[实现] 利用 Seq2Seq 预测句子后续字词 (Pytorch)
最近有个任务:利用 RNN 进行句子补全,即给定一个不完整的句子,预测其后续的字词。
本文使用了 Seq2Seq 模型,输入为5个中文字词,输出为一个中文字词。
目录
1.关于RNN
自被提出以来,循环神经网络(Recurrent Neural Networks,RNN) 在 NLP 领域取得了巨大的成功与广泛的应用,也由此催生出了许多新的变体与网络结构。由于网上有众多资料,在此我也只做简单的讲解了。
首先,讲讲 RNN cell 及其变体:
(1) vallina RNN cell
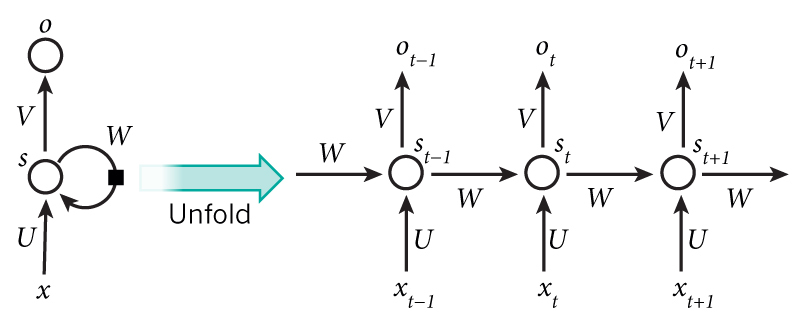
不同于常见的神经网络结构,RNN 的输入为时序输入,每一时刻的输入对神经元的隐状态产生影响,从而影响后续所有时刻的输出。
其中,隐藏层的公式如下所示:
O_{t} = g(V* S_t), S_t = f(U*X_t+W*S_{t-1})Ot=g(V∗St),St=f(U∗Xt+W∗St−1)
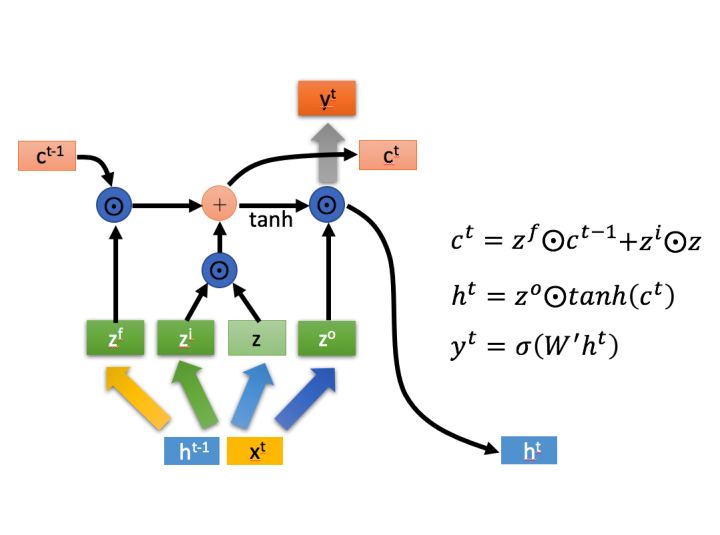
(2) LSTM cell
LSTM(Long short-term memory,长短期记忆)极大程度的解决了长序列训练过程中的梯度消失和梯度爆炸问题。
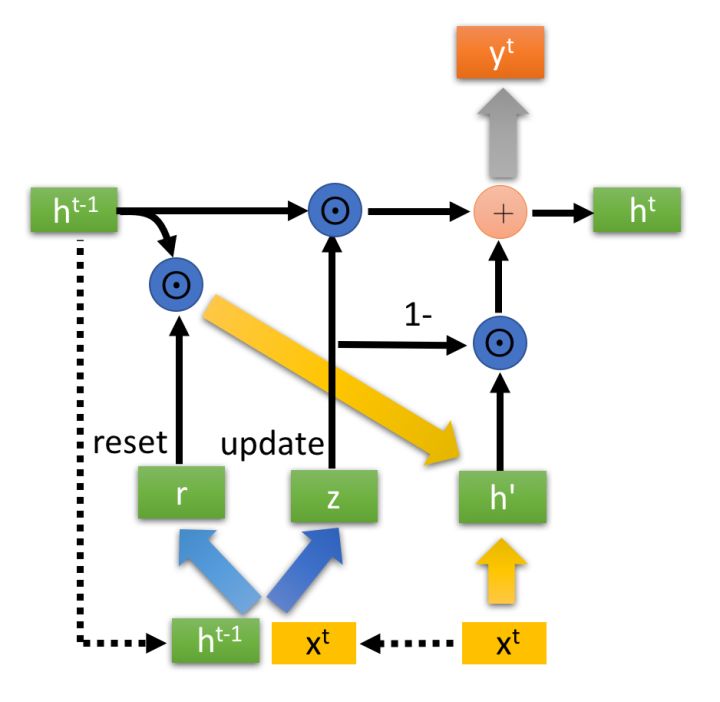
(3) GRU cell
GRU(Gate Recurrent Unit)与 LSTM 一样,也极大程度的解决了长序列训练过程中的梯度消失和梯度爆炸问题。但是,与 LSTM 相比,GRU 所需要的计算资源更小,往往工程实现时更倾向于使用 GRU。
接着,讲讲网络结构:
(1) 常见结构:
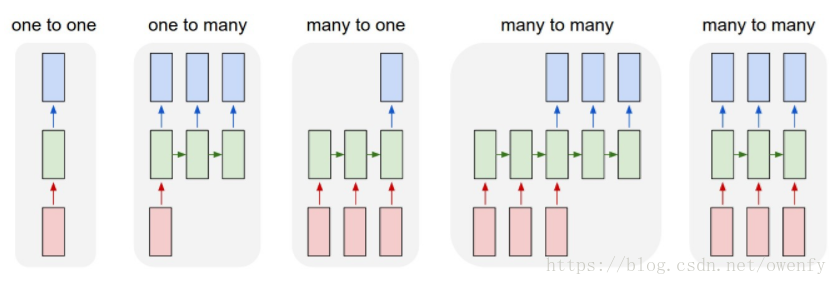
(2) Bi-directional RNN
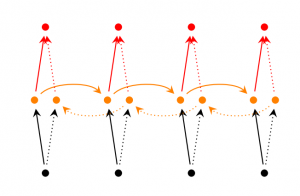
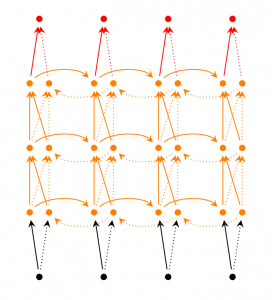
(3) Deep Bi-directional RNN
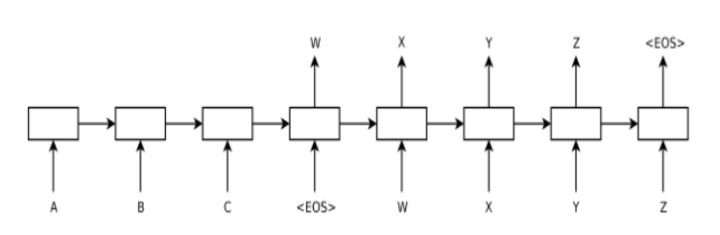
(4) Seq2Seq
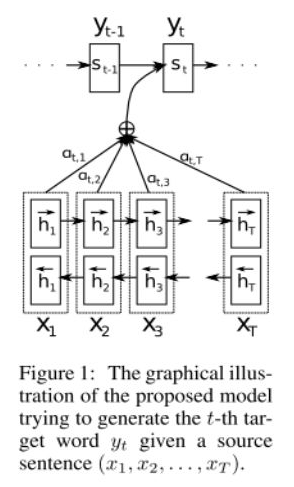
(5) Attention
参考资料:
2.语料预处理
由于这次使用的语料为中文语料,自然需要对其进行分词,并构造词典。
首先,收集所用的句子,利用 jieba 库,对每个句子进行分词,并将所得结果加入 word_set 中。
接着,对 word_set 中的所有字词构建统计词典。
代码:
import osimport jsonimport jiebaimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torch.autograd import Variableimport torchvisionimport torchvision.datasets as datasetsimport torchvision.transforms as transformsfrom torch.utils.data import DataLoader,Dataset# Set Hyper ParametersLR = 0.005EPOCH = 100BATCH_SIZE = 1Sentence_Num = 100Embedding_Dim = None# Bulid Vocabsentence_set = [] # 收集所用到的文本句子for index in range(Sentence_Num):
with open('../../Corpus/CAIL2018/'+str(index)+'.txt','r',encoding='UTF-8') as f:
sentence_set.append(f.read().replace('\n', '').replace('\r', '').replace(',', ' ').replace('。', ' ').replace(':', ' ').replace(' ', ' ').lower())
word_set = set() # 利用jieba库进行中文分词for sentence in sentence_set:
