { height: 100%; overflow: hidden; } .sweet-overlay { background-color: ...
- Oracle数据库导入(expdp)和导出(impdp)
文档最后,列出了常用的一些导入导出的场景,以及一些导入导出的属性说明. 一.数据库导出(expdp) 使用sys或system账号登录oracle 通过"Window + R" 打 ...
- ppt学习笔记
文档:ppt学习笔记.note链接:http://note.youdao.com/noteshare?id=719a525ca3420e3692b1025d5d904c02&sub=4E52E ...