spark streaming 踩过的那些坑
- 系统背景
- spark streaming + Kafka高级API receiver
- 目前资源分配(现在系统比较稳定的资源分配),独立集群
--driver-memory 50G
--executor-memory 8G
--num-executors 11
--executor-cores 5
- 广播变量
1. 广播变量的初始化
1.1.executor端,存放广播变量的对象使用非静态,因为静态变量是属于类的,不能使用构造函数来初始化。在executor端使用静态的时候,它只是定义的时候的一个状态,而在初始化时设置的值取不到。而使用非静态的对象,其构造函数的初始化在driver端执行,故在集群可以取到广播变量的值。
2. 广播变量的释放
2.1.当filter增量为指定大小时,进行广播,虽然广播的是同一个对象,但是,广播的ID是不一样的,而且ID号越来越大,这说明对于广播来说,它并不是一个对象,而只是名字一样的不同对象,如果不对广播变量进行释放,将会导致executor端内存占用越来越大,而一直没有使用的广播变量,被进行GC,会导致GC开销超过使用上线,导致程序失败。
2.2.解决方案:这广播之前,先调用unpersist()方法,释放不用的广播变量
- 使用Kafka 的高级API receiver
1. 在使用receiver高级API时,由于receiver、partition、executor的分配关系,经常会导致某个executor任务比较繁重,进而影响整体处理速度
1.1.最好是一个receiver对应一个executor
2. 由于前段时间数据延迟比较严重,就想,能不能让所有executor的cores都去处理数据?所以调整receiver为原来的四倍,结果系统启动时,就一下冲上来非常大的数据量,导致系统崩溃,可见,receiver不仅跟partition的分配有关,还跟数据接收量有关