words = jieba.lcut(sentence)
word_set.update(words)
word_to_ix = {'SOS':0, 'EOS':1, 'UNK':2} # 'SOS': start of sentencexix_to_word = {0:'SOS', 1:'EOS', 2:'UNK'} # 'EOS': end of sentence
# 'UNK': unknown tokenfor word in word_set: # 构建词典,注意:word_to_ix用于对字词进行编号,ix_to_word用于将模型的输出转化为字词
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
ix_to_word[len(ix_to_word)] = word Embedding_Dim = len(word_to_ix)
with open('./Vocab.txt','w',encoding='UTF-8') as f: # 保存词典
for vocab in word_to_ix.items():
f.write(vocab[0]+' '+str(vocab[1])+'\n')
参考资料:
3.搭建数据集
由于所使用的中文文本并无数据集格式,故我们需要自己制作数据集。
注意,代码中的 bulid_one_hot 并非生成 one-hot 向量。这是因为模型中使用了 nn.Embedding() ,它会初始一个矩阵,相当于我们模型再训练过程中,顺便训练了一个 word embedding matrix。
至于如何使用该函数进行 word embedding ,大家可以查阅本小节的参考资料。
代码:
# Bulid Datasetdef bulid_one_hot(word,word_dict):
if word in word_dict:
return torch.LongTensor([word_dict[word]])
return torch.LongTensor([word_dict['UNK']]) class MyDataset(Dataset):
def __init__(self, words, labels, transform=None, target_transform=None):
self.words = words
self.labels = labels
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
words, labels = self.words[index], self.labels[index]
if self.transform is not None:
words = [self.transform(word) for word in words]
if self.target_transform is not None:
labels = self.target_transform(labels)
return words, labels def __len__(self):
return len(self.labels)train_words, train_labels, test_words, test_labels = [], [], [], []for i in range(int(0.9*Sentence_Num)):
sentence = sentence_set[i]
words = jieba.lcut(sentence)
words.insert(0,'SOS')
words.append('EOS')
words = [bulid_one_hot(word,word_to_ix) for word in words] for j in range(0,len(words),6):
if j+6 >= len(words):
break
train_words.append(words[j:j+5])
train_labels.append(words[j+5])
for i in range(int(0.9*Sentence_Num),Sentence_Num):
sentence = sentence_set[i]
words = jieba.lcut(sentence)
