Spark Streaming 快速入门
一.SparkStreaming简介
SparkStreaming是核心Spark API的扩展,可以实现实时【准实时】数据流的可伸缩、高吞吐及容错处理。数据可以从像Kafka、Flume、HDFS/S3、Twitter或TCP套接字等许多来源获取。并且可以使用高级的算子例如,map,reduce,join和window等。最后,可以将处理后的数据推送到文件系统,数据库和实时仪表盘。实际上,它还可以在数据集上应用Spark的机器学习和图像处理算法。

在内部,它的工作方式如下:SparkStreaming接收实时输入数据流,并将数据分成微批处理,然后由Spark引擎进行处理,以分批生成最终结果流。

SparkStreaming提供了称为离散流或DStream的高级抽象,它表示连续的数据流。可以根据来自Kafka,Flume和Kinesis等来源的输入数据流来创建DStream,也可以通过对其它DStream应用高级的算子来转换成新的DStream。在内部,DStream为RDD的序列。
二.SparkStreaming特点
1.便于使用
Spark Streaming将Apache Spark的 语言集成API 引入流处理,使您可以像编写批处理作业一样编写流式作业。它支持Java,Scala和Python。
2.容错
Spark Streaming可以开箱即用,恢复丢失的工作和操作状态【例如滑动窗口】,而无需任何额外的代码。
3.Spark集成
将流式传输与批量交互式查询相结合。通过在Spark上运行,Spark Streaming允许您重复使用相同的代码进行批处理,将流加入历史数据,或者在流状态下运行即席查询。构建强大的交互式应用程序,而不只是分析。
4.部署选项
Spark Streaming可以从HDFS, Flume,Kafka, Twitter和 ZeroMQ读取数据 。您还可以定义自己的自定义数据源。
在Spark的独立集群模式 或其它受支持的集群资源管理器上运行Spark Streaming 。它还包括一个本地运行模式进行开发。在生产中,Spark Streaming使用ZooKeeper和HDFS实现高可用性。
三.代码实现
package big.data.analyse.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by zhen on 2017/11/19.
*/
object StreamingDemo {
Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("StreaingTest")
val ssc = new StreamingContext(conf,Seconds(10))
val lines = ssc.socketTextStream("master",) // 与nc端口对应
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word=>(word,1)).reduceByKey(_+_)
pairs.foreachRDD(row => row.foreach(println))
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
注意:还可以使用sparkContext创建StreamingContext,例如:new StreamingContext(sc, Seconds(1))
四.启动nc和执行程序
1.简介
NetCat简称nc,在网络工具中有“瑞士军刀”美誉,其有Windows和Linux的版本。因为它短小精悍、功能实用,被设计为一个简单、可靠的网络工具,可通过TCP或UDP协议传输读写数据。同时,它还是一个网络应用Debug分析器,因为它可以根据需要创建各种不同类型的网络连接。
2.启动

3.执行
./bin/run-example streaming.NetworkWordCount master 9999
五.执行结果
nc端:

Spark Streaming端:

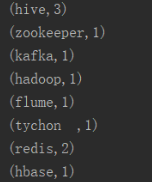
六.备注
1.streamingContext.start()表示开始接受数据并进行处理。
2.streamingContext.awaitTermination()表示等待停止使用【手动或由于任何错误】。
3.streamingContext.stop()表示可以是有手动停止。
4.一旦启动stremingContext,就无法设置新的流计算或将其添加到该流计算中。
5.streamingContext一旦停止,就无法重新启动。
6.streamingContext上的stop也会关闭sparkContext。要仅停止streamingContext,需要设置可选参数stopSparkContext为false。
7.只要在创建下一个streamingContext之前停止【不停止SparkContext】上一个StreamingContext,即可将SparkContext重新用于创建多个StreamingContext。
8.在本地模式时,请勿使用local或local[1]。这两种方式均意味着仅有一个线程用于运行本地任务。如果你使用的是基于接收器的输入DStream,则将使用单个线程来运行接收器,而不会留下线程来处理接收到的数据。因此,在本地运行时,请始终使用local[n],其中n>要运行的接收者数。
Spark Streaming 快速入门的更多相关文章
- 学习笔记:spark Streaming的入门
spark Streaming的入门 1.概述 spark streaming 是spark core api的一个扩展,可实现实时数据的可扩展,高吞吐量,容错流处理. 从上图可以看出,数据可以有很多 ...
- Spark2.x学习笔记:Spark SQL快速入门
Spark SQL快速入门 本地表 (1)准备数据 [root@node1 ~]# mkdir /tmp/data [root@node1 ~]# cat data/ml-1m/users.dat | ...
- Spark Streaming 编程入门指南
Spark Streaming 是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理.可以从许多数据源(例如Kafka,Flume,Kinesis或TCP sockets)中 ...
- Spark GraphX快速入门
GraphX是Spark用于图形并行计算的新组件.在较高的层次上,GraphX通过引入一个新的Graph抽象来扩展Spark RDD:一个定向的多图,其属性附加到每个定点和边.为了支持图计算,Grap ...
- Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN
快速入门 使用 Spark Shell 进行交互式分析 基础 Dataset 上的更多操作 缓存 独立的应用 快速跳转 本教程提供了如何使用 Spark 的快速入门介绍.首先通过运行 Spark 交互 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark Streaming入门
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文将帮助您使用基于HBase的Apache Spark Streaming.Spark Streaming是Spark API核心的一个扩 ...
- [转] Spark快速入门指南 – Spark安装与基础使用
[From] https://blog.csdn.net/w405722907/article/details/77943331 Spark快速入门指南 – Spark安装与基础使用 2017年09月 ...
- Spark快速入门 - Spark 1.6.0
Spark快速入门 - Spark 1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 快速入门(Quick Start) 本文简单介绍了Spark的使用方式.首 ...
随机推荐
- sun.misc jar包
一直以来Base64算法的加密解密都是使用sun.misc包下的BASE64Encoder及BASE64Decoder来进行的.但是这个类是sun公司的内部方法,并没有在Java API中公开过,不属 ...
- Java笔记(day12)
包: 对类文件进行分类管理:给类提供多层命名(名称)空间:写在程序文件的第一行:类名的全称是 包名.类名包也是一种封装形式: package protected必须是成为其子类,才能继承import导 ...
- c/c++ 动态库与静态库的制作和使用
静态库的用法 静态库的文件名 libxxx.a -->对应windows的.lib文件 做静态库的命令: ar rcs libxxx.a file1.o file2.o file.o 使用静态库 ...
- bootstap初识之css
老师的博客:https://www.cnblogs.com/liwenzhou/p/8214637.html bootstrap中文网:http://www.bootcss.com/ 官网:https ...
- brew 安装指定版本命令行工具 tmux 多版本实现
Homebrew 是 macOS 命令安装工具,其核心库里的命令行在 github homebrew-core 仓库上维护. 核心库命令大概有 5000 条左右,大部分的命令行工具只保留了最新版本的 ...
- C# 4.0 的 Visual Studio 2010 示例
C# 4.0 的 Visual Studio 2010 示例 我们将 C# 示例分为两种不同的类别: 语言示例 LINQ 示例 语言示例 语言示例帮助您熟悉各种 C# 语言功能.这些示例包含在 Lan ...
- Java相关面试题总结+答案(三)
[多线程] 35. 并行和并发有什么区别? 并行:多个处理器或多核处理器同时处理多个任务.(是真正的物理上的同时发生) 并发:多个任务在同一个 CPU 核上,按细分的时间片轮流(交替)执行,从逻辑上来 ...
- jquery删除内容是动态修改序号
如图,点击删除图标的时候要删除当前的一条记录,同时界面上的序号要动态的排列好 以下是html结构: jquery实现思路: 首先,需要获取到当前要删除盒子的序号$indexCur,然后遍历父盒子,取出 ...
- 今天筹备了一件大事:重学JS
最近在阮大神的博客上看到一篇文章,讲的是关于如何自学计算机技术,原文出自 Teach Yourself Computer Science.看完以后我明白自己的缺陷在哪里,基础不够牢固是我最大的问题. ...
- [开源]WinForm 控件使用总结
背景 都2019年了,还在用WinForm吗?哈哈,其实我也没在用,都是很多年前一些项目积累,所以代码写的有些屎,之所以开源出来,希望能给大家有所帮助,喜欢的话给 一个Star以资鼓励~: 具体代码: ...