孤立森林(IForest)代码实现及与PyOD对比
孤立森林(Isolation Forest)是经典的异常检测算法(论文网址)。本文用python对其进行实现,以及与常用的异常检测包PyOD进行效果对比。
简单来说,孤立森林(IForest)中包含若干孤立树(ITree),每颗树的创建是独立的,与其它树无关。假设数据集包含$n$个样本,每个样本都包含$m$个实数特征。在创建每颗孤立树时,根节点首先包含所有$n$个样本。对于每个节点,随机抽取一个特征,在该特征的最大与最小值之间随机取一数$p$,将小于$p$的样本划分在左子节点,将大于$p$的样本划分在右子节点。划分直到叶节点只包含一个样本,或达到树高为止,文中树高定义为$\text{ceil}(\log_2n)$。构建好IForest后的测试阶段,就是计算样本在每颗孤立树上被划分到叶节点的平均路径长度,作为计算异常分数的依据。显然,划分路径越短,异常的可能性越高。
实现代码如下:
#%% 函数定义
import torch
import numpy as np
import matplotlib.pyplot as plt def iTree(X:torch.Tensor, e, l):
# X数据集,e当前路径长,l树高最大值
if e >= l or len(X) <= 1:
return [0, len(X)] # 0 非叶子节点
q = np.random.randint(0, len(X[0]))
M, m = X[:, q].max(), X[:, q].min()
p = np.random.rand()*(M - m) + m
lchild = iTree(X[X[:,q] < p,:], e+1, l)
rchild = iTree(X[X[:,q] >= p,:], e+1, l)
return [1, lchild, rchild, q, p]
def c(n):
c = 0 if n == 1 else 2*(np.log(n-1)+0.5772156649) - (2*(n-1)/n)
return c
def PathLength(x, T, e):
# x样本,T树,e当前路径长
if T[0] == 0:
return e + c(T[1])
if x[T[3]] < T[4]:
return PathLength(x, T[1], e+1)
return PathLength(x, T[2], e+1)
def myIForest(X, t, psi):
# X训练集,t树数量,psi子采样
Ts = []
l = np.ceil(np.log(psi))
for i in range(t):
x_i = np.random.choice(range(len(X)), [psi], replace=False)
Ts .append(iTree(X[x_i], 0, l))
return Ts
def anomalyScore(x, Ts, psi):
length = 0
for T in Ts:
length += PathLength(x, T, 0)
length /= len(Ts)
s = 2**(-length/c(psi))
return s
#%% 定义正常分布、超参数、绘图矩阵
torch.manual_seed(0)
np.random.seed(0)
points = torch.randn([512, 2])
points[-80:] = torch.randn([80, 2])/3+4
t, psi = 100, 256
x, y = np.arange(-4.5, 5.5, 0.1), np.arange(-4.5, 5.5, 0.1)
X, Y = np.meshgrid(x, y)
XY = np.stack([X,Y], -1)
Z = np.zeros_like(X)
#%% 自定义孤立森林、异常值可视化、决策边界
myTs = myIForest(points, t, psi)
for i in range(XY.shape[0]):
for j in range(XY.shape[1]):
Z[i,j] = anomalyScore(XY[i, j], myTs, psi)
