python爬虫---抓取优酷的电影
最近在学习爬虫,用的BeautifulSoup4这个库,设想是把优酷上面的电影的名字及链接爬到,然后存到一个文本文档中。比较简单的需求,第一次写爬虫。贴上代码供参考:
# coding:utf-8 import requests
import os
from bs4 import BeautifulSoup
import re
import time '''抓优酷网站的电影:http://www.youku.com/ ''' url = "http://list.youku.com/category/show/c_96_s_1_d_1_u_1.html"
h = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"} #存到movie文件夹的文本文件中
def write_movie():
currentPath = os.path.dirname(os.path.realpath(__file__))
#print(currentPath)
moviePath = currentPath + "\\" + "movie"+"\\" + "youku_movie_address.text"
#print(moviePath)
fp = open(moviePath ,encoding="utf-8",mode="a") for x in list_a:
text = x.get_text()
if text == "":
try:
fp.write(x["title"] + ": " + x["href"]+"\n")
except IOError as msg:
print(msg) fp.write("-------------------------------over-----------------------------" + "\n")
fp.close() #第一页
res = requests.get(url,headers = h)
print(res.url)
soup = BeautifulSoup(res.content,'html.parser')
list_a = soup.find_all(href = re.compile("==.html"),target="_blank")
write_movie() for num in range(2,1000): #获取“下一页”的href属性
fanye_a = soup.find(charset="-4-1-999" )
fanye_href = fanye_a["href"]
print(fanye_href)
#请求页面
ee = requests.get("http:" + fanye_href,headers = h)
time.sleep(3)
print(ee.url) soup = BeautifulSoup(ee.content,'html.parser')
list_a = soup.find_all(href = re.compile("==.html"),target="_blank") #调用写入的方法
write_movie()
time.sleep(6)
运行后的txt内的文本内容:
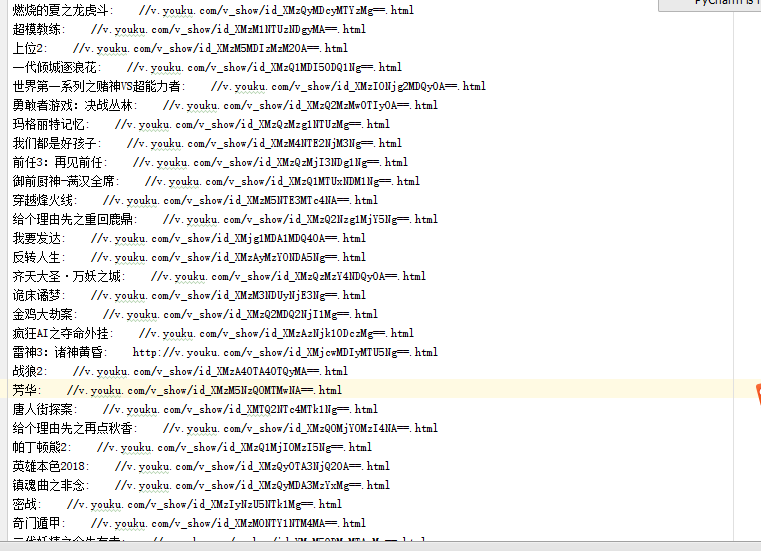
python爬虫---抓取优酷的电影的更多相关文章
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- Python爬虫 -- 抓取电影天堂8分以上电影
看了几天的python语法,还是应该写个东西练练手.刚好假期里面看电影,找不到很好的影片,于是有个想法,何不搞个爬虫把电影天堂里面8分以上的电影爬出来.做完花了两三个小时,撸了这么一个程序.反正蛮简单 ...
- python爬虫抓取豆瓣电影
抓取电影名称以及评分,并排序(代码丑炸) import urllib import re from bs4 import BeautifulSoup def get(p): t=0 k=1 n=1 b ...
- java平台利用jsoup开发包,抓取优酷视频播放地址与图片地址等信息。
/******************************************************************************************** * aut ...
- Python 爬虫: 抓取花瓣网图片
接触Python也好长时间了,一直没什么机会使用,没有机会那就自己创造机会!呐,就先从爬虫开始吧,抓点美女图片下来. 废话不多说了,讲讲我是怎么做的. 1. 分析网站 想要下载图片,只要知道图片的地址 ...
- python爬虫 抓取一个网站的所有网址链接
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
随机推荐
- freemarker处理哈希表的内建函数
freemarker处理哈希表的内建函数 1.简易说明 (1)map取值 (2)key取值 2.实现示例 <html> <head> <meta http-equiv=& ...
- ftp搭建 与http服务访问
Linux安装ftp组件 1 FTP http://jingyan.baidu.com/article/380abd0a77ae041d90192cf4.html安装vsftpd组件 安装完后,有/e ...
- iOS 双击tabbar刷新页面
/*在继承UITabBarController控制器中*/ #pragma mark <UITabBarControllerDelegate> -(void)tabBarControlle ...
- Python爬虫之模拟登录微信wechat
不知何时,微信已经成为我们不可缺少的一部分了,我们的社交圈.关注的新闻或是公众号.还有个人信息或是隐私都被绑定在了一起.既然它这么重要,如果我们可以利用爬虫模拟登录,是不是就意味着我们可以获取这些信息 ...
- 让安卓app支持swf的一个播放器,和自己编写的音乐管理程序
jcenter方式导入 在需要用到这个库的module中的build.gradle中的dependencies中加入 dependencies { compile 'com.yhd.hdswfplay ...
- tar命令核心应用案列及多重参数和find组合应用
tar zcvf 压缩包 文件 打包:尽量切换到打包目录的上级目录,然后用相对路径打包 tar zcvf [随意路径] /框 [相对路径] 一堆苹果 tar tf 查看内容 -z --gzip -- ...
- npm包管理器相关知识
关于npm包安装命令的介绍,如下图:
- 解决PhpMyadmin1440秒未活动自动退出
解决方法如下:#vim phpMyAdmin/libraries/config.default.php找到如下位置$cfg['LoginCookieValidity'] = ; 将1440修改成 ...
- C# Redis实战(一)
一.初步准备 Redis 是一个开源的使用ANSI C 语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value 数据库.Redis的出现,很大程度补偿了memcached这类key/va ...
- 深入理解Java虚拟机到底是什么
摘自:http://blog.csdn.net/zhangjg_blog/article/details/20380971 什么是Java虚拟机 我们都知道Java程序必须在虚拟机上运行.那么虚拟机到 ...