words.insert(0,'SOS')
words.append('EOS')
words = [bulid_one_hot(word,word_to_ix) for word in words]
for j in range(0,len(words),6):
if j+6 >= len(words):
break
test_words.append(words[j:j+5])
test_labels.append(words[j+5])
trans, target_trans = None, None # transforms.ToTensor(), transforms.ToTensor()train_set = MyDataset(train_words, train_labels, trans, target_trans)train_loader = DataLoader(dataset=train_set, batch_size=BATCH_SIZE)test_set = MyDataset(test_words, test_labels, trans, target_trans)test_loader = DataLoader(dataset=test_set, batch_size=BATCH_SIZE)
参考资料:
4.搭建模型
采用 GRU 结构构建 Seq2Seq 模型,其中,loss function 为 nn.CrossEntropyLoss(), optimizer 为 optim.SGD()。
注意,pytorch 中采用 nn.CrossEntropyLoss(),对输入与输出有格式要求,请查阅本小节的参考资料。
代码:
# Bulid Seq2Seq Modelclass Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size) # 将one-hot向量embedding为词向量
self.gru = nn.GRU(hidden_size, hidden_size) # GRU的hidden layer的size与词向量的size一样,并非必须 def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1) # RNN的输入格式为 (seq_len, batch, input_size)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden def initHidden(self):
return torch.zeros(1, 1, self.hidden_size) # 初始化Encoder的隐状态 class Decoder(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size) def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.out(output[0])
return output, hidden def initHidden(self):
return torch.zeros(1, 1, self.hidden_size)class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder def forward(self, inputs):
encoder_hidden = self.encoder.initHidden()
if torch.cuda.is_available():
encoder_hidden = encoder_hidden.cuda() # encode
for word in inputs:
encoder_out, encoder_hidden = self.encoder(word, encoder_hidden)
# decode
decoder_hidden = encoder_hidden
pred, decoder_hidden = self.decoder(inputs[-1], decoder_hidden)
return pred