plt.plot(points[:,0],points[:,1], '.', c = "purple", alpha = 0.3)
plt.contourf(X,Y,Z)
cont = plt.contour(X,Y,Z, levels=[0.55])
plt.clabel(cont, inline=True, fontsize=10)
plt.show()
#%% pyOD孤立森林、异常值可视化、决策边界
from pyod.models.iforest import IForest
ifor = IForest(t, psi, 0.1, random_state=0)
ifor.fit(points)
h, w = XY.shape[0], XY.shape[1]
XY = XY.reshape(-1, 2)
Z = Z.reshape(-1)
Z = ifor.decision_function(XY)
Z = Z.reshape(h, w)
XY = XY.reshape(h,w,2) plt.plot(points[:,0],points[:,1], '.', c = "purple", alpha = 0.3)
plt.contourf(X,Y,Z)
cont = plt.contour(X,Y,Z, levels=[0]) #决策边界为0
plt.clabel(cont, inline=True, fontsize=10)
plt.show()
自定义孤立森林和PyOD定义的孤立森林可视化结果分别如下左右图所示:
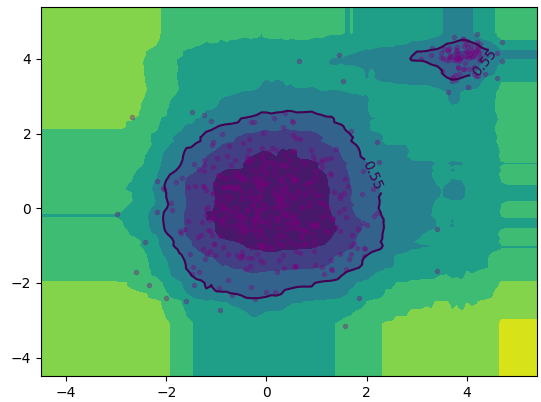 |
|
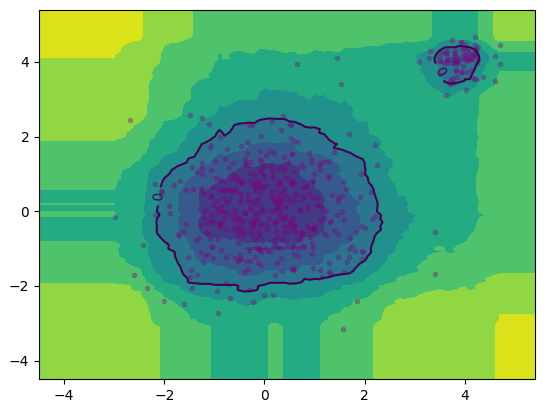
效果相似。其中自定义代码完全按照论文伪代码实现,使用二叉搜索树的平均失败搜索长度进行归一化,异常分数取值$(0,1)$。PyOD的异常分数取值似乎是$(-1,1)$,以0为区分阈值,即把自定义比例的正常样本的异常分数设置为小于0,大于0则为异常样本。此处设置10%为异常,90%正常。另外,由于自定义代码没有使用并行策略,运行时间会比PyOD长得多。
孤立森林(IForest)代码实现及与PyOD对比的更多相关文章
- 异常检测-基于孤立森林算法Isolation-based Anomaly Detection-1-论文学习
论文http://202.119.32.195/cache/10/03/cs.nju.edu.cn/da2d9bef3c4fd7d2d8c33947231d9708/tkdd11.pdf 1. INT ...
- 26.异常检测---孤立森林 | one-class SVM
novelty detection:当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外发现的新样本 outlier dection:当训练数据中包含离群点,模型训练时要匹配训练数据的中心样 ...
- 孤立森林(isolation forest)
1.简介 孤立森林(Isolation Forest)是另外一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或者基尼指数来选择. 在建树过程中 ...
- 异常值检测方法(Z-score,DBSCAN,孤立森林)
机器学习_深度学习_入门经典(博主永久免费教学视频系列) https://study.163.com/course/courseMain.htm?courseId=1006390023&sh ...
- 【异常检测】孤立森林(Isolation Forest)算法简介
简介 工作的过程中经常会遇到这样一个问题,在构建模型训练数据时,我们很难保证训练数据的纯净度,数据中往往会参杂很多被错误标记噪声数据,而数据的质量决定了最终模型性能的好坏.如果进行人工二次标记,成本会 ...
- 异常检测-基于孤立森林算法Isolation-based Anomaly Detection-2-实现
参考https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html#sklearn.en ...