3. 在实际处理数据中,由于消息延迟,可以看到,有的topic处理速度快有的慢,原因分析如下:
3.1.跟消息的格式有关,有的是序列化文件,有的事json格式,而json的解析相对于比较慢
3.2.有时候拖累整个集群处理速度的,除了大量数据,还跟单条数据的大小有关
以下是程序跑挂的一些异常,和原因分析
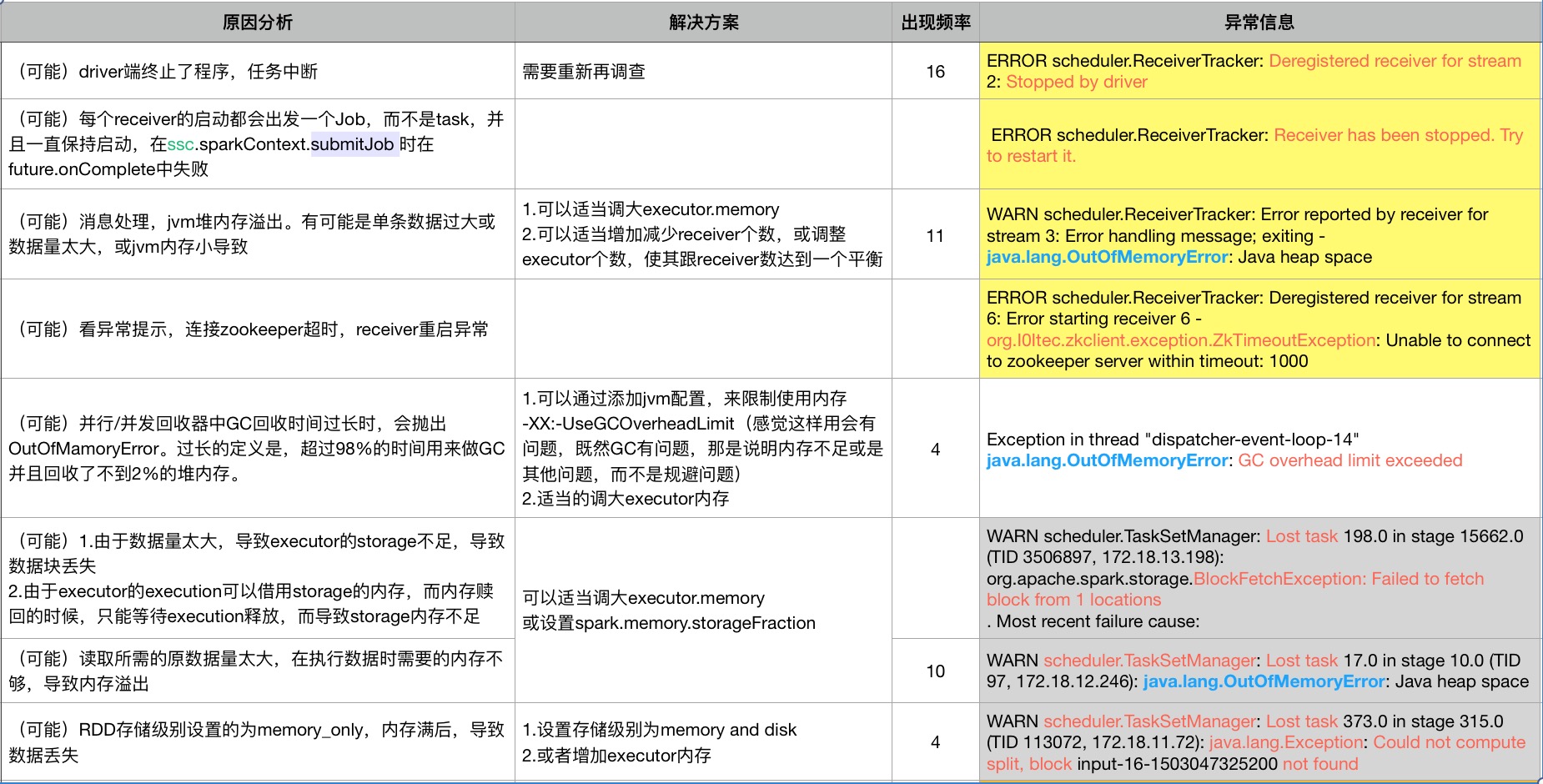

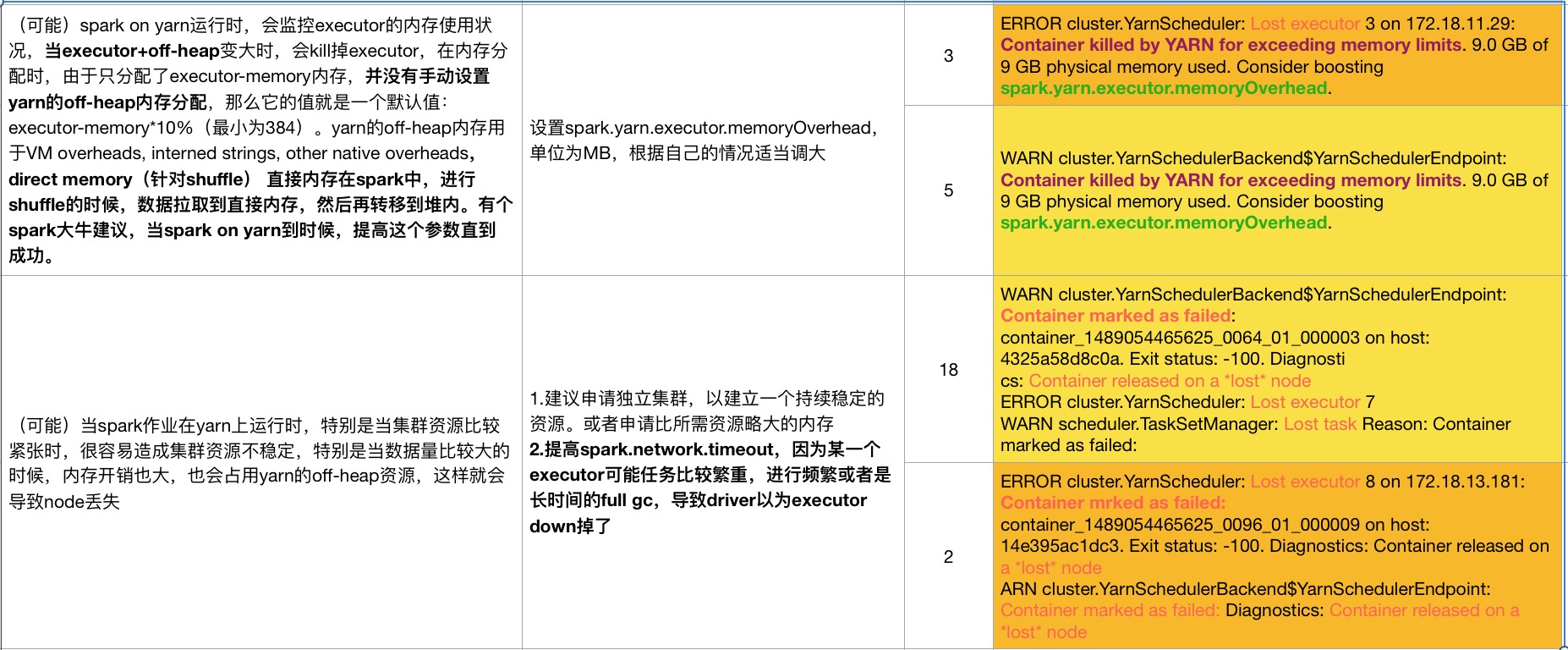
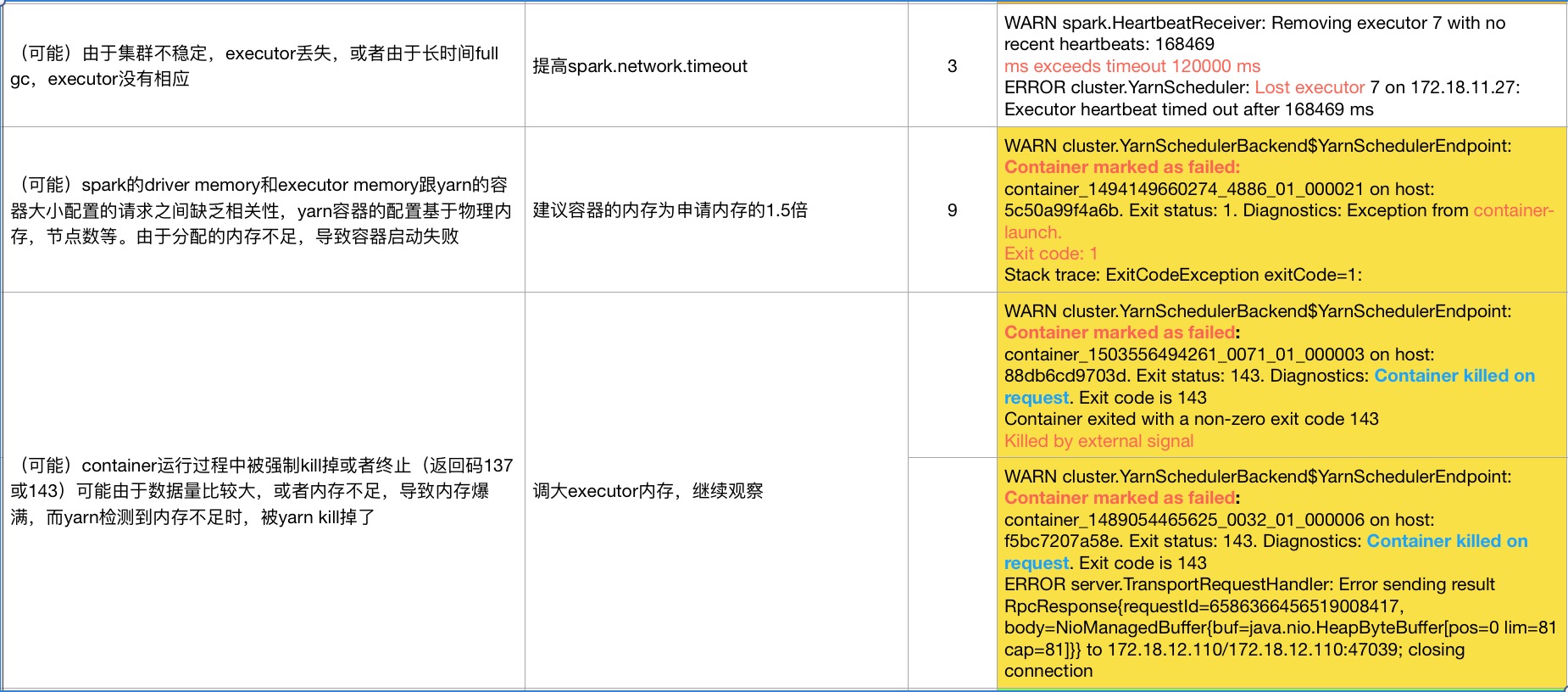


问题矫正:
第一张图片的,解决方案的倒数第二个, spark.memory.storageFraction(动态内存的百分比设置),应该为spark.storage.memoryFraction(静态内存分配的设置) (由于原文档丢失,导致无法修改文档。)
如果有什么问题,欢迎大家指出,共同探讨,共同进步
spark streaming 踩过的那些坑的更多相关文章
- spark streaming 消费 kafka入门采坑解决过程
kafka 服务相关的命令 # 开启kafka的服务器bin/kafka-server-start.sh -daemon config/server.properties &# 创建topic ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark踩坑记:Spark Streaming+kafka应用及调优
前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从k ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Spark streaming消费Kafka的正确姿势