encoder = Encoder(Embedding_Dim,1000)decoder = Decoder(Embedding_Dim,1000,Embedding_Dim)if torch.cuda.is_available():
encoder = encoder.cuda()
decoder = decoder.cuda()
seq2seq = Seq2Seq(encoder,decoder)if torch.cuda.is_available():
seq2seq = seq2seq.cuda()
# Bulid loss function and optimizer loss_func = nn.CrossEntropyLoss()#encoder_optimizer = optim.SGD(encoder.parameters(), lr=LR, momentum=0.9)#decoder_optimizer = optim.SGD(decoder.parameters(), lr=LR, momentum=0.9)seq2seq_optimizer = optim.SGD(seq2seq.parameters(), lr=LR, momentum=0.9)
参考资料:
5.训练模型
代码:
# Train Seq2Seq Modelfor epoch in range(EPOCH):
loss_sum = 0
for step, (inputs, labels) in enumerate(train_loader):
# encoder_hidden = encoder.initHidden()
label = torch.LongTensor((1,))
label[0] = int(labels.data.numpy()[0]) if torch.cuda.is_available():
inputs = [word.cuda() for word in inputs]
label = label.cuda()
# encoder_hidden = encoder_hidden.cuda()
# forward
pred = seq2seq(inputs)
loss = loss_func(pred,label)
# backward
seq2seq_optimizer.zero_grad()
loss.backward()
seq2seq_optimizer.step()
'''
for word in inputs:
encoder_out, encoder_hidden = encoder(word, encoder_hidden)
decoder_hidden = encoder_hidden
decoder_out, decoder_hidden = decoder(inputs[-1], decoder_hidden) loss = loss_func(decoder_out,label)
#backward
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
'''
loss_sum+= loss.data[0]
print('Epoch: %2d train loss: %.4f' % (epoch, loss_sum))
结果:
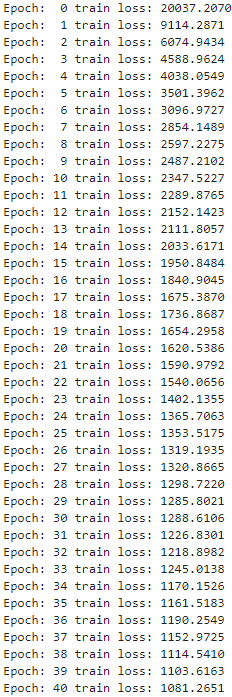
6.测试模型
代码:
# Test Seq2Seq Modelfor step, (inputs, labels) in enumerate(test_loader):
# encoder_hidden = encoder.initHidden()
label = torch.LongTensor((1,))
label[0] = int(labels.data.numpy()[0])
if torch.cuda.is_available():
inputs = [word.cuda() for word in inputs]
label = label.cuda()
# encoder_hidden = encoder_hidden.cuda()
decoder_output = seq2seq(inputs)
'''
# forward
for word in inputs:
encoder_out, encoder_hidden = encoder(word, encoder_hidden)