- 孤立森林(Isolation Forest)
前言随着机器学习近年来的流行,尤其是深度学习的火热.机器学习算法在很多领域的应用越来越普遍.最近,我在一家广告公司做广告点击反作弊算法研究工作.想到了异常检测算法,并且上网调研发现有一个算法非常火爆, ...
- 异常检测-基于孤立森林算法Isolation-based Anomaly Detection-3-例子
参考:https://scikit-learn.org/stable/auto_examples/ensemble/plot_isolation_forest.html#sphx-glr-auto-e ...
- 使用VAE、CNN encoder+孤立森林检测ssl加密异常流的初探——真是一个忧伤的故事!!!
ssl payload取1024字节,然后使用VAE检测异常的ssl流. 代码如下: from sklearn.model_selection import train_test_split from ...
- K:树、二叉树与森林之间的转换及其相关代码实现
相关介绍: 二叉树是树的一种特殊形态,在二叉树中一个节点至多有左.右两个子节点,而在树中一个节点可以包含任意数目的子节点,对于森林,其是多棵树所组成的一个整体,树与树之间彼此相互独立,互不干扰,但其 ...
随机推荐
- ggml 简介
ggml 是一个用 C 和 C++ 编写.专注于 Transformer 架构模型推理的机器学习库.该项目完全开源,处于活跃的开发阶段,开发社区也在不断壮大.ggml 和 PyTorch.Tensor ...
- MRI roi图像合并
笔记来源:MRI roi的图像合并 dpabi小工具_哔哩哔哩_bilibili 1. 如果几个图像的维度不一致,需要先进行reslice 1)如何看图像的维度 以软件MRIcron为例, windo ...
- 立体视觉 StereoVision
双目相机 原理 [深度相机系列三]深度相机原理揭秘--双目立体视觉 StereoVision--立体视觉(1) StereoVision--立体视觉(2) StereoVision--立体视觉(3) ...
- Redis过期策略以及Redis的内存淘汰机制
此篇介绍了Redis过期策略以及Redis的内存淘汰机制,从内存淘汰的8种策略,如何开启内存淘汰策略到如何选择合适的淘汰策略,对Redis的内存淘汰机制做了全方位的阐述 如何高效的使用内存对于redi ...
- EF Core报错“Format of the initialization string does not conform to specification starting at index 0.”
问题分析: 今天在EF Core数据库迁移的过程中无意中发现此错误,我的项目仅仅复制黏贴了配置文件而已,自此发现是数据库配置文件json在作祟. 对比了下发现是.json文件没有被设置"复制 ...
- Go实现实时文件监控功能
一.使用库介绍 fsnotify 是 Go 语言中的一个库,用于监听文件系统的变更事件.它允许程序注册对文件系统事件的兴趣,并在这些事件发生时接收通知.fsnotify 主要用来监控目录下的文件变化, ...
- ZEGO 即构科技首发适配鸿蒙系统的 Express SDK 1.0 版本
2019年8月,华为在开发者大会上正式发布鸿蒙系统. HarmonyOS 鸿蒙系统是一款"面向未来".面向全场景(移动办公.运动健康.社交通信.媒体娱乐等)的分布式操作系统.在 ...
- 三牧校队训练题目 Solution
前置知识: 搜索 队列 栈 递归 (提高难度)记忆化搜索 T1:P1226 [模板]快速幂 暴力想法:\(a\times a\) 进行 \(b\) 次,每次 \(a\times a\mod p\). ...
- python08_05day
#!/usr/bin/python# -*- coding: UTF-8 -*-from _ast import Param #查询数据库'''import MySQLdb conn = MySQLd ...
- iOS生成ipa包的时候总是弹窗提示macOS想要使用系统钥匙串
最近新换了一台苹果电脑,性能不错,不过证书和描述文件需要重新配置,遇到了一系列奇怪的问题.在这里整理记录下来,希望能给其他人提供一些帮助.iOS生成ipa包的时候总是弹窗提示[macOS想要使用系统钥 ...