python爬虫---抓取优酷的电影
最近在学习爬虫,用的BeautifulSoup4这个库,设想是把优酷上面的电影的名字及链接爬到,然后存到一个文本文档中。比较简单的需求,第一次写爬虫。贴上代码供参考:
# coding:utf-8 import requests
import os
from bs4 import BeautifulSoup
import re
import time '''抓优酷网站的电影:http://www.youku.com/ ''' url = "http://list.youku.com/category/show/c_96_s_1_d_1_u_1.html"
h = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"} #存到movie文件夹的文本文件中
def write_movie():
currentPath = os.path.dirname(os.path.realpath(__file__))
#print(currentPath)
moviePath = currentPath + "\\" + "movie"+"\\" + "youku_movie_address.text"
#print(moviePath)
fp = open(moviePath ,encoding="utf-8",mode="a") for x in list_a:
text = x.get_text()
if text == "":
try:
fp.write(x["title"] + ": " + x["href"]+"\n")
except IOError as msg:
print(msg) fp.write("-------------------------------over-----------------------------" + "\n")
fp.close() #第一页
res = requests.get(url,headers = h)
print(res.url)
soup = BeautifulSoup(res.content,'html.parser')
list_a = soup.find_all(href = re.compile("==.html"),target="_blank")
write_movie() for num in range(2,1000): #获取“下一页”的href属性
fanye_a = soup.find(charset="-4-1-999" )
fanye_href = fanye_a["href"]
print(fanye_href)
#请求页面
ee = requests.get("http:" + fanye_href,headers = h)
time.sleep(3)
print(ee.url) soup = BeautifulSoup(ee.content,'html.parser')
list_a = soup.find_all(href = re.compile("==.html"),target="_blank") #调用写入的方法
write_movie()
time.sleep(6)
运行后的txt内的文本内容:
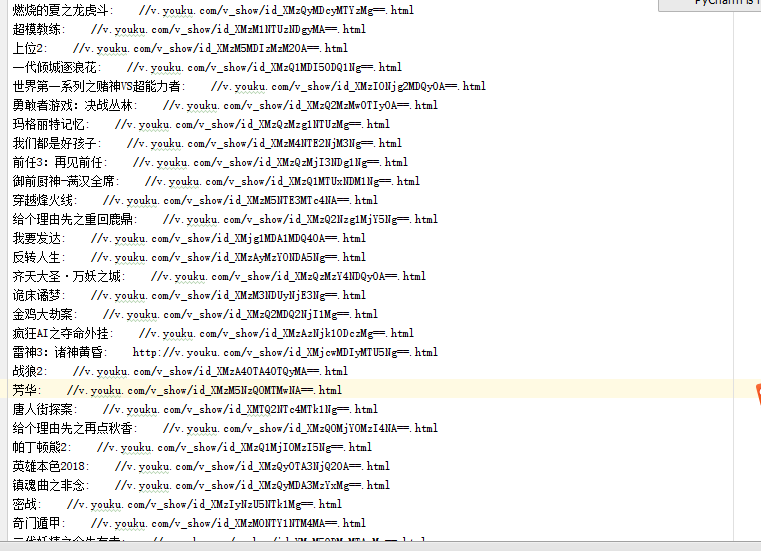
python爬虫---抓取优酷的电影的更多相关文章
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- Python爬虫 -- 抓取电影天堂8分以上电影
看了几天的python语法,还是应该写个东西练练手.刚好假期里面看电影,找不到很好的影片,于是有个想法,何不搞个爬虫把电影天堂里面8分以上的电影爬出来.做完花了两三个小时,撸了这么一个程序.反正蛮简单 ...
- python爬虫抓取豆瓣电影
抓取电影名称以及评分,并排序(代码丑炸) import urllib import re from bs4 import BeautifulSoup def get(p): t=0 k=1 n=1 b ...
- java平台利用jsoup开发包,抓取优酷视频播放地址与图片地址等信息。
/******************************************************************************************** * aut ...
- Python 爬虫: 抓取花瓣网图片
接触Python也好长时间了,一直没什么机会使用,没有机会那就自己创造机会!呐,就先从爬虫开始吧,抓点美女图片下来. 废话不多说了,讲讲我是怎么做的. 1. 分析网站 想要下载图片,只要知道图片的地址 ...
- python爬虫 抓取一个网站的所有网址链接
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
随机推荐
- SQLyog键盘快捷方式
SQLyog键盘快捷方式 连接 Ctrl+M 创建新连接 Ctrl+N 以当前连接属性创建新连接 Ctrl+F4/Ctrl+W 断开当前连接 Ctrl+Tab 切换到下一个连接 Ctrl+Shift+ ...
- Error Correct System CodeForces - 527B
Ford Prefect got a job as a web developer for a small company that makes towels. His current work ta ...
- java实现全排列问题
1.问题描述: 一组字符串的全排列,按照全排列的顺序输出,并且每行结尾无空格. 2.输入: 输入一个字符串 3.输入示例: 请输入全排列的字符串: abc 4.输出示例: a b c a c b b ...
- js运算符单竖杠“|”的用法和作用及js数据处理
js运算符单竖杠“|”的作用 很多朋友都对双竖杠“||”,了如指掌,因为这个经常用到.但是大家知道单竖杠吗?今天有个网友QQ问我,我的 javascript实用技巧,js小知识 , 这篇文章里面,js ...
- sspanelv3魔改版邮件设置指南及常用配置
要进行SSpanel v3魔改版邮件设置,需要在设置文件(位于config/.config.php下)中修改两处内容: 1.设置发送邮件的方式 $System_Config['enable_email ...
- 算法精解:DAG有向无环图
DAG是公认的下一代区块链的标志.本文从算法基础去研究分析DAG算法,以及它是如何运用到区块链中,解决了当前区块链的哪些问题. 关键字:DAG,有向无环图,算法,背包,深度优先搜索,栈,BlockCh ...
- JavaIO 总结
另外参考文章:http://www.ibm.com/developerworks/cn/java/j-lo-javaio/ 一. File类 file.createNewFile();file.del ...
- UML类图一
转自:http://blog.csdn.net/lovelion/article/details/7838679 类图用于描述系统中所包含的类以及它们之间的相互关系,帮助人们简化对系统的理解,它是系统 ...
- WordPress源代码压缩优化及常见问题的解决
先来看看效果: 意思就是让你的源代码看起来都挤在一起,这样如果别人想看你的源代码的话就不容易看懂了,(当然如果别人实在想看的话也可以通过某些软件的整理代码的功能来实现,比如IDEA的Ctrl+alt+ ...
- Python 从入门到入门基础练习十五题
**a) 6.成绩转换:编写一个学生成绩转换程序,用户输入百分制的学生成绩,成绩大于或等于60的输出"pass",否则输出"fail",成绩不四舍五入. a = ...