decoder_hidden = encoder_hidden
decoder_out, decoder_hidden = decoder(inputs[-1], decoder_hidden)
'''
# output
ans = ''
pred = ''
for word in inputs:
ix = word.cpu().data.numpy()[0][0]
ans+=ix_to_word[ix]
pred+=ix_to_word[ix] ans+=ix_to_word[int(labels.data.numpy()[0])]
pred+=ix_to_word[np.argmax(decoder_output.cpu().data.numpy())]
print('Answer: %s' % ans)
print('Prediction: %s' % pred)
结果:





上述结果是全部结果中效果不错的,可以观察到:虽然模型无法完全预测后续字词,但是能依照句子的前部分继续生成意思完整的句子。
不过,整体来看模型效果较差,我认为有以下几个原因:
所用文本数量少,仅用了100个句子进行训练。
构造的词库小,词典中仅有3000+字词,其中包括许多无意义的字词。
未对超参数进行微调。
7.保存/加载模型
往往大家保存和加载模型都是用的最简单的方法:torch.save(model,path),torch.load(path)。
这样的方法不仅将模型的参数保存了下来,还将模型的结构保存了下来。
有时我们只需要保存模型的参数,我们可以采用这样的方法:torch.save(model.state_dict(),path),torch.load_state_dict(torch.load(path))。
当然,还有许多复杂的方法可以选择,大家可以查阅参考资料进一步了解。
代码:
# Save Seq2Seq Model'''
torch.save(encoder.state_dict(),'../../Model/Seq2Seq/encoder_params.pkl')
torch.save(decoder.state_dict(),'../../Model/Seq2Seq/decoder_params.pkl') torch.save(encoder,'../../Model/Seq2Seq/encoder.pkl')
torch.save(decoder,'../../Model/Seq2Seq/decoder.pkl')
'''torch.save(seq2seq.state_dict(),'../../Model/Seq2Seq/seq2seq_params.pkl')torch.save(seq2seq,'../../Model/Seq2Seq/seq2seq.pkl')# Load Seq2Seq Model# encoder.load_state_dict(torch.load('../../Model/Seq2Seq/encoder_params.pkl'))# decoder.load_state_dict(torch.load('../../Model/Seq2Seq/decoder_params.pkl'))seq2seq = torch.load('../../Model/Seq2Seq/seq2seq.pkl')
[实现] 利用 Seq2Seq 预测句子后续字词 (Pytorch)的更多相关文章
- [实现] 利用 Seq2Seq 预测句子后续字词 (Pytorch)2
最近有个任务:利用 RNN 进行句子补全,即给定一个不完整的句子,预测其后续的字词.本文使用了 Seq2Seq 模型,输入为 5 个中文字词,输出为 1 个中文字词.目录 关于RNN 语料预处理 搭建 ...
- AI金融:利用LSTM预测股票每日最高价
第一部分:从RNN到LSTM 1.什么是RNN RNN全称循环神经网络(Recurrent Neural Networks),是用来处理序列数据的.在传统的神经网络模型中,从输入层到隐含层再到输出层, ...
- Tensorflow实例:利用LSTM预测股票每日最高价(一)
RNN与LSTM 这一部分主要涉及循环神经网络的理论,讲的可能会比较简略. 什么是RNN RNN全称循环神经网络(Recurrent Neural Networks),是用来处理序列数据的.在传统的神 ...