前言 在游戏项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从kafka中不 ...
- Spark Streaming实时写入数据到HBase
一.概述 在实时应用之中,难免会遇到往NoSql数据如HBase中写入数据的情景.题主在工作中遇到如下情景,需要实时查询某个设备ID对应的账号ID数量.踩过的坑也挺多,举其中之一,如一开始选择使用NE ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- Redis上踩过的一些坑
来自: http://blog.csdn.net//chenleixing/article/details/50530419 上上周和同事(龙哥)参加了360组织的互联网技术训练营第三期,美团网的DB ...
- 【自动化】基于Spark streaming的SQL服务实时自动化运维
设计背景 spark thriftserver目前线上有10个实例,以往通过监控端口存活的方式很不准确,当出故障时进程不退出情况很多,而手动去查看日志再重启处理服务这个过程很低效,故设计利用Spark ...
随机推荐
- Windows查杀端口
Windows环境下当某个端口被占用时,通过netstat命令进行查询pid,然后通过taskkill命令杀进程. 一.查询占用端口号的进程信息 netstat -an|findstr 二.杀掉占用端 ...
- 备份字段(CATALOGUE_CODE)
update am_e4_entry set CATALOGUE_CODE_back=CATALOGUE_CODE; 还原字段 update am_e4_entry a set CATALOGUE_C ...
- 冒泡排序算法和简单选择排序算法的js实现
之前已经介绍过冒泡排序算法和简单选择排序算法和原理,现在有Js实现. 冒泡排序算法 let dat=[5, 8, 10, 3, 2, 18, 17, 9]; function bubbleSort(d ...
- Java语法基础-static关键字
static关键字说明 “static方法就是没有this的方法.在static方法内部不能调用非静态方法,反过来是可以的.而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用static方法.这 ...
- "码代码"微信号今日上线,为互联网同仁提供最前沿咨询
"码代码"微信号今日上线 关注即有好礼相送 三月,春意浓浓的日子,三月,属于女人的日子,而今天...... “2014年天空成人放送大赏”于5日晚举办颁奖典礼,“年度最佳AV女优” ...
- jQuery之Validation表单验证插件使用
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head> <met ...
- vue2.0版本指令v-if与v-show的区别
v-if: 判断是否加载,可以减轻服务器的压力,在需要时加载. v-show:调整css dispaly属性,可以使客户端操作更加流畅. v-if示例: <!DOCTYPE html> & ...
- 自制无线共享工具C++源代码及创建过程
// wire.cpp : 定义控制台应用程序的入口点.// #include <iostream>#include <string.h>using namespace std ...
- zabbix监控之grafana
zabbix监控之grafana
- Java常用工具类---image图片处理工具类、Json工具类
package com.jarvis.base.util; import java.io.ByteArrayInputStream;import java.io.ByteArrayOutputStre ...