- 20岁少年小伙利用Python_SVM预测股票趋势月入十万!
在做数据预处理的时候,超额收益率是股票行业里的一个专有名词,指大于无风险投资的收益率,在我国无风险投资收益率即是银行定期存款. pycharm + anaconda3.6开发,涉及到的第三方库有p ...
- [Leetcode] Construct binary tree from inorder and postorder travesal 利用中序和后续遍历构造二叉树
Given inorder and postorder traversal of a tree, construct the binary tree. Note: You may assume th ...
- Pytorch系列教程-使用Seq2Seq网络和注意力机制进行机器翻译
前言 本系列教程为pytorch官网文档翻译.本文对应官网地址:https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutor ...
- 矩池云 | 利用LSTM框架实时预测比特币价格
温馨提示:本案例只作为学习研究用途,不构成投资建议. 比特币的价格数据是基于时间序列的,因此比特币的价格预测大多采用LSTM模型来实现. 长期短期记忆(LSTM)是一种特别适用于时间序列数据(或具有时 ...
- RNN、LSTM、Seq2Seq、Attention、Teacher forcing、Skip thought模型总结
RNN RNN的发源: 单层的神经网络(只有一个细胞,f(wx+b),只有输入,没有输出和hidden state) 多个神经细胞(增加细胞个数和hidden state,hidden是f(wx+b) ...
- 【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
http://spaces.ac.cn/archives/3924/ 关于字标注法 上一篇文章谈到了分词的字标注法.要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了.在我看来,字 ...
随机推荐
- CF 757 E Bash Plays with Functions —— 积性函数与质因数分解
题目:http://codeforces.com/contest/757/problem/E 首先,f0(n)=2m,其中 m 是 n 的质因数的种类数: 而且 因为这个函数和1卷积,所以是一个积性函 ...
- bzoj1296 [SCOI2009]粉刷匠——背包
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1296 对于不同木板之间,最终统计答案时做一个分组背包即可: 而要进行分组背包,就需要知道每个 ...
- 前端之html第二天
一.内容
- bzoj 4405: [wc2016]挑战NPC【带花树】
把每个筐子拆成3个,分别表示放0/1/2个,然后把这三个点两两连起来,每一个可以放在筐里的球都想这三个点连边. 这样可以发现,放0个球的时候,匹配数为1,放1个球的时候,匹配数为1,放2个球的时候,匹 ...
- P5071 [Ynoi2015]此时此刻的光辉
传送门 lxl大毒瘤 首先一个数的因子个数就是这个数的每个质因子的次数+1的积,然后考虑把每个数分解质因子,用莫队维护,然后我交上去就0分了 如果是上面那样的话,我们每一次移动指针的时间复杂度是O(这 ...
- 【先定一个小目标】dotnet core 命令详解
本篇博客来了解一下dotnet这个神奇的命令.我会依次对dotnet,dotnet new,dotnet restore,dotnet build,dotnet test,dotnet run,dot ...
- IOS编译报错:objc-class-ref in AppDelegate.o之解决方案 Xcode7
Undefined symbols for architecture x86_64: "_OBJC_CLASS_$_QQApiInterface", referenced from ...
- shell 2 解析
---- shell 3 /home/oracle/utility/macro/call_autopurge_arch.sh Description: Call purge archive log f ...
- jmeter(十四)解读聚合报告
一个每天1000万PV的网站需要什么样的性能去支撑呢?继续上一篇,下面我们就来计算一下,前面我们已经搞到了一票数据,但是这些数据的意义还没有说.技术是为业务服务的,下面就来说说怎么让些数据变得有意义. ...
- [转]windows azure How to use Blob storage from .NET
本文转自:http://azure.microsoft.com/en-us/documentation/articles/storage-dotnet-how-to-use-blobs/?rnd=1 ...